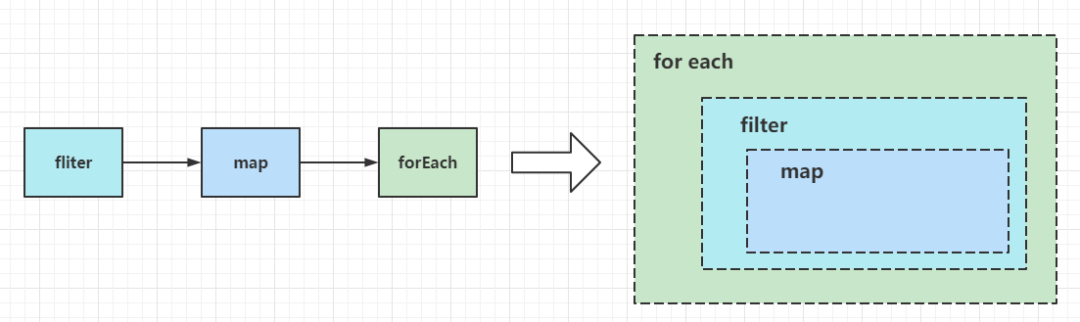
Stream是JDK1.8中首次引入的,距今已经过去了接近8年时间(JDK1.8正式版是2013年底发布的)。Stream的引入一方面极大地简化了某些开发场景,另一方面也可能降低了编码的可读性(确实有不少人说到Stream会降低代码的可读性,但是在笔者看来,熟练使用之后反而觉得代码的可读性提高了)。这篇文章会花巨量篇幅,详细分析Stream的底层实现原理,参考的源码是JDK11的源码,其他版本JDK可能不适用于本文中的源码展示和相关例子。
❝这篇文章花费了极多时间和精力梳理和编写,希望能够帮助到本文的读者
❞
Stream是JDK1.8引入的,如要需要JDK1.7或者以前的代码也能在JDK1.8或以上运行,那么Stream的引入必定不能在原来已经发布的接口方法进行修改,否则必定会因为兼容性问题导致老版本的接口实现无法在新版本中运行(方法签名出现异常),猜测是基于这个问题引入了接口默认方法,也就是default关键字。查看源码可以发现,ArrayList的超类Collection和Iterable分别添加了数个default方法:
// java.util.Collection部分源码
public interface Collection<E> extends Iterable<E> {
// 省略其他代码
@Override
default Spliterator<E> spliterator() {
return Spliterators.spliterator(this, 0);
}
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
default Stream<E> parallelStream() {
return StreamSupport.stream(spliterator(), true);
}
}
// java.lang.Iterable部分源码
public interface Iterable<T> {
// 省略其他代码
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}
default Spliterator<T> spliterator() {
return Spliterators.spliteratorUnknownSize(iterator(), 0);
}
}从直觉来看,这些新增的方法应该就是Stream实现的关键方法(后面会印证这不是直觉,而是查看源码的结果)。接口默认方法在使用上和实例方法一致,在实现上可以直接在接口方法中编写方法体,有点静态方法的意味,但是子类可以覆盖其实现(也就是接口默认方法在本接口中的实现有点像静态方法,可以被子类覆盖,使用上和实例方法一致)。这种实现方式,有可能是一种突破,也有可能是一种妥协,但是无论是妥协还是突破,都实现了向前兼容:
// JDK1.7中的java.lang.Iterable
public interface Iterable<T> {
Iterator<T> iterator();
}
// JDK1.7中的Iterable实现
public MyIterable<Long> implements Iterable<Long>{
public Iterator<Long> iterator(){
....
}
}如上,MyIterable在JDK1.7中定义,如果该类在JDK1.8中运行,那么调用其实例中的forEach()和spliterator()方法,相当于直接调用JDK1.8中的Iterable中的接口默认方法forEach()和spliterator()。当然受限于JDK版本,这里只能确保编译通过,旧功能正常使用,而无法在JDK1.7中使用Stream相关功能或者使用default方法关键字。总结这么多,就是想说明为什么使用JDK7开发和编译的代码可以在JDK8环境下运行。
Stream实现的基石是Spliterator,Spliterator是splitable iterator的缩写,意为"可拆分迭代器",用于遍历指定数据源(例如数组、集合或者IO Channel等)中的元素,在设计上充分考虑了串行和并行的场景。上一节提到了Collection存在接口默认方法spliterator(),此方法会生成一个Spliterator<E>实例,意为着「所有的集合子类都具备创建Spliterator实例的能力」。Stream的实现在设计上和Netty中的ChannelHandlerContext十分相似,本质是一个链表,「而Spliterator就是这个链表的Head节点」(Spliterator实例就是一个流实例的头节点,后面分析具体的源码时候再具体展开)。
接着看Spliterator接口定义的方法:
public interface Spliterator<T> {
// 暂时省略其他代码
boolean tryAdvance(Consumer<? super T> action);
default void forEachRemaining(Consumer<? super T> action) {
do { } while (tryAdvance(action));
}
Spliterator<T> trySplit();
long estimateSize();
default long getExactSizeIfKnown() {
return (characteristics() & SIZED) == 0 ? -1L : estimateSize();
}
int characteristics();
default boolean hasCharacteristics(int characteristics) {
return (characteristics() & characteristics) == characteristics;
}
default Comparator<? super T> getComparator() {
throw new IllegalStateException();
}
// 暂时省略其他代码
}「tryAdvance」
boolean tryAdvance(Consumer<? super T> action)Spliterator中存在剩余元素,则对其中的某个元素执行传入的action回调,并且返回true,否则返回false。如果Spliterator启用了ORDERED特性,会按照顺序(这里的顺序值可以类比为ArrayList中容器数组元素的下标,ArrayList中添加新元素是天然有序的,下标由零开始递增)处理下一个元素public static void main(String[] args) throws Exception {
List<Integer> list = new ArrayList<>();
list.add(2);
list.add(1);
list.add(3);
Spliterator<Integer> spliterator = list.stream().spliterator();
final AtomicInteger round = new AtomicInteger(1);
final AtomicInteger loop = new AtomicInteger(1);
while (spliterator.tryAdvance(num -> System.out.printf("第%d轮回调Action,值:%d\n", round.getAndIncrement(), num))) {
System.out.printf("第%d轮循环\n", loop.getAndIncrement());
}
}
// 控制台输出
第1轮回调Action,值:2
第1轮循环
第2轮回调Action,值:1
第2轮循环
第3轮回调Action,值:3
第3轮循环「forEachRemaining」
default void forEachRemaining(Consumer<? super T> action)Spliterator中存在剩余元素,则对其中的「所有剩余元素」在「当前线程中」执行传入的action回调。如果Spliterator启用了ORDERED特性,会按照顺序处理剩余所有元素。这是一个接口默认方法,方法体比较粗暴,直接是一个死循环包裹着tryAdvance()方法,直到false退出循环public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(2);
list.add(1);
list.add(3);
Spliterator<Integer> spliterator = list.stream().spliterator();
final AtomicInteger round = new AtomicInteger(1);
spliterator.forEachRemaining(num -> System.out.printf("第%d轮回调Action,值:%d\n", round.getAndIncrement(), num));
}
// 控制台输出
第1轮回调Action,值:2
第2轮回调Action,值:1
第3轮回调Action,值:3「rySplit」
Spliterator<T> trySplit()Spliterator是可分区(可分割)的,那么此方法将会返回一个全新的Spliterator实例,这个全新的Spliterator实例里面的元素不会被当前Spliterator实例中的元素覆盖(这里是直译了API注释,实际要表达的意思是:当前的Spliterator实例X是可分割的,trySplit()方法会分割X产生一个全新的Spliterator实例Y,原来的X所包含的元素(范围)也会收缩,类似于X = [a,b,c,d] => X = [a,b], Y = [c,d];如果当前的Spliterator实例X是不可分割的,此方法会返回NULL),「具体的分割算法由实现类决定」public static void main(String[] args) throws Exception {
List<Integer> list = new ArrayList<>();
list.add(2);
list.add(3);
list.add(4);
list.add(1);
Spliterator<Integer> first = list.stream().spliterator();
Spliterator<Integer> second = first.trySplit();
first.forEachRemaining(num -> {
System.out.printf("first spliterator item: %d\n", num);
});
second.forEachRemaining(num -> {
System.out.printf("second spliterator item: %d\n", num);
});
}
// 控制台输出
first spliterator item: 4
first spliterator item: 1
second spliterator item: 2
second spliterator item: 3「estimateSize」
long estimateSize()forEachRemaining()方法需要遍历的元素总量的估计值,如果样本个数是无限、计算成本过高或者未知,会直接返回Long.MAX_VALUEpublic static void main(String[] args) throws Exception {
List<Integer> list = new ArrayList<>();
list.add(2);
list.add(3);
list.add(4);
list.add(1);
Spliterator<Integer> spliterator = list.stream().spliterator();
System.out.println(spliterator.estimateSize());
}
// 控制台输出
4「getExactSizeIfKnown」
default long getExactSizeIfKnown()Spliterator具备SIZED特性(关于特性,下文再展开分析),那么直接调用estimateSize()方法,否则返回-1public static void main(String[] args) throws Exception {
List<Integer> list = new ArrayList<>();
list.add(2);
list.add(3);
list.add(4);
list.add(1);
Spliterator<Integer> spliterator = list.stream().spliterator();
System.out.println(spliterator.getExactSizeIfKnown());
}
// 控制台输出
4「int characteristics()」
long estimateSize()Spliterator具备的特性(集合),采用位运算,存储在32位整数中(关于特性,下文再展开分析)「hasCharacteristics」
default boolean hasCharacteristics(int characteristics)Spliterator是否具备传入的特性「getComparator」
default Comparator<? super T> getComparator()Spliterator具备SORTED特性,则需要返回一个Comparator实例;如果Spliterator中的元素是天然有序(例如元素实现了Comparable接口),则返回NULL;其他情况直接抛出IllegalStateException异常Spliterator#trySplit()可以把一个既有的Spliterator实例分割为两个Spliterator实例,笔者这里把这种方式称为Spliterator自分割,示意图如下:
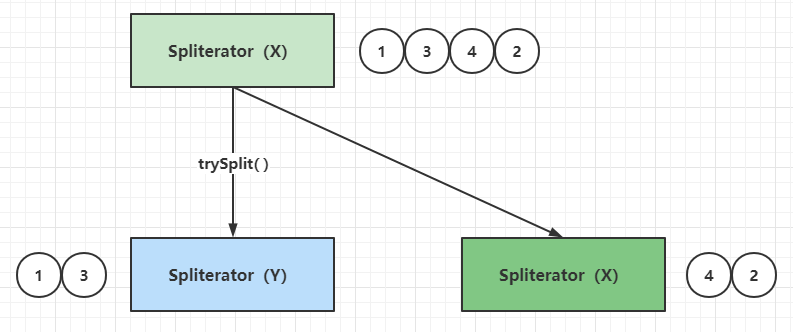
ArrayList而言,把底层数组「拷贝」并且进行分割,用上面的例子来说相当于X = [1,3,4,2] => X = [4,2], Y = [1,3],这样实现加上对于ArrayList中本身的元素容器数组,相当于多存了一份数据,显然不是十分合理ArrayList而言,由于元素容器数组天然有序,可以采用数组的索引(下标)进行分割,用上面的例子来说相当于X = 索引表[0,1,2,3] => X = 索引表[2,3], Y = 索引表[0,1],这种方式是共享底层容器数组,只对元素索引进行分割,实现上比较简单而且相对合理参看ArrayListSpliterator的源码,可以分析其分割算法实现:
// ArrayList#spliterator()
public Spliterator<E> spliterator() {
return new ArrayListSpliterator(0, -1, 0);
}
// ArrayList中内部类ArrayListSpliterator
final class ArrayListSpliterator implements Spliterator<E> {
// 当前的处理的元素索引值,其实是剩余元素的下边界值(包含),在tryAdvance()或者trySplit()方法中被修改,一般初始值为0
private int index;
// 栅栏,其实是元素索引值的上边界值(不包含),一般初始化的时候为-1,使用时具体值为元素索引值上边界加1
private int fence;
// 预期的修改次数,一般初始化值等于modCount
private int expectedModCount;
ArrayListSpliterator(int origin, int fence, int expectedModCount) {
this.index = origin;
this.fence = fence;
this.expectedModCount = expectedModCount;
}
// 获取元素索引值的上边界值,如果小于0,则把hi和fence都赋值为(ArrayList中的)size,expectedModCount赋值为(ArrayList中的)modCount,返回上边界值
// 这里注意if条件中有赋值语句hi = fence,也就是此方法调用过程中临时变量hi总是重新赋值为fence,fence是ArrayListSpliterator实例中的成员属性
private int getFence() {
int hi;
if ((hi = fence) < 0) {
expectedModCount = modCount;
hi = fence = size;
}
return hi;
}
// Spliterator自分割,这里采用了二分法
public ArrayListSpliterator trySplit() {
// hi等于当前ArrayListSpliterator实例中的fence变量,相当于获取剩余元素的上边界值
// lo等于当前ArrayListSpliterator实例中的index变量,相当于获取剩余元素的下边界值
// mid = (lo + hi) >>> 1,这里的无符号右移动1位运算相当于(lo + hi)/2
int hi = getFence(), lo = index, mid = (lo + hi) >>> 1;
// 当lo >= mid的时候为不可分割,返回NULL,否则,以index = lo,fence = mid和expectedModCount = expectedModCount创建一个新的ArrayListSpliterator
// 这里有个细节之处,在新的ArrayListSpliterator构造参数中,当前的index被重新赋值为index = mid,这一点容易看漏,老程序员都喜欢做这样的赋值简化
// lo >= mid返回NULL的时候,不会创建新的ArrayListSpliterator,也不会修改当前ArrayListSpliterator中的参数
return (lo >= mid) ? null : new ArrayListSpliterator(lo, index = mid, expectedModCount);
}
// tryAdvance实现
public boolean tryAdvance(Consumer<? super E> action) {
if (action == null)
throw new NullPointerException();
// 获取迭代的上下边界
int hi = getFence(), i = index;
// 由于前面分析下边界是包含关系,上边界是非包含关系,所以这里要i < hi而不是i <= hi
if (i < hi) {
index = i + 1;
// 这里的elementData来自ArrayList中,也就是前文经常提到的元素数组容器,这里是直接通过元素索引访问容器中的数据
@SuppressWarnings("unchecked") E e = (E)elementData[i];
// 对传入的Action进行回调
action.accept(e);
// 并发修改异常判断
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
return true;
}
return false;
}
// forEachRemaining实现,这里没有采用默认实现,而是完全覆盖实现一个新方法
public void forEachRemaining(Consumer<? super E> action) {
// 这里会新建所需的中间变量,i为index的中间变量,hi为fence的中间变量,mc为expectedModCount的中间变量
int i, hi, mc;
Object[] a;
if (action == null)
throw new NullPointerException();
// 判断容器数组存在性
if ((a = elementData) != null) {
// hi、fence和mc初始化
if ((hi = fence) < 0) {
mc = modCount;
hi = size;
}
else
mc = expectedModCount;
// 这里就是先做参数合法性校验,再遍历临时数组容器a中中[i,hi)的剩余元素对传入的Action进行回调
// 这里注意有一处隐蔽的赋值(index = hi),下界被赋值为上界,意味着每个ArrayListSpliterator实例只能调用一次forEachRemaining()方法
if ((i = index) >= 0 && (index = hi) <= a.length) {
for (; i < hi; ++i) {
@SuppressWarnings("unchecked") E e = (E) a[i];
action.accept(e);
}
// 这里校验ArrayList的modCount和mc是否一致,理论上在forEachRemaining()遍历期间,不能对数组容器进行元素的新增或者移除,一旦发生modCount更变会抛出异常
if (modCount == mc)
return;
}
}
throw new ConcurrentModificationException();
}
// 获取剩余元素估计值,就是用剩余元素索引上边界直接减去下边界
public long estimateSize() {
return getFence() - index;
}
// 具备ORDERED、SIZED和SUBSIZED特性
public int characteristics() {
return Spliterator.ORDERED | Spliterator.SIZED | Spliterator.SUBSIZED;
}
}在阅读源码的时候务必注意,老一辈的程序员有时候会采用比较「隐蔽」的赋值方式,笔者认为需要展开一下:
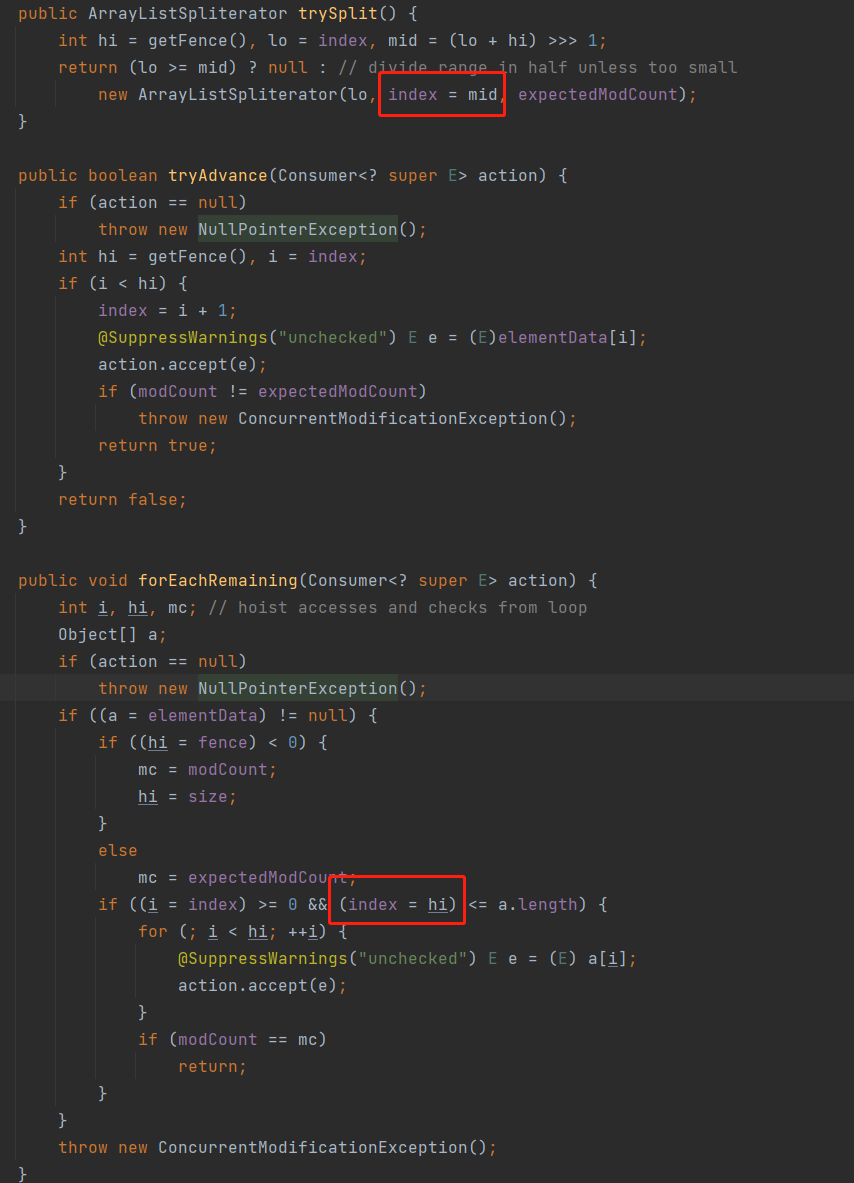
ArrayListSpliterator的时候,当前ArrayListSpliterator的index属性也被修改了,过程如下图:
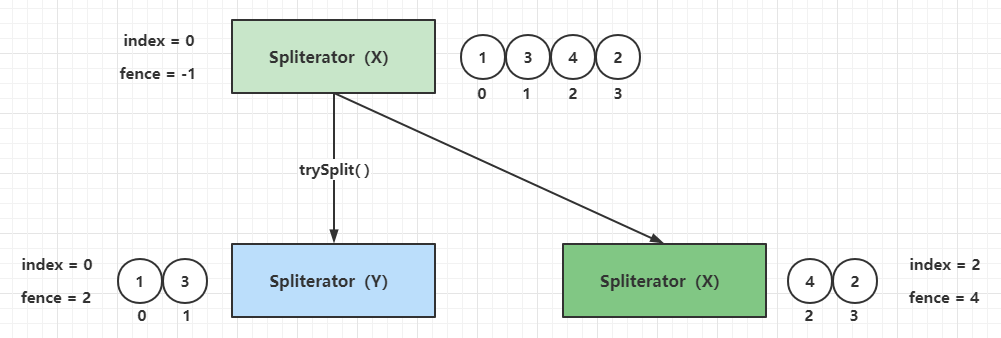
forEachRemaining()方法调用时候做参数校验,并且if分支里面把index(下边界值)赋值为hi(上边界值),「那么一个ArrayListSpliterator实例中的forEachRemaining()方法的遍历操作必定只会执行一次」。可以这样验证一下:
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(2);
list.add(1);
list.add(3);
Spliterator<Integer> spliterator = list.stream().spliterator();
final AtomicInteger round = new AtomicInteger(1);
spliterator.forEachRemaining(num -> System.out.printf("[第一次遍历forEachRemaining]第%d轮回调Action,值:%d\n", round.getAndIncrement(), num));
round.set(1);
spliterator.forEachRemaining(num -> System.out.printf("[第二次遍历forEachRemaining]第%d轮回调Action,值:%d\n", round.getAndIncrement(), num));
}
// 控制台输出
[第一次遍历forEachRemaining]第1轮回调Action,值:2
[第一次遍历forEachRemaining]第2轮回调Action,值:1
[第一次遍历forEachRemaining]第3轮回调Action,值:3对于ArrayListSpliterator的实现可以确认下面几点:
ArrayListSpliterator实例中的forEachRemaining()方法只能调用一次ArrayListSpliterator实例中的forEachRemaining()方法遍历元素的边界是[index, fence)ArrayListSpliterator自分割的时候,分割出来的新ArrayListSpliterator负责处理元素下标小的分段(类比fork的左分支),而原ArrayListSpliterator负责处理元素下标大的分段(类比fork的右分支)ArrayListSpliterator提供的estimateSize()方法得到的分段元素剩余数量是一个准确值如果把上面的例子继续分割,可以得到下面的过程:
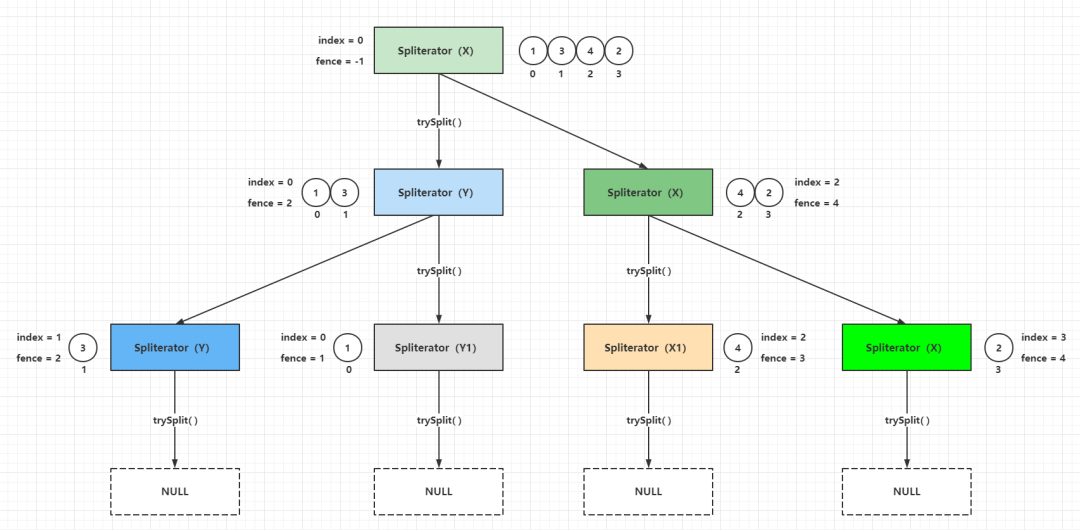
Spliterator自分割是并行流实现的基础」,并行流计算过程其实就是fork-join的处理过程,trySplit()方法的实现决定了fork任务的粒度,每个fork任务进行计算的时候是并发安全的,这一点由线程封闭(线程栈封闭)保证,每一个fork任务计算完成最后的结果再由单个线程进行join操作,才能得到正确的结果。下面的例子是求整数1 ~ 100的和:
public class ConcurrentSplitCalculateSum {
private static class ForkTask extends Thread {
private int result = 0;
private final Spliterator<Integer> spliterator;
private final CountDownLatch latch;
public ForkTask(Spliterator<Integer> spliterator,
CountDownLatch latch) {
this.spliterator = spliterator;
this.latch = latch;
}
@Override
public void run() {
long start = System.currentTimeMillis();
spliterator.forEachRemaining(num -> result = result + num);
long end = System.currentTimeMillis();
System.out.printf("线程[%s]完成计算任务,当前段计算结果:%d,耗时:%d ms\n",
Thread.currentThread().getName(), result, end - start);
latch.countDown();
}
public int result() {
return result;
}
}
private static int join(List<ForkTask> tasks) {
int result = 0;
for (ForkTask task : tasks) {
result = result + task.result();
}
return result;
}
private static final int THREAD_NUM = 4;
public static void main(String[] args) throws Exception {
List<Integer> source = new ArrayList<>();
for (int i = 1; i < 101; i++) {
source.add(i);
}
Spliterator<Integer> root = source.stream().spliterator();
List<Spliterator<Integer>> spliteratorList = new ArrayList<>();
Spliterator<Integer> x = root.trySplit();
Spliterator<Integer> y = x.trySplit();
Spliterator<Integer> z = root.trySplit();
spliteratorList.add(root);
spliteratorList.add(x);
spliteratorList.add(y);
spliteratorList.add(z);
List<ForkTask> tasks = new ArrayList<>();
CountDownLatch latch = new CountDownLatch(THREAD_NUM);
for (int i = 0; i < THREAD_NUM; i++) {
ForkTask task = new ForkTask(spliteratorList.get(i), latch);
task.setName("fork-task-" + (i + 1));
tasks.add(task);
}
tasks.forEach(Thread::start);
latch.await();
int result = join(tasks);
System.out.println("最终计算结果为:" + result);
}
}
// 控制台输出结果
线程[fork-task-4]完成计算任务,当前段计算结果:1575,耗时:0 ms
线程[fork-task-2]完成计算任务,当前段计算结果:950,耗时:1 ms
线程[fork-task-3]完成计算任务,当前段计算结果:325,耗时:1 ms
线程[fork-task-1]完成计算任务,当前段计算结果:2200,耗时:1 ms
最终计算结果为:5050当然,最终并行流的计算用到了ForkJoinPool,并不像这个例子中这么粗暴地进行异步执行。关于并行流的实现下文会详细分析。
某一个Spliterator实例支持的特性由方法characteristics()决定,这个方法返回的是一个32位数值,实际使用中会展开为bit数组,所有的特性分配在不同的位上,而hasCharacteristics(int characteristics)就是通过输入的具体特性值通过位运算判断该特性是否存在于characteristics()中。下面简化characteristics为byte分析一下这个技巧:
假设:byte characteristics() => 也就是最多8个位用于表示特性集合,如果每个位只表示一种特性,那么可以总共表示8种特性
特性X:0000 0001
特性Y:0000 0010
以此类推
假设:characteristics = X | Y = 0000 0001 | 0000 0010 = 0000 0011
那么:characteristics & X = 0000 0011 & 0000 0001 = 0000 0001
判断characteristics是否包含X:(characteristics & X) == X上面推断的过程就是Spliterator中特性判断方法的处理逻辑:
// 返回特性集合
int characteristics();
// 基于位运算判断特性集合中是否存在输入的特性
default boolean hasCharacteristics(int characteristics) {
return (characteristics() & characteristics) == characteristics;
}这里可以验证一下:
public class CharacteristicsCheck {
public static void main(String[] args) {
System.out.printf("是否存在ORDERED特性:%s\n", hasCharacteristics(Spliterator.ORDERED));
System.out.printf("是否存在SIZED特性:%s\n", hasCharacteristics(Spliterator.SIZED));
System.out.printf("是否存在DISTINCT特性:%s\n", hasCharacteristics(Spliterator.DISTINCT));
}
private static int characteristics() {
return Spliterator.ORDERED | Spliterator.SIZED | Spliterator.SORTED;
}
private static boolean hasCharacteristics(int characteristics) {
return (characteristics() & characteristics) == characteristics;
}
}
// 控制台输出
是否存在ORDERED特性:true
是否存在SIZED特性:true
是否存在DISTINCT特性:false目前Spliterator支持的特性一共有8个,如下:
| 特性 | 十六进制值 | 二进制值 | 功能 |
|---|---|---|---|
| DISTINCT | 0x00000001 | 0000 0000 0000 0001 | 去重,例如对于每对要处理的元素(x,y),使用!x.equals(y)比较,Spliterator中去重实际上基于Set处理 |
| ORDERED | 0x00000010 | 0000 0000 0001 0000 | (元素)顺序处理,可以理解为trySplit()、tryAdvance()和forEachRemaining()方法对所有元素处理都保证一个严格的前缀顺序 |
| SORTED | 0x00000004 | 0000 0000 0000 0100 | 排序,元素使用getComparator()方法提供的Comparator进行排序,如果定义了SORTED特性,则必须定义ORDERED特性 |
| SIZED | 0x00000040 | 0000 0000 0100 0000 | (元素)预估数量,启用此特性,那么Spliterator拆分或者迭代之前,estimateSize()返回的是元素的准确数量 |
| NONNULL | 0x00000040 | 0000 0001 0000 0000 | (元素)非NULL,数据源保证Spliterator需要处理的元素不能为NULL,最常用于并发容器中的集合、队列和Map |
| IMMUTABLE | 0x00000400 | 0000 0100 0000 0000 | (元素)不可变,数据源不可被修改,也就是处理过程中元素不能被添加、替换和移除(更新属性是允许的) |
| CONCURRENT | 0x00001000 | 0001 0000 0000 0000 | (元素源)的修改是并发安全的,意味着多线程在数据源中添加、替换或者移除元素在不需要额外的同步条件下是并发安全的 |
| SUBSIZED | 0x00004000 | 0100 0000 0000 0000 | (子Spliterator元素)预估数量,启用此特性,意味着通过trySplit()方法分割出来的所有子Spliterator(当前Spliterator分割后也属于子Spliterator)都启用SIZED特性 |
❝细心点观察可以发现:所有特性采用32位的整数存储,使用了隔1位存储的策略,位下标和特性的映射是:(0 => DISTINCT)、(3 => SORTED)、(5 => ORDERED)、(7=> SIZED)、(9 => NONNULL)、(11 => IMMUTABLE)、(13 => CONCURRENT)、(15 => SUBSIZED)
❞
所有特性的功能这里只概括了核心的定义,还有一些小字或者特例描述限于篇幅没有完全加上,这一点可以参考具体的源码中的API注释。这些特性最终会转化为StreamOpFlag再提供给Stream中的操作判断使用,由于StreamOpFlag会更加复杂,下文再进行详细分析。
由于流的实现是高度抽象的工程代码,所以在源码阅读上会有点困难。整个体系涉及到大量的接口、类和枚举,如下图:

IntStream、LongStream和DoubleStream都是特化类型,分别针对于Integer、Long和Double三种类型,其他引用类型构建的Pipeline都是ReferencePipeline实例,因此笔者认为,ReferencePipeline(引用类型流水线)是流的核心数据结构,下面会基于ReferencePipeline的实现做深入分析。
❝注意,这一小节很烧脑,也有可能是笔者的位操作不怎么熟练,这篇文章大部分时间消耗在这一小节
❞
StreamOpFlag是一个枚举,功能是存储Stream和操作的标志(Flags corresponding to characteristics of streams and operations,下称Stream标志),这些标志提供给Stream框架用于控制、定制化和优化计算。Stream标志可以用于描述与流相关联的若干不同实体的特征,这些实体包括:Stream的源、Stream的中间操作(Op)和Stream的终端操作(Terminal Op)。但是并非所有的Stream标志对所有的Stream实体都具备意义,目前这些实体和标志映射关系如下:
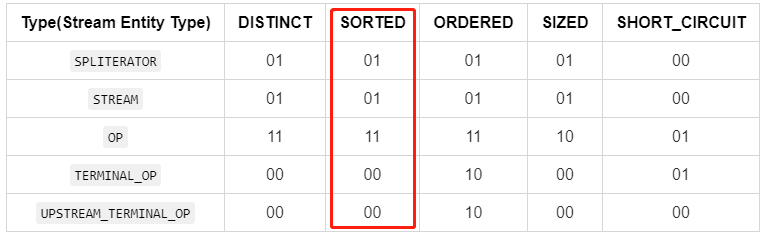
| Type(Stream Entity Type) | DISTINCT | SORTED | ORDERED | SIZED | SHORT_CIRCUIT |
|---|---|---|---|---|---|
| SPLITERATOR | 01 | 01 | 01 | ||
| STREAM | 01 | 01 | 01 | 01 | 00 |
| OP | 11 | 11 | 11 | 10 | 01 |
| TERMINAL_OP | 00 | 00 | 10 | 00 | 01 |
| UPSTREAM_TERMINAL_OP | 00 | 00 | 10 | 00 | 00 |
其中:
0值表示绝对不会是某个类型的标志StreamOpFlag的顶部注释中还有一个表格如下:
| - | DISTINCT | SORTED | ORDERED | SIZED | SHORT_CIRCUIT |
|---|---|---|---|---|---|
| Stream source(Stream的源) | Y | Y | Y | Y | N |
| Intermediate operation(中间操作) | PCI | PCI | PCI | PC | PI |
| Terminal operation(终结操作) | N | N | PC | N | PI |
标记 -> 含义:
Y:允许N:非法P:保留C:清除I:注入PCI:可以保留、清除或者注入PC:可以保留或者清除PI:可以保留或者注入两个表格其实是在描述同一个结论,可以相互对照和理解,但是「最终实现参照于第一个表的定义」。注意一点:这里的preserved(P)表示保留的意思,如果Stream实体某个标志被赋值为preserved,意味着该实体可以使用此标志代表的特性。例如此小节第一个表格中的OP的DISTINCT、SORTED和ORDERED都赋值为11(preserved),意味着OP类型的实体允许使用去重、自然排序和顺序处理特性。回到源码部分,先看StreamOpFlag的核心属性和构造器:
enum StreamOpFlag {
// 暂时忽略其他代码
// 类型枚举,Stream相关实体类型
enum Type {
// SPLITERATOR类型,关联所有和Spliterator相关的特性
SPLITERATOR,
// STREAM类型,关联所有和Stream相关的标志
STREAM,
// STREAM类型,关联所有和Stream中间操作相关的标志
OP,
// TERMINAL_OP类型,关联所有和Stream终结操作相关的标志
TERMINAL_OP,
// UPSTREAM_TERMINAL_OP类型,关联所有在最后一个有状态操作边界上游传播的终止操作标志
// 这个类型的意义直译有点拗口,不过实际上在JDK11源码中,这个类型没有被流相关功能引用,暂时可以忽略
UPSTREAM_TERMINAL_OP
}
// 设置/注入标志的bit模式,二进制数0001,十进制数1
private static final int SET_BITS = 0b01;
// 清除标志的bit模式,二进制数0010,十进制数2
private static final int CLEAR_BITS = 0b10;
// 保留标志的bit模式,二进制数0011,十进制数3
private static final int PRESERVE_BITS = 0b11;
// 掩码建造器工厂方法,注意这个方法用于实例化MaskBuilder
private static MaskBuilder set(Type t) {
return new MaskBuilder(new EnumMap<>(Type.class)).set(t);
}
// 私有静态内部类,掩码建造器,里面的map由上面的set(Type t)方法得知是EnumMap实例
private static class MaskBuilder {
// Type -> SET_BITS|CLEAR_BITS|PRESERVE_BITS|0
final Map<Type, Integer> map;
MaskBuilder(Map<Type, Integer> map) {
this.map = map;
}
// 设置类型和对应的掩码
MaskBuilder mask(Type t, Integer i) {
map.put(t, i);
return this;
}
// 对类型添加/inject
MaskBuilder set(Type t) {
return mask(t, SET_BITS);
}
MaskBuilder clear(Type t) {
return mask(t, CLEAR_BITS);
}
MaskBuilder setAndClear(Type t) {
return mask(t, PRESERVE_BITS);
}
// 这里的build方法对于类型中的NULL掩码填充为0,然后把map返回
Map<Type, Integer> build() {
for (Type t : Type.values()) {
map.putIfAbsent(t, 0b00);
}
return map;
}
}
// 类型->掩码映射
private final Map<Type, Integer> maskTable;
// bit的起始偏移量,控制下面set、clear和preserve的起始偏移量
private final int bitPosition;
// set/inject的bit set(map),其实准确来说应该是一个表示set/inject的bit map
private final int set;
// clear的bit set(map),其实准确来说应该是一个表示clear的bit map
private final int clear;
// preserve的bit set(map),其实准确来说应该是一个表示preserve的bit map
private final int preserve;
private StreamOpFlag(int position, MaskBuilder maskBuilder) {
// 这里会基于MaskBuilder初始化内部的EnumMap
this.maskTable = maskBuilder.build();
// Two bits per flag <= 这里会把入参position放大一倍
position *= 2;
this.bitPosition = position;
this.set = SET_BITS << position; // 设置/注入标志的bit模式左移2倍position
this.clear = CLEAR_BITS << position; // 清除标志的bit模式左移2倍position
this.preserve = PRESERVE_BITS << position; // 保留标志的bit模式左移2倍position
}
// 省略中间一些方法
// 下面这些静态变量就是直接返回标志对应的set/injec、清除和保留的bit map
/**
* The bit value to set or inject {@link #DISTINCT}.
*/
static final int IS_DISTINCT = DISTINCT.set;
/**
* The bit value to clear {@link #DISTINCT}.
*/
static final int NOT_DISTINCT = DISTINCT.clear;
/**
* The bit value to set or inject {@link #SORTED}.
*/
static final int IS_SORTED = SORTED.set;
/**
* The bit value to clear {@link #SORTED}.
*/
static final int NOT_SORTED = SORTED.clear;
/**
* The bit value to set or inject {@link #ORDERED}.
*/
static final int IS_ORDERED = ORDERED.set;
/**
* The bit value to clear {@link #ORDERED}.
*/
static final int NOT_ORDERED = ORDERED.clear;
/**
* The bit value to set {@link #SIZED}.
*/
static final int IS_SIZED = SIZED.set;
/**
* The bit value to clear {@link #SIZED}.
*/
static final int NOT_SIZED = SIZED.clear;
/**
* The bit value to inject {@link #SHORT_CIRCUIT}.
*/
static final int IS_SHORT_CIRCUIT = SHORT_CIRCUIT.set;
}又因为StreamOpFlag是一个枚举,一个枚举成员是一个独立的标志,而一个标志会对多个Stream实体类型产生作用,所以它的一个成员描述的是上面实体和标志映射关系的一个列(竖着看):
// 纵向看
DISTINCT Flag:
maskTable: {
SPLITERATOR: 0000 0001,
STREAM: 0000 0001,
OP: 0000 0011,
TERMINAL_OP: 0000 0000,
UPSTREAM_TERMINAL_OP: 0000 0000
}
position(input): 0
bitPosition: 0
set: 1 => 0000 0000 0000 0000 0000 0000 0000 0001
clear: 2 => 0000 0000 0000 0000 0000 0000 0000 0010
preserve: 3 => 0000 0000 0000 0000 0000 0000 0000 0011
SORTED Flag:
maskTable: {
SPLITERATOR: 0000 0001,
STREAM: 0000 0001,
OP: 0000 0011,
TERMINAL_OP: 0000 0000,
UPSTREAM_TERMINAL_OP: 0000 0000
}
position(input): 1
bitPosition: 2
set: 4 => 0000 0000 0000 0000 0000 0000 0000 0100
clear: 8 => 0000 0000 0000 0000 0000 0000 0000 1000
preserve: 12 => 0000 0000 0000 0000 0000 0000 0000 1100
ORDERED Flag:
maskTable: {
SPLITERATOR: 0000 0001,
STREAM: 0000 0001,
OP: 0000 0011,
TERMINAL_OP: 0000 0010,
UPSTREAM_TERMINAL_OP: 0000 0010
}
position(input): 2
bitPosition: 4
set: 16 => 0000 0000 0000 0000 0000 0000 0001 0000
clear: 32 => 0000 0000 0000 0000 0000 0000 0010 0000
preserve: 48 => 0000 0000 0000 0000 0000 0000 0011 0000
SIZED Flag:
maskTable: {
SPLITERATOR: 0000 0001,
STREAM: 0000 0001,
OP: 0000 0010,
TERMINAL_OP: 0000 0000,
UPSTREAM_TERMINAL_OP: 0000 0000
}
position(input): 3
bitPosition: 6
set: 64 => 0000 0000 0000 0000 0000 0000 0100 0000
clear: 128 => 0000 0000 0000 0000 0000 0000 1000 0000
preserve: 192 => 0000 0000 0000 0000 0000 0000 1100 0000
SHORT_CIRCUIT Flag:
maskTable: {
SPLITERATOR: 0000 0000,
STREAM: 0000 0000,
OP: 0000 0001,
TERMINAL_OP: 0000 0001,
UPSTREAM_TERMINAL_OP: 0000 0000
}
position(input): 12
bitPosition: 24
set: 16777216 => 0000 0001 0000 0000 0000 0000 0000 0000
clear: 33554432 => 0000 0010 0000 0000 0000 0000 0000 0000
preserve: 50331648 => 0000 0011 0000 0000 0000 0000 0000 0000接着就用到按位与(&)和按位或(|)的操作,假设A = 0001、B = 0010、C = 1000,那么:
A|B = A | B = 0001 | 0010 = 0011(按位或,1|0=1, 0|1=1,0|0 =0,1|1=1)A&B = A & B = 0001 | 0010 = 0000(按位与,1|0=0, 0|1=0,0|0 =0,1|1=1)MASK = A | B | C = 0001 | 0010 | 1000 = 1011A|B是否包含A的条件为:A == (A|B & A)MASK是否包含A的条件为:A == MASK & A这里把StreamOpFlag中的枚举套用进去分析:
static int DISTINCT_SET = 0b0001;
static int SORTED_CLEAR = 0b1000;
public static void main(String[] args) throws Exception {
// 支持DISTINCT标志和不支持SORTED标志
int flags = DISTINCT_SET | SORTED_CLEAR;
System.out.println(Integer.toBinaryString(flags));
System.out.printf("支持DISTINCT标志:%s\n", DISTINCT_SET == (DISTINCT_SET & flags));
System.out.printf("不支持SORTED标志:%s\n", SORTED_CLEAR == (SORTED_CLEAR & flags));
}
// 控制台输出
1001
支持DISTINCT标志:true
不支持SORTED标志:true由于StreamOpFlag的修饰符是默认,不能直接使用,可以把它的代码拷贝出来修改包名验证里面的功能:
public static void main(String[] args) {
int flags = StreamOpFlag.DISTINCT.set | StreamOpFlag.SORTED.clear;
System.out.println(StreamOpFlag.DISTINCT.set == (StreamOpFlag.DISTINCT.set & flags));
System.out.println(StreamOpFlag.SORTED.clear == (StreamOpFlag.SORTED.clear & flags));
}
// 输出
true
true下面这些方法就是基于这些运算特性而定义的:
enum StreamOpFlag {
// 暂时忽略其他代码
// 返回当前StreamOpFlag的set/inject的bit map
int set() {
return set;
}
// 返回当前StreamOpFlag的清除的bit map
int clear() {
return clear;
}
// 这里判断当前StreamOpFlag类型->标记映射中Stream类型的标记,如果大于0说明不是初始化状态,那么当前StreamOpFlag就是Stream相关的标志
boolean isStreamFlag() {
return maskTable.get(Type.STREAM) > 0;
}
// 这里就用到按位与判断输入的flags中是否设置当前StreamOpFlag(StreamOpFlag.set)
boolean isKnown(int flags) {
return (flags & preserve) == set;
}
// 这里就用到按位与判断输入的flags中是否清除当前StreamOpFlag(StreamOpFlag.clear)
boolean isCleared(int flags) {
return (flags & preserve) == clear;
}
// 这里就用到按位与判断输入的flags中是否保留当前StreamOpFlag(StreamOpFlag.clear)
boolean isPreserved(int flags) {
return (flags & preserve) == preserve;
}
// 判断当前的Stream实体类型是否可以设置本标志,要求Stream实体类型的标志位为set或者preserve,按位与要大于0
boolean canSet(Type t) {
return (maskTable.get(t) & SET_BITS) > 0;
}
// 暂时忽略其他代码
}这里有个特殊操作,位运算的时候采用了(flags & preserve),理由是:同一个标志中的同一个Stream实体类型只可能存在set/inject、clear和preserve的其中一种,也就是同一个flags中不可能同时存在StreamOpFlag.SORTED.set和StreamOpFlag.SORTED.clear,从语义上已经矛盾,而set/inject、clear和preserve在bit map中的大小(为2位)和位置已经是固定的,preserve在设计的时候为0b11刚好2位取反,因此可以特化为(这个特化也让判断更加严谨):
(flags & set) == set => (flags & preserve) == set
(flags & clear) == clear => (flags & preserve) == clear
(flags & preserve) == preserve => (flags & preserve) == preserve分析这么多,总的来说,就是想通过一个32位整数,每2位分别表示3种状态,那么一个完整的Flags(标志集合)一共可以表示16种标志(position=[0,15],可以查看API注释,[4,11]和[13,15]的位置是未需实现或者预留的,属于gap)。接着分析掩码Mask的计算过程例子:
// 横向看(位移动运算符优先级高于与或,例如<<的优先级比|高)
SPLITERATOR_CHARACTERISTICS_MASK:
mask(init) = 0
mask(DISTINCT,SPLITERATOR[DISTINCT]=01,bitPosition=0) = 0000 0000 | 0000 0001 << 0 = 0000 0000 | 0000 0001 = 0000 0001
mask(SORTED,SPLITERATOR[SORTED]=01,bitPosition=2) = 0000 0001 | 0000 0001 << 2 = 0000 0001 | 0000 0100 = 0000 0101
mask(ORDERED,SPLITERATOR[ORDERED]=01,bitPosition=4) = 0000 0101 | 0000 0001 << 4 = 0000 0101 | 0001 0000 = 0001 0101
mask(SIZED,SPLITERATOR[SIZED]=01,bitPosition=6) = 0001 0101 | 0000 0001 << 6 = 0001 0101 | 0100 0000 = 0101 0101
mask(SHORT_CIRCUIT,SPLITERATOR[SHORT_CIRCUIT]=00,bitPosition=24) = 0101 0101 | 0000 0000 << 24 = 0101 0101 | 0000 0000 = 0101 0101
mask(final) = 0000 0000 0000 0000 0000 0000 0101 0101(二进制)、85(十进制)
STREAM_MASK:
mask(init) = 0
mask(DISTINCT,SPLITERATOR[DISTINCT]=01,bitPosition=0) = 0000 0000 | 0000 0001 << 0 = 0000 0000 | 0000 0001 = 0000 0001
mask(SORTED,SPLITERATOR[SORTED]=01,bitPosition=2) = 0000 0001 | 0000 0001 << 2 = 0000 0001 | 0000 0100 = 0000 0101
mask(ORDERED,SPLITERATOR[ORDERED]=01,bitPosition=4) = 0000 0101 | 0000 0001 << 4 = 0000 0101 | 0001 0000 = 0001 0101
mask(SIZED,SPLITERATOR[SIZED]=01,bitPosition=6) = 0001 0101 | 0000 0001 << 6 = 0001 0101 | 0100 0000 = 0101 0101
mask(SHORT_CIRCUIT,SPLITERATOR[SHORT_CIRCUIT]=00,bitPosition=24) = 0101 0101 | 0000 0000 << 24 = 0101 0101 | 0000 0000 = 0101 0101
mask(final) = 0000 0000 0000 0000 0000 0000 0101 0101(二进制)、85(十进制)
OP_MASK:
mask(init) = 0
mask(DISTINCT,SPLITERATOR[DISTINCT]=11,bitPosition=0) = 0000 0000 | 0000 0011 << 0 = 0000 0000 | 0000 0011 = 0000 0011
mask(SORTED,SPLITERATOR[SORTED]=11,bitPosition=2) = 0000 0011 | 0000 0011 << 2 = 0000 0011 | 0000 1100 = 0000 1111
mask(ORDERED,SPLITERATOR[ORDERED]=11,bitPosition=4) = 0000 1111 | 0000 0011 << 4 = 0000 1111 | 0011 0000 = 0011 1111
mask(SIZED,SPLITERATOR[SIZED]=10,bitPosition=6) = 0011 1111 | 0000 0010 << 6 = 0011 1111 | 1000 0000 = 1011 1111
mask(SHORT_CIRCUIT,SPLITERATOR[SHORT_CIRCUIT]=01,bitPosition=24) = 1011 1111 | 0000 0001 << 24 = 1011 1111 | 0100 0000 0000 0000 0000 0000 0000 = 0100 0000 0000 0000 0000 1011 1111
mask(final) = 0000 0000 1000 0000 0000 0000 1011 1111(二进制)、16777407(十进制)
TERMINAL_OP_MASK:
mask(init) = 0
mask(DISTINCT,SPLITERATOR[DISTINCT]=00,bitPosition=0) = 0000 0000 | 0000 0000 << 0 = 0000 0000 | 0000 0000 = 0000 0000
mask(SORTED,SPLITERATOR[SORTED]=00,bitPosition=2) = 0000 0000 | 0000 0000 << 2 = 0000 0000 | 0000 0000 = 0000 0000
mask(ORDERED,SPLITERATOR[ORDERED]=10,bitPosition=4) = 0000 0000 | 0000 0010 << 4 = 0000 0000 | 0010 0000 = 0010 0000
mask(SIZED,SPLITERATOR[SIZED]=00,bitPosition=6) = 0010 0000 | 0000 0000 << 6 = 0010 0000 | 0000 0000 = 0010 0000
mask(SHORT_CIRCUIT,SPLITERATOR[SHORT_CIRCUIT]=01,bitPosition=24) = 0010 0000 | 0000 0001 << 24 = 0010 0000 | 0001 0000 0000 0000 0000 0000 0000 = 0001 0000 0000 0000 0000 0010 0000
mask(final) = 0000 0001 0000 0000 0000 0000 0010 0000(二进制)、16777248(十进制)
UPSTREAM_TERMINAL_OP_MASK:
mask(init) = 0
mask(DISTINCT,SPLITERATOR[DISTINCT]=00,bitPosition=0) = 0000 0000 | 0000 0000 << 0 = 0000 0000 | 0000 0000 = 0000 0000
mask(SORTED,SPLITERATOR[SORTED]=00,bitPosition=2) = 0000 0000 | 0000 0000 << 2 = 0000 0000 | 0000 0000 = 0000 0000
mask(ORDERED,SPLITERATOR[ORDERED]=10,bitPosition=4) = 0000 0000 | 0000 0010 << 4 = 0000 0000 | 0010 0000 = 0010 0000
mask(SIZED,SPLITERATOR[SIZED]=00,bitPosition=6) = 0010 0000 | 0000 0000 << 6 = 0010 0000 | 0000 0000 = 0010 0000
mask(SHORT_CIRCUIT,SPLITERATOR[SHORT_CIRCUIT]=00,bitPosition=24) = 0010 0000 | 0000 0000 << 24 = 0010 0000 | 0000 0000 = 0010 0000
mask(final) = 0000 0000 0000 0000 0000 0000 0010 0000(二进制)、32(十进制)相关的方法和属性如下:
enum StreamOpFlag {
// SPLITERATOR类型的标志bit map
static final int SPLITERATOR_CHARACTERISTICS_MASK = createMask(Type.SPLITERATOR);
// STREAM类型的标志bit map
static final int STREAM_MASK = createMask(Type.STREAM);
// OP类型的标志bit map
static final int OP_MASK = createMask(Type.OP);
// TERMINAL_OP类型的标志bit map
static final int TERMINAL_OP_MASK = createMask(Type.TERMINAL_OP);
// UPSTREAM_TERMINAL_OP类型的标志bit map
static final int UPSTREAM_TERMINAL_OP_MASK = createMask(Type.UPSTREAM_TERMINAL_OP);
// 基于Stream类型,创建对应类型填充所有标志的bit map
private static int createMask(Type t) {
int mask = 0;
for (StreamOpFlag flag : StreamOpFlag.values()) {
mask |= flag.maskTable.get(t) << flag.bitPosition;
}
return mask;
}
// 构造一个标志本身的掩码,就是所有标志都采用保留位表示,目前作为flags == 0时候的初始值
private static final int FLAG_MASK = createFlagMask();
// 构造一个包含全部标志中的preserve位的bit map,按照目前来看是暂时是一个固定值,二进制表示为0011 0000 0000 0000 0000 1111 1111
private static int createFlagMask() {
int mask = 0;
for (StreamOpFlag flag : StreamOpFlag.values()) {
mask |= flag.preserve;
}
return mask;
}
// 构造一个Stream类型包含全部标志中的set位的bit map,这里直接使用了STREAM_MASK,按照目前来看是暂时是一个固定值,二进制表示为0000 0000 0000 0000 0000 0000 0101 0101
private static final int FLAG_MASK_IS = STREAM_MASK;
// 构造一个Stream类型包含全部标志中的clear位的bit map,按照目前来看是暂时是一个固定值,二进制表示为0000 0000 0000 0000 0000 0000 1010 1010
private static final int FLAG_MASK_NOT = STREAM_MASK << 1;
// 初始化操作的标志bit map,目前来看就是Stream的头节点初始化时候需要合并在flags里面的初始化值,照目前来看是暂时是一个固定值,二进制表示为0000 0000 0000 0000 0000 0000 1111 1111
static final int INITIAL_OPS_VALUE = FLAG_MASK_IS | FLAG_MASK_NOT;
}SPLITERATOR_CHARACTERISTICS_MASK等5个成员(见上面的Mask计算例子)其实就是预先计算好对应的Stream实体类型的「所有StreamOpFlag标志」的bit map,也就是之前那个展示Stream的类型和标志的映射图的"横向"展示:

Mask应用还在后面的方法。Mask的初始化就是提供给标志的合并(combine)和转化(从Spliterator中的characteristics转化为flags)操作的,见下面的方法:
enum StreamOpFlag {
// 这个方法完全没有注释,只使用在下面的combineOpFlags()方法中
// 从源码来看
// 入参flags == 0的时候,那么直接返回0011 0000 0000 0000 0000 1111 1111
// 入参flags != 0的时候,那么会把当前flags的所有set/inject、clear和preserve所在位在bit map中全部置为0,然后其他位全部置为1
private static int getMask(int flags) {
return (flags == 0)
? FLAG_MASK
: ~(flags | ((FLAG_MASK_IS & flags) << 1) | ((FLAG_MASK_NOT & flags) >> 1));
}
// 合并新的flags和前一个flags,这里还是用到老套路先和Mask按位与,再进行一次按位或
// 作为Stream的头节点的时候,prevCombOpFlags必须为INITIAL_OPS_VALUE
static int combineOpFlags(int newStreamOrOpFlags, int prevCombOpFlags) {
// 0x01 or 0x10 nibbles are transformed to 0x11
// 0x00 nibbles remain unchanged
// Then all the bits are flipped
// Then the result is logically or'ed with the operation flags.
return (prevCombOpFlags & StreamOpFlag.getMask(newStreamOrOpFlags)) | newStreamOrOpFlags;
}
// 通过合并后的flags,转换出Stream类型的flags
static int toStreamFlags(int combOpFlags) {
// By flipping the nibbles 0x11 become 0x00 and 0x01 become 0x10
// Shift left 1 to restore set flags and mask off anything other than the set flags
return ((~combOpFlags) >> 1) & FLAG_MASK_IS & combOpFlags;
}
// Stream的标志转换为Spliterator的characteristics
static int toCharacteristics(int streamFlags) {
return streamFlags & SPLITERATOR_CHARACTERISTICS_MASK;
}
// Spliterator的characteristics转换为Stream的标志,入参是Spliterator实例
static int fromCharacteristics(Spliterator<?> spliterator) {
int characteristics = spliterator.characteristics();
if ((characteristics & Spliterator.SORTED) != 0 && spliterator.getComparator() != null) {
// Do not propagate the SORTED characteristic if it does not correspond
// to a natural sort order
return characteristics & SPLITERATOR_CHARACTERISTICS_MASK & ~Spliterator.SORTED;
}
else {
return characteristics & SPLITERATOR_CHARACTERISTICS_MASK;
}
}
// Spliterator的characteristics转换为Stream的标志,入参是Spliterator的characteristics
static int fromCharacteristics(int characteristics) {
return characteristics & SPLITERATOR_CHARACTERISTICS_MASK;
}
}这里的位运算很复杂,只展示简单的计算结果和相关功能:
combineOpFlags():用于合并新的flags和上一个flags,因为Stream的数据结构是一个Pipeline,后继节点需要合并前驱节点的flags,例如前驱节点flags是ORDERED.set,当前新加入Pipeline的节点(后继节点)的新flags为SIZED.set,那么在后继节点中应该合并前驱节点的标志,简单想象为SIZED.set | ORDERED.set,如果是头节点,那么初始化头节点时候的flags要合并INITIAL_OPS_VALUE,这里举个例子:int left = ORDERED.set | DISTINCT.set;
int right = SIZED.clear | SORTED.clear;
System.out.println("left:" + Integer.toBinaryString(left));
System.out.println("right:" + Integer.toBinaryString(right));
System.out.println("right mask:" + Integer.toBinaryString(getMask(right)));
System.out.println("combine:" + Integer.toBinaryString(combineOpFlags(right, left)));
// 输出结果
left:1010001
right:10001000
right mask:11111111111111111111111100110011
combine:10011001characteristics的转化问题:Spliterator中的characteristics可以通过简单的按位与转换为flags的原因是Spliterator中的characteristics在设计时候本身就是和StreamOpFlag匹配的,准确来说就是bit map的位分布是匹配的,所以直接与SPLITERATOR_CHARACTERISTICS_MASK做按位与即可,见下面的例子:// 这里简单点只展示8 bit
SPLITERATOR_CHARACTERISTICS_MASK: 0101 0101
Spliterator.ORDERED: 0001 0000
StreamOpFlag.ORDERED.set: 0001 0000至此,已经分析完StreamOpFlag的完整实现,Mask相关的方法限于篇幅就打算详细展开,下面会开始分析Stream中的"流水线"结构实现,因为习惯问题,下文的"标志"和"特性"两个词语会混用。
既然Stream具备流的特性,那么就需要一个链式数据结构,让元素能够从Source一直往下"流动"和传递到每一个链节点,实现这种场景的常用数据结构就是双向链表(考虑需要回溯,单向链表不太合适),目前比较著名的实现有AQS和Netty中的ChannelHandlerContext。例如Netty中的流水线ChannelPipeline设计如下:
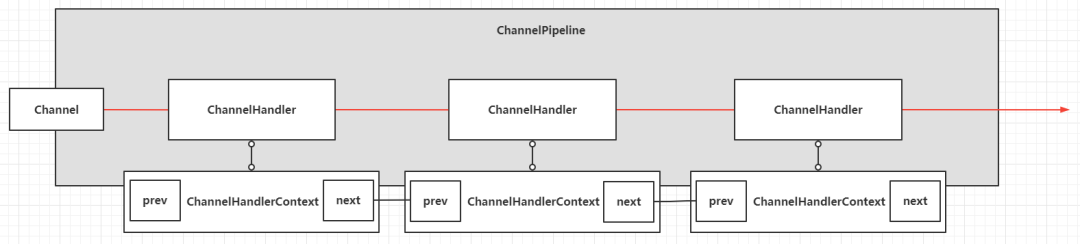
Stream中对应的类就是AbstractPipeline,核心实现类在ReferencePipeline和ReferencePipeline的内部类。
先简单展示AbstractPipeline的核心父类方法定义,主要接父类是Stream、BaseStream和PipelineHelper:
Stream代表一个支持串行和并行聚合操作集合的元素序列,此顶层接口提供了流中间操作、终结操作和一些静态工厂方法的定义(由于方法太多,这里不全部列举),这个接口本质是一个建造器类型接口(对接中间操作来说),可以构成一个多中间操作,单终结操作的链,例如:public interface Stream<T> extends BaseStream<T, Stream<T>> {
// 忽略其他代码
// 过滤Op
Stream<T> filter(Predicate<? super T> predicate);
// 映射Op
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
// 终结操作 - 遍历
void forEach(Consumer<? super T> action);
// 忽略其他代码
}
// init
Stream x = buildStream();
// chain: head -> filter(Op) -> map(Op) -> forEach(Terminal Op)
x.filter().map().forEach()BaseStream:Stream的基础接口,定义流的迭代器、流的等效变体(并发处理变体、同步处理变体和不支持顺序处理元素变体)、并发和同步判断以及关闭相关方法// T是元素类型,S是BaseStream<T, S>类型
// 流的基础接口,这里的流指定的支持同步执行和异步执行的聚合操作的元素序列
public interface BaseStream<T, S extends BaseStream<T, S>> extends AutoCloseable {
// 返回一个当前Stream实例中所有元素的迭代器
// 这是一个终结操作
Iterator<T> iterator();
// 返回一个当前Stream实例中所有元素的可拆分迭代器
Spliterator<T> spliterator();
// 当前的Stream实例是否支持并发
boolean isParallel();
// 返回一个等效的同步处理的Stream实例
S sequential();
// 返回一个等效的并发处理的Stream实例
S parallel();
// 返回一个等效的不支持StreamOpFlag.ORDERED特性的Stream实例
// 或者说支持StreamOpFlag.NOT_ORDERED的特性,也就返回的变体Stream在处理元素的时候不需要顺序处理
S unordered();
// 返回一个添加了close处理器的Stream实例,close处理器会在下面的close方法中回调
S onClose(Runnable closeHandler);
// 关闭当前Stream实例,回调关联本Stream的所有close处理器
@Override
void close();
}PipelineHelper:abstract class PipelineHelper<P_OUT> {
// 获取流的流水线的数据源的"形状",其实就是数据源元素的类型
// 主要有四种类型:REFERENCE(除了int、long和double之外的引用类型)、INT_VALUE、LONG_VALUE和DOUBLE_VALUE
abstract StreamShape getSourceShape();
// 获取合并流和流操作的标志,合并的标志包括流的数据源标志、中间操作标志和终结操作标志
// 从实现上看是当前流管道节点合并前面所有节点和自身节点标志的所有标志
abstract int getStreamAndOpFlags();
// 如果当前的流管道节点的合并标志集合支持SIZED,则调用Spliterator.getExactSizeIfKnown()返回数据源中的准确元素数量,否则返回-1
abstract<P_IN> long exactOutputSizeIfKnown(Spliterator<P_IN> spliterator);
// 相当于调用下面的方法组合:copyInto(wrapSink(sink), spliterator)
abstract<P_IN, S extends Sink<P_OUT>> S wrapAndCopyInto(S sink, Spliterator<P_IN> spliterator);
// 发送所有来自Spliterator中的元素到Sink中,如果支持SHORT_CIRCUIT标志,则会调用copyIntoWithCancel
abstract<P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator);
// 发送所有来自Spliterator中的元素到Sink中,Sink处理完每个元素后会检查Sink#cancellationRequested()方法的状态去判断是否中断推送元素的操作
abstract <P_IN> boolean copyIntoWithCancel(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator);
// 创建接收元素类型为P_IN的Sink实例,实现PipelineHelper中描述的所有中间操作,用这个Sink去包装传入的Sink实例(传入的Sink实例的元素类型为PipelineHelper的输出类型P_OUT)
abstract<P_IN> Sink<P_IN> wrapSink(Sink<P_OUT> sink);
// 包装传入的spliterator,从源码来看,在Stream链的头节点调用会直接返回传入的实例,如果在非头节点调用会委托到StreamSpliterators.WrappingSpliterator()方法进行包装
// 这个方法在源码中没有API注释
abstract<P_IN> Spliterator<P_OUT> wrapSpliterator(Spliterator<P_IN> spliterator);
// 构造一个兼容当前Stream元素"形状"的Node.Builder实例
// 从源码来看直接委托到Nodes.builder()方法
abstract Node.Builder<P_OUT> makeNodeBuilder(long exactSizeIfKnown,
IntFunction<P_OUT[]> generator);
// Stream流水线所有阶段(节点)应用于数据源Spliterator,输出的元素作为结果收集起来转化为Node实例
// 此方法应用于toArray()方法的计算,本质上是一个终结操作
abstract<P_IN> Node<P_OUT> evaluate(Spliterator<P_IN> spliterator,
boolean flatten,
IntFunction<P_OUT[]> generator);
}注意一点(重复3次):
PipelineHelper的几个方法中存在Sink这个接口,上一节没有分析,这一小节会详细展开。Stream在构建的时候虽然是一个双向链表的结构,但是在最终应用终结操作的时候,会把所有操作转化为引用类型链(ChainedReference),记得之前也提到过这种类似于多层包装器的编程模式,简化一下模型如下:
public class WrapperApp {
interface Wrapper {
void doAction();
}
public static void main(String[] args) {
AtomicInteger counter = new AtomicInteger(0);
Wrapper first = () -> System.out.printf("wrapper [depth => %d] invoke\n", counter.incrementAndGet());
Wrapper second = () -> {
first.doAction();
System.out.printf("wrapper [depth => %d] invoke\n", counter.incrementAndGet());
};
second.doAction();
}
}
// 控制台输出
wrapper [depth => 1] invoke
wrapper [depth => 2] invoke上面的例子有点突兀,两个不同Sink的实现可以做到无感知融合,举另一个例子如下:
public interface Sink<T> extends Consumer<T> {
default void begin(long size) {
}
default void end() {
}
abstract class ChainedReference<T, OUT> implements Sink<T> {
protected final Sink<OUT> downstream;
public ChainedReference(Sink<OUT> downstream) {
this.downstream = downstream;
}
}
}
@SuppressWarnings({"unchecked", "rawtypes"})
public class ReferenceChain<OUT, R> {
/**
* sink chain
*/
private final List<Supplier<Sink<?>>> sinkBuilders = new ArrayList<>();
/**
* current sink
*/
private final AtomicReference<Sink> sinkReference = new AtomicReference<>();
public ReferenceChain<OUT, R> filter(Predicate<OUT> predicate) {
//filter
sinkBuilders.add(() -> {
Sink<OUT> prevSink = (Sink<OUT>) sinkReference.get();
Sink.ChainedReference<OUT, OUT> currentSink = new Sink.ChainedReference<>(prevSink) {
@Override
public void accept(OUT out) {
if (predicate.test(out)) {
downstream.accept(out);
}
}
};
sinkReference.set(currentSink);
return currentSink;
});
return this;
}
public ReferenceChain<OUT, R> map(Function<OUT, R> function) {
// map
sinkBuilders.add(() -> {
Sink<R> prevSink = (Sink<R>) sinkReference.get();
Sink.ChainedReference<OUT, R> currentSink = new Sink.ChainedReference<>(prevSink) {
@Override
public void accept(OUT in) {
downstream.accept(function.apply(in));
}
};
sinkReference.set(currentSink);
return currentSink;
});
return this;
}
public void forEachPrint(Collection<OUT> collection) {
forEachPrint(collection, false);
}
public void forEachPrint(Collection<OUT> collection, boolean reverse) {
Spliterator<OUT> spliterator = collection.spliterator();
// 这个是类似于terminal op
Sink<OUT> sink = System.out::println;
sinkReference.set(sink);
Sink<OUT> stage = sink;
// 反向包装 -> 正向遍历
if (reverse) {
for (int i = 0; i <= sinkBuilders.size() - 1; i++) {
Supplier<Sink<?>> supplier = sinkBuilders.get(i);
stage = (Sink<OUT>) supplier.get();
}
} else {
// 正向包装 -> 反向遍历
for (int i = sinkBuilders.size() - 1; i >= 0; i--) {
Supplier<Sink<?>> supplier = sinkBuilders.get(i);
stage = (Sink<OUT>) supplier.get();
}
}
Sink<OUT> finalStage = stage;
spliterator.forEachRemaining(finalStage);
}
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(12);
ReferenceChain<Integer, Integer> chain = new ReferenceChain<>();
// filter -> map -> for each
chain.filter(item -> item > 10)
.map(item -> item * 2)
.forEachPrint(list);
}
}
// 输出结果
24执行的流程如下:
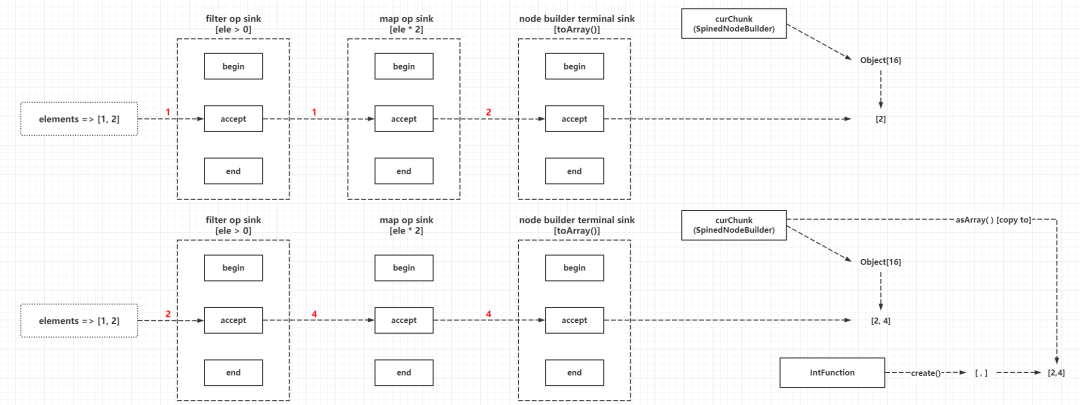
java.util.function.Consumer的实现,也就是实现accept(T t)方法完成对传入的元素进行处理Sink总是以后处理的Sink为入参,在自身处理方法中判断和回调传入的Sink的处理方法回调,也就是构建引用链的时候,需要从后往前构建,这种方式的实现逻辑可以参考AbstractPipeline#wrapSink(),例如:// 目标顺序:filter -> map
Sink mapSink = new Sink(inputSink){
private Function mapper;
public void accept(E ele) {
inputSink.accept(mapper.apply(ele))
}
}
Sink filterSink = new Sink(mapSink){
private Predicate predicate;
public void accept(E ele) {
if(predicate.test(ele)){
mapSink.accept(ele);
}
}
}Sink上上面的代码并非笔者虚构出来,可见java.util.stream.Sink的源码:
// 继承自Consumer,主要是继承函数式接口方法void accept(T t)
interface Sink<T> extends Consumer<T> {
// 重置当前Sink的状态(为了接收一个新的数据集),传入的size是推送到downstream的准确数据量,无法评估数据量则传入-1
default void begin(long size) {}
//
default void end() {}
// 返回true的时候表示当前的Sink不会接收数据
default boolean cancellationRequested() {
return false;
}
// 特化方法,接受一个int类型的值
default void accept(int value) {
throw new IllegalStateException("called wrong accept method");
}
// 特化方法,接受一个long类型的值
default void accept(long value) {
throw new IllegalStateException("called wrong accept method");
}
// 特化方法,接受一个double类型的值
default void accept(double value) {
throw new IllegalStateException("called wrong accept method");
}
// 引用类型链,准确来说是Sink链
abstract static class ChainedReference<T, E_OUT> implements Sink<T> {
// 下一个Sink
protected final Sink<? super E_OUT> downstream;
public ChainedReference(Sink<? super E_OUT> downstream) {
this.downstream = Objects.requireNonNull(downstream);
}
@Override
public void begin(long size) {
downstream.begin(size);
}
@Override
public void end() {
downstream.end();
}
@Override
public boolean cancellationRequested() {
return downstream.cancellationRequested();
}
}
// 暂时忽略Int、Long、Double的特化类型场景
}如果用过RxJava或者Project-Reactor,Sink更像是Subscriber,多个Subscriber组成了ChainedReference(Sink Chain,可以理解为一个复合的Subscriber),而Terminal Op则类似于Publisher,只有在Subscriber订阅Publisher的时候才会进行数据的处理,这里是应用了Reactive编程模式。
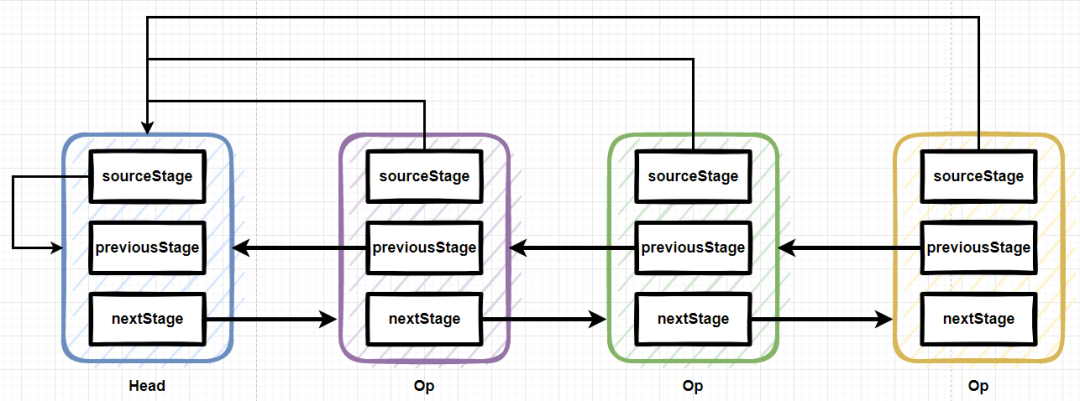
AbstractPipeline和ReferencePipeline都是抽象类,AbstractPipeline用于构建Pipeline的数据结构,提供一些Shape相关的抽象方法给ReferencePipeline实现,而ReferencePipeline就是Stream中Pipeline的基础类型,从源码上看,Stream链式(管道式)结构的头节点和操作节点都是ReferencePipeline的子类。先看AbstractPipeline的成员变量和构造函数:
abstract class AbstractPipeline<E_IN, E_OUT, S extends BaseStream<E_OUT, S>>
extends PipelineHelper<E_OUT> implements BaseStream<E_OUT, S> {
// 流管道链式结构的头节点(只有当前的AbstractPipeline引用是头节点,此变量才会被赋值,非头节点为NULL)
@SuppressWarnings("rawtypes")
private final AbstractPipeline sourceStage;
// 流管道链式结构的upstream,也就是上一个节点,如果是头节点此引用为NULL
@SuppressWarnings("rawtypes")
private final AbstractPipeline previousStage;
// 合并数据源的标志和操作标志的掩码
protected final int sourceOrOpFlags;
// 流管道链式结构的下一个节点,如果是头节点此引用为NULL
@SuppressWarnings("rawtypes")
private AbstractPipeline nextStage;
// 流的深度
// 串行执行的流中,表示当前流管道实例中中间操作节点的个数(除去头节点和终结操作)
// 并发执行的流中,表示当前流管道实例中中间操作节点和前一个有状态操作节点之间的节点个数
private int depth;
// 合并了所有数据源的标志、操作标志和当前的节点(AbstractPipeline)实例的标志,也就是当前的节点可以基于此属性得知所有支持的标志
private int combinedFlags;
// 数据源的Spliterator实例
private Spliterator<?> sourceSpliterator;
// 数据源的Spliterator实例封装的Supplier实例
private Supplier<? extends Spliterator<?>> sourceSupplier;
// 标记当前的流节点是否被连接或者消费掉,不能重复连接或者重复消费
private boolean linkedOrConsumed;
// 标记当前的流管道链式结构中是否存在有状态的操作节点,这个属性只会在头节点中有效
private boolean sourceAnyStateful;
// 数据源关闭动作,这个属性只会在头节点中有效,由sourceStage持有
private Runnable sourceCloseAction;
// 标记当前流是否并发执行
private boolean parallel;
// 流管道结构头节点的父构造方法,使用数据源的Spliterator实例封装的Supplier实例
AbstractPipeline(Supplier<? extends Spliterator<?>> source,
int sourceFlags, boolean parallel) {
// 头节点的前驱节点置为NULL
this.previousStage = null;
this.sourceSupplier = source;
this.sourceStage = this;
// 合并传入的源标志和流标志的掩码
this.sourceOrOpFlags = sourceFlags & StreamOpFlag.STREAM_MASK;
// The following is an optimization of:
// StreamOpFlag.combineOpFlags(sourceOrOpFlags, StreamOpFlag.INITIAL_OPS_VALUE);
// 初始化合并标志集合为sourceOrOpFlags和所有流操作标志的初始化值
this.combinedFlags = (~(sourceOrOpFlags << 1)) & StreamOpFlag.INITIAL_OPS_VALUE;
// 深度设置为0
this.depth = 0;
this.parallel = parallel;
}
// 流管道结构头节点的父构造方法,使用数据源的Spliterator实例
AbstractPipeline(Spliterator<?> source,
int sourceFlags, boolean parallel) {
// 头节点的前驱节点置为NULL
this.previousStage = null;
this.sourceSpliterator = source;
this.sourceStage = this;
// 合并传入的源标志和流标志的掩码
this.sourceOrOpFlags = sourceFlags & StreamOpFlag.STREAM_MASK;
// The following is an optimization of:
// StreamOpFlag.combineOpFlags(sourceOrOpFlags, StreamOpFlag.INITIAL_OPS_VALUE);
// 初始化合并标志集合为sourceOrOpFlags和所有流操作标志的初始化值
this.combinedFlags = (~(sourceOrOpFlags << 1)) & StreamOpFlag.INITIAL_OPS_VALUE;
this.depth = 0;
this.parallel = parallel;
}
// 流管道结构中间操作节点的父构造方法
AbstractPipeline(AbstractPipeline<?, E_IN, ?> previousStage, int opFlags) {
if (previousStage.linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
previousStage.linkedOrConsumed = true;
// 设置前驱节点的后继节点引用为当前的AbstractPipeline实例
previousStage.nextStage = this;
// 设置前驱节点引用为传入的前驱节点实例
this.previousStage = previousStage;
// 合并传入的中间操作标志和流操作标志的掩码
this.sourceOrOpFlags = opFlags & StreamOpFlag.OP_MASK;
// 合并标志集合为传入的标志和前驱节点的标志集合
this.combinedFlags = StreamOpFlag.combineOpFlags(opFlags, previousStage.combinedFlags);
// 赋值sourceStage为前驱节点的sourceStage
this.sourceStage = previousStage.sourceStage;
if (opIsStateful())
// 标记当前的流存在有状态操作
sourceStage.sourceAnyStateful = true;
// 深度设置为前驱节点深度加1
this.depth = previousStage.depth + 1;
}
// 省略其他方法
}至此,可以看出流管道的数据结构:
Terminal Op不参与管道链式结构的构建。接着看AbstractPipeline中的终结求值方法(Terminal evaluation methods):
abstract class AbstractPipeline<E_IN, E_OUT, S extends BaseStream<E_OUT, S>>
extends PipelineHelper<E_OUT> implements BaseStream<E_OUT, S> {
// 省略其他方法
// 基于终结操作进行求值,这个是Stream执行的常用核心方法,常用于collect()这类终结操作
final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp) {
assert getOutputShape() == terminalOp.inputShape();
// 判断linkedOrConsumed,以防多次终结求值,也就是每个终结操作只能执行一次
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
// 如果当前流支持并发执行,则委托到TerminalOp.evaluateParallel(),如果当前流只支持同步执行,则委托到TerminalOp.evaluateSequential()
// 这里注意传入到TerminalOp中的方法参数分别是this(PipelineHelper类型)和数据源Spliterator
return isParallel()
? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags()))
: terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));
}
// 基于当前的流实例转换为最终的Node实例,传入的IntFunction用于创建数组实例
// 此终结方法一般用于toArray()这类终结操作
@SuppressWarnings("unchecked")
final Node<E_OUT> evaluateToArrayNode(IntFunction<E_OUT[]> generator) {
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
// If the last intermediate operation is stateful then
// evaluate directly to avoid an extra collection step
// 当前流支持并发执行,并且最后一个中间操作是有状态,则委托到opEvaluateParallel(),否则委托到evaluate(),这两个都是AbstractPipeline中的方法
if (isParallel() && previousStage != null && opIsStateful()) {
// Set the depth of this, last, pipeline stage to zero to slice the
// pipeline such that this operation will not be included in the
// upstream slice and upstream operations will not be included
// in this slice
depth = 0;
return opEvaluateParallel(previousStage, previousStage.sourceSpliterator(0), generator);
}
else {
return evaluate(sourceSpliterator(0), true, generator);
}
}
// 这个方法比较简单,就是获取当前流的数据源所在的Spliterator,并且确保流已经消费,一般用于forEach()这类终结操作
final Spliterator<E_OUT> sourceStageSpliterator() {
if (this != sourceStage)
throw new IllegalStateException();
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
if (sourceStage.sourceSpliterator != null) {
@SuppressWarnings("unchecked")
Spliterator<E_OUT> s = sourceStage.sourceSpliterator;
sourceStage.sourceSpliterator = null;
return s;
}
else if (sourceStage.sourceSupplier != null) {
@SuppressWarnings("unchecked")
Spliterator<E_OUT> s = (Spliterator<E_OUT>) sourceStage.sourceSupplier.get();
sourceStage.sourceSupplier = null;
return s;
}
else {
throw new IllegalStateException(MSG_CONSUMED);
}
}
// 省略其他方法
}AbstractPipeline中实现了BaseStream的方法:
abstract class AbstractPipeline<E_IN, E_OUT, S extends BaseStream<E_OUT, S>>
extends PipelineHelper<E_OUT> implements BaseStream<E_OUT, S> {
// 省略其他方法
// 设置头节点的parallel属性为false,返回自身实例,表示当前的流是同步执行的
@Override
@SuppressWarnings("unchecked")
public final S sequential() {
sourceStage.parallel = false;
return (S) this;
}
// 设置头节点的parallel属性为true,返回自身实例,表示当前的流是并发执行的
@Override
@SuppressWarnings("unchecked")
public final S parallel() {
sourceStage.parallel = true;
return (S) this;
}
// 流关闭操作,设置linkedOrConsumed为true,数据源的Spliterator相关引用置为NULL,置空并且回调sourceCloseAction钩子实例
@Override
public void close() {
linkedOrConsumed = true;
sourceSupplier = null;
sourceSpliterator = null;
if (sourceStage.sourceCloseAction != null) {
Runnable closeAction = sourceStage.sourceCloseAction;
sourceStage.sourceCloseAction = null;
closeAction.run();
}
}
// 返回一个添加了close处理器的Stream实例,close处理器会在下面的close方法中回调
// 如果本来持有的引用sourceStage.sourceCloseAction非空,会使用传入的closeHandler与sourceStage.sourceCloseAction进行合并
@Override
@SuppressWarnings("unchecked")
public S onClose(Runnable closeHandler) {
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
Objects.requireNonNull(closeHandler);
Runnable existingHandler = sourceStage.sourceCloseAction;
sourceStage.sourceCloseAction =
(existingHandler == null)
? closeHandler
: Streams.composeWithExceptions(existingHandler, closeHandler);
return (S) this;
}
// Primitive specialization use co-variant overrides, hence is not final
// 返回当前流实例中所有元素的Spliterator实例
@Override
@SuppressWarnings("unchecked")
public Spliterator<E_OUT> spliterator() {
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
// 标记当前节点被链接或者消费
linkedOrConsumed = true;
// 如果当前节点为头节点,那么返回sourceStage.sourceSpliterator或者延时加载的sourceStage.sourceSupplier(延时加载封装由lazySpliterator实现)
if (this == sourceStage) {
if (sourceStage.sourceSpliterator != null) {
@SuppressWarnings("unchecked")
Spliterator<E_OUT> s = (Spliterator<E_OUT>) sourceStage.sourceSpliterator;
sourceStage.sourceSpliterator = null;
return s;
}
else if (sourceStage.sourceSupplier != null) {
@SuppressWarnings("unchecked")
Supplier<Spliterator<E_OUT>> s = (Supplier<Spliterator<E_OUT>>) sourceStage.sourceSupplier;
sourceStage.sourceSupplier = null;
return lazySpliterator(s);
}
else {
throw new IllegalStateException(MSG_CONSUMED);
}
}
else {
// 如果当前节点不是头节点,重新对sourceSpliterator进行包装,包装后的实例为WrappingSpliterator
return wrap(this, () -> sourceSpliterator(0), isParallel());
}
}
// 当前流实例是否并发执行,从头节点的parallel属性进行判断
@Override
public final boolean isParallel() {
return sourceStage.parallel;
}
// 从当前combinedFlags中获取数据源标志和所有流中间操作标志的集合
final int getStreamFlags() {
return StreamOpFlag.toStreamFlags(combinedFlags);
}
/**
* Get the source spliterator for this pipeline stage. For a sequential or
* stateless parallel pipeline, this is the source spliterator. For a
* stateful parallel pipeline, this is a spliterator describing the results
* of all computations up to and including the most recent stateful
* operation.
*/
@SuppressWarnings("unchecked")
private Spliterator<?> sourceSpliterator(int terminalFlags) {
// 从sourceStage.sourceSpliterator或者sourceStage.sourceSupplier中获取当前流实例中的Spliterator实例,确保必定存在,否则抛出IllegalStateException
Spliterator<?> spliterator = null;
if (sourceStage.sourceSpliterator != null) {
spliterator = sourceStage.sourceSpliterator;
sourceStage.sourceSpliterator = null;
}
else if (sourceStage.sourceSupplier != null) {
spliterator = (Spliterator<?>) sourceStage.sourceSupplier.get();
sourceStage.sourceSupplier = null;
}
else {
throw new IllegalStateException(MSG_CONSUMED);
}
// 下面这段逻辑是对于并发执行并且存在有状态操作的节点,那么需要重新计算节点的深度和节点的合并标志集合
// 这里只提一下计算过程,从头节点的后继节点开始遍历到当前节点,如果被遍历的节点时有状态的,那么对depth、combinedFlags和spliterator会进行重新计算
// depth一旦出现有状态节点就会重置为0,然后从1重新开始增加
// combinedFlags会重新合并sourceOrOpFlags、SHORT_CIRCUIT(如果sourceOrOpFlags支持)和Spliterator.SIZED
// spliterator简单来看就是从并发执行的toArray()=>Array数组=>Spliterator实例
if (isParallel() && sourceStage.sourceAnyStateful) {
// Adapt the source spliterator, evaluating each stateful op
// in the pipeline up to and including this pipeline stage.
// The depth and flags of each pipeline stage are adjusted accordingly.
int depth = 1;
for (@SuppressWarnings("rawtypes") AbstractPipeline u = sourceStage, p = sourceStage.nextStage, e = this;
u != e;
u = p, p = p.nextStage) {
int thisOpFlags = p.sourceOrOpFlags;
if (p.opIsStateful()) {
depth = 0;
if (StreamOpFlag.SHORT_CIRCUIT.isKnown(thisOpFlags)) {
// Clear the short circuit flag for next pipeline stage
// This stage encapsulates short-circuiting, the next
// stage may not have any short-circuit operations, and
// if so spliterator.forEachRemaining should be used
// for traversal
thisOpFlags = thisOpFlags & ~StreamOpFlag.IS_SHORT_CIRCUIT;
}
spliterator = p.opEvaluateParallelLazy(u, spliterator);
// Inject or clear SIZED on the source pipeline stage
// based on the stage's spliterator
thisOpFlags = spliterator.hasCharacteristics(Spliterator.SIZED)
? (thisOpFlags & ~StreamOpFlag.NOT_SIZED) | StreamOpFlag.IS_SIZED
: (thisOpFlags & ~StreamOpFlag.IS_SIZED) | StreamOpFlag.NOT_SIZED;
}
p.depth = depth++;
p.combinedFlags = StreamOpFlag.combineOpFlags(thisOpFlags, u.combinedFlags);
}
}
// 如果传入的terminalFlags标志不为0,则当前节点的combinedFlags会合并terminalFlags
if (terminalFlags != 0) {
// Apply flags from the terminal operation to last pipeline stage
combinedFlags = StreamOpFlag.combineOpFlags(terminalFlags, combinedFlags);
}
return spliterator;
}
// 省略其他方法
}AbstractPipeline中实现了PipelineHelper的方法:
abstract class AbstractPipeline<E_IN, E_OUT, S extends BaseStream<E_OUT, S>>
extends PipelineHelper<E_OUT> implements BaseStream<E_OUT, S> {
// 省略其他方法
// 获取数据源元素的类型,这里的类型包括引用、int、double和float
// 其实实现上就是获取depth<=0的第一个节点的输出类型
@Override
final StreamShape getSourceShape() {
@SuppressWarnings("rawtypes")
AbstractPipeline p = AbstractPipeline.this;
while (p.depth > 0) {
p = p.previousStage;
}
return p.getOutputShape();
}
// 基于当前节点的标志集合判断和返回流中待处理的元素数量,无法获取则返回-1
@Override
final <P_IN> long exactOutputSizeIfKnown(Spliterator<P_IN> spliterator) {
return StreamOpFlag.SIZED.isKnown(getStreamAndOpFlags()) ? spliterator.getExactSizeIfKnown() : -1;
}
// 通过流管道链式结构构建元素引用链,再遍历元素引用链
@Override
final <P_IN, S extends Sink<E_OUT>> S wrapAndCopyInto(S sink, Spliterator<P_IN> spliterator) {
copyInto(wrapSink(Objects.requireNonNull(sink)), spliterator);
return sink;
}
// 遍历元素引用链
@Override
final <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
Objects.requireNonNull(wrappedSink);
// 当前节点不支持SHORT_CIRCUIT(短路)特性,则直接遍历元素引用链,不支持短路跳出
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
wrappedSink.begin(spliterator.getExactSizeIfKnown());
spliterator.forEachRemaining(wrappedSink);
wrappedSink.end();
}
else {
// 支持短路(中途取消)遍历元素引用链
copyIntoWithCancel(wrappedSink, spliterator);
}
}
// 支持短路(中途取消)遍历元素引用链
@Override
@SuppressWarnings("unchecked")
final <P_IN> boolean copyIntoWithCancel(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
@SuppressWarnings({"rawtypes","unchecked"})
AbstractPipeline p = AbstractPipeline.this;
// 基于当前节点,获取流管道链式结构中第最后一个depth=0的前驱节点
while (p.depth > 0) {
p = p.previousStage;
}
wrappedSink.begin(spliterator.getExactSizeIfKnown());
// 委托到forEachWithCancel()进行遍历
boolean cancelled = p.forEachWithCancel(spliterator, wrappedSink);
wrappedSink.end();
return cancelled;
}
// 返回当前节点的标志集合
@Override
final int getStreamAndOpFlags() {
return combinedFlags;
}
// 当前节点标志集合中是否支持ORDERED
final boolean isOrdered() {
return StreamOpFlag.ORDERED.isKnown(combinedFlags);
}
// 构建元素引用链,生成一个多重包装的Sink(WrapSink),这里的逻辑可以看前面的分析章节
@Override
@SuppressWarnings("unchecked")
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {
Objects.requireNonNull(sink);
// 这里遍历的时候,总是从当前节点向前驱节点遍历,也就是传入的sink实例总是包裹在最里面一层执行
for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink<P_IN>) sink;
}
// 包装数据源的Spliterator,如果depth=0,则直接返回sourceSpliterator,否则返回的是延迟加载的WrappingSpliterator
@Override
@SuppressWarnings("unchecked")
final <P_IN> Spliterator<E_OUT> wrapSpliterator(Spliterator<P_IN> sourceSpliterator) {
if (depth == 0) {
return (Spliterator<E_OUT>) sourceSpliterator;
}
else {
return wrap(this, () -> sourceSpliterator, isParallel());
}
}
// 计算Node实例,这个方法用于toArray()方法系列,是一个终结操作,下面会另开章节详细分析
@Override
@SuppressWarnings("unchecked")
final <P_IN> Node<E_OUT> evaluate(Spliterator<P_IN> spliterator,
boolean flatten,
IntFunction<E_OUT[]> generator) {
if (isParallel()) {
// @@@ Optimize if op of this pipeline stage is a stateful op
return evaluateToNode(this, spliterator, flatten, generator);
}
else {
Node.Builder<E_OUT> nb = makeNodeBuilder(
exactOutputSizeIfKnown(spliterator), generator);
return wrapAndCopyInto(nb, spliterator).build();
}
}
// 省略其他方法
}AbstractPipeline中剩余的待如XXYYZZPipeline等子类实现的抽象方法:
abstract class AbstractPipeline<E_IN, E_OUT, S extends BaseStream<E_OUT, S>>
extends PipelineHelper<E_OUT> implements BaseStream<E_OUT, S> {
// 省略其他方法
// 获取当前流的输出"形状",REFERENCE、INT_VALUE、LONG_VALUE或者DOUBLE_VALUE
abstract StreamShape getOutputShape();
// 收集当前流的所有输出元素,转化为一个适配当前流输出"形状"的Node实例
abstract <P_IN> Node<E_OUT> evaluateToNode(PipelineHelper<E_OUT> helper,
Spliterator<P_IN> spliterator,
boolean flattenTree,
IntFunction<E_OUT[]> generator);
// 包装Spliterator为WrappingSpliterator实例
abstract <P_IN> Spliterator<E_OUT> wrap(PipelineHelper<E_OUT> ph,
Supplier<Spliterator<P_IN>> supplier,
boolean isParallel);
// 包装Spliterator为DelegatingSpliterator实例
abstract <P_IN> Spliterator<E_OUT> wrap(PipelineHelper<E_OUT> ph,
Supplier<Spliterator<P_IN>> supplier,
boolean isParallel);
// 基于Sink遍历Spliterator中的元素,支持取消操作,简单理解就是支持cancel的tryAdvance方法
abstract boolean forEachWithCancel(Spliterator<E_OUT> spliterator, Sink<E_OUT> sink);
// 返回Node的建造器实例,用于toArray方法系列
abstract Node.Builder<E_OUT> makeNodeBuilder(long exactSizeIfKnown,
IntFunction<E_OUT[]> generator);
// 判断当前的操作(节点)是否有状态,如果是有状态的操作,必须覆盖opEvaluateParallel方法
abstract boolean opIsStateful();
// 当前操作生成的结果会作为传入的Sink实例的入参,这是一个包装Sink的过程,通俗理解就是之前提到的元素引用链添加一个新的链节点,这个方法算是流执行的一个核心方法
abstract Sink<E_IN> opWrapSink(int flags, Sink<E_OUT> sink);
// 并发执行的操作节点求值
<P_IN> Node<E_OUT> opEvaluateParallel(PipelineHelper<E_OUT> helper,
Spliterator<P_IN> spliterator,
IntFunction<E_OUT[]> generator) {
throw new UnsupportedOperationException("Parallel evaluation is not supported");
}
// 并发执行的操作节点惰性求值
@SuppressWarnings("unchecked")
<P_IN> Spliterator<E_OUT> opEvaluateParallelLazy(PipelineHelper<E_OUT> helper,
Spliterator<P_IN> spliterator) {
return opEvaluateParallel(helper, spliterator, i -> (E_OUT[]) new Object[i]).spliterator();
}
// 省略其他方法
}这里提到的抽象方法opWrapSink()其实就是元素引用链的添加链节点的方法,它的实现逻辑见子类,这里只考虑非特化子类ReferencePipeline的部分源码:
abstract class ReferencePipeline<P_IN, P_OUT>
extends AbstractPipeline<P_IN, P_OUT, Stream<P_OUT>>
implements Stream<P_OUT> {
// 构造函数,用于头节点,传入基于Supplier封装的Spliterator实例作为数据源,数据源的标志集合和是否支持并发执行的判断标记
ReferencePipeline(Supplier<? extends Spliterator<?>> source,
int sourceFlags, boolean parallel) {
super(source, sourceFlags, parallel);
}
// 构造函数,用于头节点,传入Spliterator实例作为数据源,数据源的标志集合和是否支持并发执行的判断标记
ReferencePipeline(Spliterator<?> source,
int sourceFlags, boolean parallel) {
super(source, sourceFlags, parallel);
}
// 构造函数,用于中间节点,传入上一个流管道节点的实例(前驱节点)和当前操作节点支持的标志集合
ReferencePipeline(AbstractPipeline<?, P_IN, ?> upstream, int opFlags) {
super(upstream, opFlags);
}
// 这里流的输出"形状"固定为REFERENCE
@Override
final StreamShape getOutputShape() {
return StreamShape.REFERENCE;
}
// 转换当前流实例为Node实例,应用于toArray方法,后面详细分析终结操作的时候再展开
@Override
final <P_IN> Node<P_OUT> evaluateToNode(PipelineHelper<P_OUT> helper,
Spliterator<P_IN> spliterator,
boolean flattenTree,
IntFunction<P_OUT[]> generator) {
return Nodes.collect(helper, spliterator, flattenTree, generator);
}
// 包装Spliterator=>WrappingSpliterator
@Override
final <P_IN> Spliterator<P_OUT> wrap(PipelineHelper<P_OUT> ph,
Supplier<Spliterator<P_IN>> supplier,
boolean isParallel) {
return new StreamSpliterators.WrappingSpliterator<>(ph, supplier, isParallel);
}
// 包装Spliterator=>DelegatingSpliterator,实现惰性加载
@Override
final Spliterator<P_OUT> lazySpliterator(Supplier<? extends Spliterator<P_OUT>> supplier) {
return new StreamSpliterators.DelegatingSpliterator<>(supplier);
}
// 遍历Spliterator中的元素,基于传入的Sink实例进行处理,支持Cancel操作
@Override
final boolean forEachWithCancel(Spliterator<P_OUT> spliterator, Sink<P_OUT> sink) {
boolean cancelled;
do { } while (!(cancelled = sink.cancellationRequested()) && spliterator.tryAdvance(sink));
return cancelled;
}
// 构造Node建造器实例
@Override
final Node.Builder<P_OUT> makeNodeBuilder(long exactSizeIfKnown, IntFunction<P_OUT[]> generator) {
return Nodes.builder(exactSizeIfKnown, generator);
}
// 基于当前流的Spliterator生成迭代器实例
@Override
public final Iterator<P_OUT> iterator() {
return Spliterators.iterator(spliterator());
}
// 省略其他OP的代码
// 流管道结构的头节点
static class Head<E_IN, E_OUT> extends ReferencePipeline<E_IN, E_OUT> {
// 构造函数,用于头节点,传入基于Supplier封装的Spliterator实例作为数据源,数据源的标志集合和是否支持并发执行的判断标记
Head(Supplier<? extends Spliterator<?>> source,
int sourceFlags, boolean parallel) {
super(source, sourceFlags, parallel);
}
// 构造函数,用于头节点,传入Spliterator实例作为数据源,数据源的标志集合和是否支持并发执行的判断标记
Head(Spliterator<?> source,
int sourceFlags, boolean parallel) {
super(source, sourceFlags, parallel);
}
// 不支持判断是否状态操作
@Override
final boolean opIsStateful() {
throw new UnsupportedOperationException();
}
// 不支持包装Sink实例
@Override
final Sink<E_IN> opWrapSink(int flags, Sink<E_OUT> sink) {
throw new UnsupportedOperationException();
}
// 区分同步异步执行forEach,同步则简单理解为调用Spliterator.forEachRemaining,异步则调用终结操作forEach
@Override
public void forEach(Consumer<? super E_OUT> action) {
if (!isParallel()) {
sourceStageSpliterator().forEachRemaining(action);
}
else {
super.forEach(action);
}
}
// 区分同步异步执行forEachOrdered,同步则简单理解为调用Spliterator.forEachRemaining,异步则调用终结操作forEachOrdered
@Override
public void forEachOrdered(Consumer<? super E_OUT> action) {
if (!isParallel()) {
sourceStageSpliterator().forEachRemaining(action);
}
else {
super.forEachOrdered(action);
}
}
}
// 无状态操作节点的父类
abstract static class StatelessOp<E_IN, E_OUT>
extends ReferencePipeline<E_IN, E_OUT> {
// 基于上一个节点引用、输入元素"形状"和当前节点支持的标志集合创建StatelessOp实例
StatelessOp(AbstractPipeline<?, E_IN, ?> upstream,
StreamShape inputShape,
int opFlags) {
super(upstream, opFlags);
assert upstream.getOutputShape() == inputShape;
}
// 操作状态标记设置为无状态
@Override
final boolean opIsStateful() {
return false;
}
}
// 有状态操作节点的父类
abstract static class StatefulOp<E_IN, E_OUT>
extends ReferencePipeline<E_IN, E_OUT> {
// 基于上一个节点引用、输入元素"形状"和当前节点支持的标志集合创建StatefulOp实例
StatefulOp(AbstractPipeline<?, E_IN, ?> upstream,
StreamShape inputShape,
int opFlags) {
super(upstream, opFlags);
assert upstream.getOutputShape() == inputShape;
}
// 操作状态标记设置为有状态
@Override
final boolean opIsStateful() {
return true;
}
// 前面也提到,节点操作异步求值的方法在无状态节点下必须覆盖,这里重新把这个方法抽象,子类必须实现
@Override
abstract <P_IN> Node<E_OUT> opEvaluateParallel(PipelineHelper<E_OUT> helper,
Spliterator<P_IN> spliterator,
IntFunction<E_OUT[]> generator);
}
} 这里重重重点分析一下ReferencePipeline中的wrapSink方法实现:
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {
Objects.requireNonNull(sink);
for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink<P_IN>) sink;
}入参是一个Sink实例,返回值也是一个Sink实例,里面的for循环是基于当前的AbstractPipeline节点向前遍历,直到depth为0的节点跳出循环,而depth为0意味着该节点必定为头节点,也就是该循环是遍历当前节点到头节点的后继节点,Sink是"向前包装的",也就是处于链后面的节点Sink总是会作为其前驱节点的opWrapSink()方法的入参,在同步执行流求值计算的时候,前驱节点的Sink处理完元素后就会通过downstream引用(其实就是后驱节点的Sink)调用其accept()把元素或者处理完的元素结果传递进去,激活下一个Sink,以此类推。另外,ReferencePipeline的三个内部类Head、StatelessOp和StatefulOp就是流的节点类,其中只有Head是非抽象类,代表流管道结构(或者说双向链表结构)的头节点,StatelessOp(无状态操作)和StatefulOp(有状态操作)的子类构成了流管道结构的操作节点或者是终结操作。在忽略是否有状态操作的前提下看ReferencePipeline,它只是流数据结构的承载体,表面上看到的双向链表结构在流的求值计算过程中并不会进行直接遍历每个节点进行求值,而是先转化成一个多层包装的Sink,也就是前文笔者提到的元素引用链后者前一句分析的Sink元素处理以及传递,正确来说应该是一个Sink栈或者Sink包装器,它的实现可以类比为现实生活中的洋葱,或者编程模式中的AOP编程模式。形象一点的描述如下:
Head(Spliterator) -> Op(filter) -> Op(map) -> Op(sorted) -> Terminal Op(forEach)
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
forEach ele in Spliterator:
Sink[filter](ele){
if filter process == true:
Sink[map](ele){
ele = mapper(ele)
Sink[sorted](ele){
var array
begin:
accept(ele):
add ele to array
end:
sort ele in array
}
}
}终结操作forEach是目前分析源码中最简单的实现,下面会详细分析每种终结操作的实现细节。
限于篇幅,这里只能挑选一部分的中间Op进行分析。流的中间操作基本都是由BaseStream接口定义,在ReferencePipeline中进行实现,这里挑选比较常用的filter、map和sorted进行分析。先看filter:
abstract class ReferencePipeline<P_IN, P_OUT>
extends AbstractPipeline<P_IN, P_OUT, Stream<P_OUT>>
implements Stream<P_OUT> {
// 暂时省略其他代码
// filter操作,泛型参数Predicate类型接受一个任意类型(这里考虑到泛型擦除)的元素,输出布尔值,它是一个无状态操作
@Override
public final Stream<P_OUT> filter(Predicate<? super P_OUT> predicate) {
Objects.requireNonNull(predicate);
// 这里注意到,StatelessOp的第一个参数是指upstream,也就是理解为上一个节点,这里使用了this,意味着upstream为当前的ReferencePipeline实例,元素"形状"为引用类型,操作标志位不支持SIZED
// 在AbstractPipeline,previousStage指向了this,当前的节点就是StatelessOp[filter]实例,那么前驱节点this的后继节点引用nextStage就指向了StatelessOp[filter]实例
// 也就是StatelessOp[filter].previousStage = this; this.nextStage = StatelessOp[filter]; ===> 也就是这个看起来简单的new StatelessOp()其实已经把自身加入到管道中
return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SIZED) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) {
return new Sink.ChainedReference<P_OUT, P_OUT>(sink) {
@Override
public void begin(long size) {
// 这里通知下一个节点的Sink.begin(),由于filter方法不感知元素数量,所以传值-1
downstream.begin(-1);
}
@Override
public void accept(P_OUT u) {
// 基于输入的Predicate实例判断当前处理元素是否符合判断,只有判断结果为true才会把元素原封不动直接传递到下一个Sink
if (predicate.test(u))
downstream.accept(u);
}
};
}
};
}
// 暂时省略其他代码
}接着是map:
abstract class ReferencePipeline<P_IN, P_OUT>
extends AbstractPipeline<P_IN, P_OUT, Stream<P_OUT>>
implements Stream<P_OUT> {
// 暂时省略其他代码
// map操作,基于传入的Function实例做映射转换(P_OUT->R),它是一个无状态操作
@Override
@SuppressWarnings("unchecked")
public final <R> Stream<R> map(Function<? super P_OUT, ? extends R> mapper) {
Objects.requireNonNull(mapper);
// upstream为当前的ReferencePipeline实例,元素"形状"为引用类型,操作标志位不支持SORTED和DISTINCT
return new StatelessOp<P_OUT, R>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<R> sink) {
return new Sink.ChainedReference<P_OUT, R>(sink) {
@Override
public void accept(P_OUT u) {
// 基于传入的Function实例转换元素后把转换结果传递到下一个Sink
downstream.accept(mapper.apply(u));
}
};
}
};
}
// 暂时省略其他代码
}然后是sorted,sorted操作会相对复杂一点:
abstract class ReferencePipeline<P_IN, P_OUT>
extends AbstractPipeline<P_IN, P_OUT, Stream<P_OUT>>
implements Stream<P_OUT> {
// 暂时省略其他代码
// sorted操作,基于传入的Comparator实例对处理的元素进行排序,从源码中看,它是一个有状态操作
@Override
public final Stream<P_OUT> sorted(Comparator<? super P_OUT> comparator) {
return SortedOps.makeRef(this, comparator);
}
// 暂时省略其他代码
}
// SortedOps工具类
final class SortedOps {
// 暂时省略其他代码
// 构建排序操作的链节点
static <T> Stream<T> makeRef(AbstractPipeline<?, T, ?> upstream,
Comparator<? super T> comparator) {
return new OfRef<>(upstream, comparator);
}
// 有状态的排序操作节点
private static final class OfRef<T> extends ReferencePipeline.StatefulOp<T, T> {
// 是否自然排序,不定义Comparator实例的时候为true,否则为false
private final boolean isNaturalSort;
// 用于排序的Comparator实例
private final Comparator<? super T> comparator;
// 自然排序情况下的构造方法,元素"形状"为引用类型,操作标志位不支持ORDERED和SORTED
OfRef(AbstractPipeline<?, T, ?> upstream) {
super(upstream, StreamShape.REFERENCE,
StreamOpFlag.IS_ORDERED | StreamOpFlag.IS_SORTED);
this.isNaturalSort = true;
// Comparator实例赋值为Comparator.naturalOrder(),本质是基于Object中的equals或者子类覆盖Object中的equals方法进行元素排序
@SuppressWarnings("unchecked")
Comparator<? super T> comp = (Comparator<? super T>) Comparator.naturalOrder();
this.comparator = comp;
}
// 非自然排序情况下的构造方法,需要传入Comparator实例,元素"形状"为引用类型,操作标志位不支持ORDERED和SORTED
OfRef(AbstractPipeline<?, T, ?> upstream, Comparator<? super T> comparator) {
super(upstream, StreamShape.REFERENCE,
StreamOpFlag.IS_ORDERED | StreamOpFlag.NOT_SORTED);
this.isNaturalSort = false;
this.comparator = Objects.requireNonNull(comparator);
}
@Override
public Sink<T> opWrapSink(int flags, Sink<T> sink) {
Objects.requireNonNull(sink);
// If the input is already naturally sorted and this operation
// also naturally sorted then this is a no-op
// 流中的所有元素本身已经按照自然顺序排序,并且没有定义Comparator实例,则不需要进行排序,所以no op就行
if (StreamOpFlag.SORTED.isKnown(flags) && isNaturalSort)
return sink;
else if (StreamOpFlag.SIZED.isKnown(flags))
// 知道要处理的元素的确切数量,使用数组进行排序
return new SizedRefSortingSink<>(sink, comparator);
else
// 不知道要处理的元素的确切数量,使用ArrayList进行排序
return new RefSortingSink<>(sink, comparator);
}
// 这里是并行执行流中toArray方法的实现,暂不分析
@Override
public <P_IN> Node<T> opEvaluateParallel(PipelineHelper<T> helper,
Spliterator<P_IN> spliterator,
IntFunction<T[]> generator) {
// If the input is already naturally sorted and this operation
// naturally sorts then collect the output
if (StreamOpFlag.SORTED.isKnown(helper.getStreamAndOpFlags()) && isNaturalSort) {
return helper.evaluate(spliterator, false, generator);
}
else {
// @@@ Weak two-pass parallel implementation; parallel collect, parallel sort
T[] flattenedData = helper.evaluate(spliterator, true, generator).asArray(generator);
Arrays.parallelSort(flattenedData, comparator);
return Nodes.node(flattenedData);
}
}
}
// 这里考虑到篇幅太长,SizedRefSortingSink和RefSortingSink的源码不复杂,只展开RefSortingSink进行分析
// 无法确认待处理元素确切数量时候用于元素排序的Sink实现
private static final class RefSortingSink<T> extends AbstractRefSortingSink<T> {
// 临时ArrayList实例
private ArrayList<T> list;
// 构造函数,需要的参数为下一个Sink引用和Comparator实例
RefSortingSink(Sink<? super T> sink, Comparator<? super T> comparator) {
super(sink, comparator);
}
@Override
public void begin(long size) {
if (size >= Nodes.MAX_ARRAY_SIZE)
throw new IllegalArgumentException(Nodes.BAD_SIZE);
// 基于传入的size是否大于0,大于等于0用于作为initialCapacity构建ArrayList,小于0则构建默认initialCapacity的ArrayList,赋值到临时变量list
list = (size >= 0) ? new ArrayList<>((int) size) : new ArrayList<>();
}
@Override
public void end() {
// 临时的ArrayList实例基于Comparator实例进行潘旭
list.sort(comparator);
// 下一个Sink节点的激活,区分是否支持取消操作
downstream.begin(list.size());
if (!cancellationRequestedCalled) {
list.forEach(downstream::accept);
}
else {
for (T t : list) {
if (downstream.cancellationRequested()) break;
downstream.accept(t);
}
}
downstream.end();
// 激活下一个Sink完成后,临时的ArrayList实例置为NULL,便于GC回收
list = null;
}
@Override
public void accept(T t) {
// 当前Sink处理元素直接添加到临时的ArrayList实例
list.add(t);
}
}
// 暂时省略其他代码
}sorted操作有个比较显著的特点,一般的Sink处理完自身的逻辑,会在accept()方法激活下一个Sink引用,但是它在accept()方法中只做元素的累积(「元素富集」),在end()方法进行最终的排序操作和模仿Spliterator的两个元素遍历方法向downstream推送待处理的元素。示意图如下:
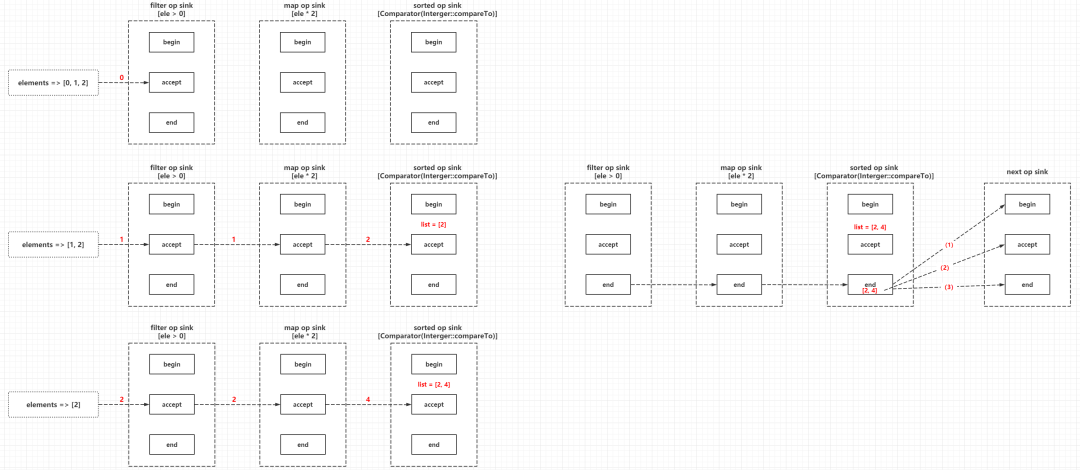
限于篇幅,这里只能挑选一部分的Terminal Op进行分析,「简单起见只分析同步执行的场景」,这里挑选最典型和最复杂的froEach()和collect(),还有比较独特的toArray()方法。先看froEach()方法的实现过程:
abstract class ReferencePipeline<P_IN, P_OUT>
extends AbstractPipeline<P_IN, P_OUT, Stream<P_OUT>>
implements Stream<P_OUT> {
// 暂时省略其他代码
// 遍历元素
@Override
public void forEach(Consumer<? super P_OUT> action) {
evaluate(ForEachOps.makeRef(action, false));
}
// 暂时省略其他代码
// 基于终结操作的求值方法
final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp) {
assert getOutputShape() == terminalOp.inputShape();
// 确保只会执行一次,linkedOrConsumed是流管道结构最后一个节点的属性
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
// 这里暂且只分析同步执行的流的终结操作,终结操作节点的标志会合并到流最后一个节点的combinedFlags中,执行的关键就是evaluateSequential方法
return isParallel()
? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags()))
: terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));
}
// 暂时省略其他代码
}
// ForEachOps类,TerminalOp接口的定义比较简单,这里不展开
final class ForEachOps {
// 暂时省略其他代码
// 构造变量元素的终结操作实例,传入的元素是T类型,结果是Void类型(返回NULL,或者说是没有返回值,毕竟是一个元素遍历过程)
// 参数为一个Consumer接口实例和一个标记是否顺序处理元素的布尔值
public static <T> TerminalOp<T, Void> makeRef(Consumer<? super T> action,
boolean ordered) {
Objects.requireNonNull(action);
return new ForEachOp.OfRef<>(action, ordered);
}
// 遍历元素操作的终结操作实现,同时它是一个适配器,适配TerminalSink(Sink)接口
abstract static class ForEachOp<T>
implements TerminalOp<T, Void>, TerminalSink<T, Void> {
// 标记是否顺序处理元素
private final boolean ordered;
protected ForEachOp(boolean ordered) {
this.ordered = ordered;
}
// TerminalOp
// 终结操作节点的标志集合,如果ordered为true则返回0,否则返回StreamOpFlag.NOT_ORDERED,表示不支持顺序处理元素
@Override
public int getOpFlags() {
return ordered ? 0 : StreamOpFlag.NOT_ORDERED;
}
// 同步遍历和处理元素
@Override
public <S> Void evaluateSequential(PipelineHelper<T> helper,
Spliterator<S> spliterator) {
// 以当前的ForEachOp实例作为最后一个Sink添加到Sink链(也就是前面经常说的元素引用链),然后对Sink链进行遍历
return helper.wrapAndCopyInto(this, spliterator).get();
}
// 并发遍历和处理元素,这里暂不分析
@Override
public <S> Void evaluateParallel(PipelineHelper<T> helper,
Spliterator<S> spliterator) {
if (ordered)
new ForEachOrderedTask<>(helper, spliterator, this).invoke();
else
new ForEachTask<>(helper, spliterator, helper.wrapSink(this)).invoke();
return null;
}
// TerminalSink
// 实现TerminalSink的方法,实际上TerminalSink继承接口Supplier,这里是实现了Supplier接口的get()方法,由于PipelineHelper.wrapAndCopyInto()方法会返回最后一个Sink的引用,这里其实就是evaluateSequential()中的返回值
@Override
public Void get() {
return null;
}
// ForEachOp的静态内部类,引用类型的ForEachOp的最终实现,依赖入参遍历元素处理的最后一步回调Consumer实例
static final class OfRef<T> extends ForEachOp<T> {
// 最后的遍历回调的Consumer句柄
final Consumer<? super T> consumer;
OfRef(Consumer<? super T> consumer, boolean ordered) {
super(ordered);
this.consumer = consumer;
}
@Override
public void accept(T t) {
// 遍历元素回调操作
consumer.accept(t);
}
}
}
}forEach终结操作实现上,自身这个操作并不会构成流的链式结构的一部分,也就是它不是一个AbstractPipeline的子类实例,而是构建一个回调Consumer实例操作的一个Sink实例(准确来说是TerminalSink)实例,这里暂且叫forEach terminal sink,通过流最后一个操作节点的wrapSink()方法,把forEach terminal sink添加到Sink链的尾部,通过流最后一个操作节点的copyInto()方法进行元素遍历,按照copyInto()方法的套路,只要多层包装的Sink方法在回调其实现方法的时候总是激活downstream的前提下,执行的顺序就是流链式结构定义的操作节点顺序,而forEach最后添加的Consumer实例一定就是最后回调的。
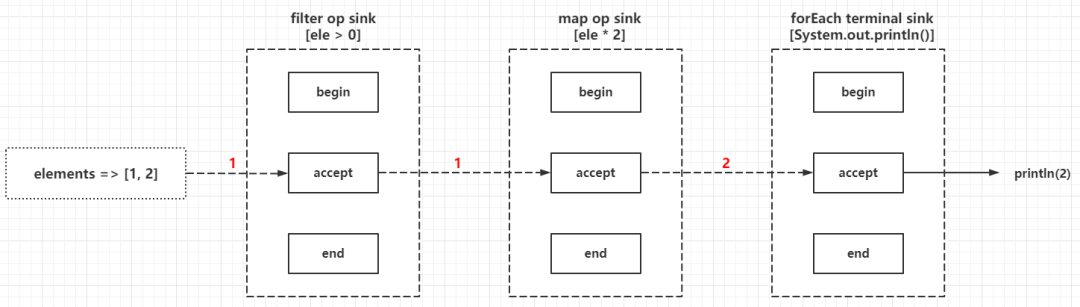
collect()方法的实现,先看Collector接口的定义:
// T:需要进行reduce操作的输入元素类型
// A:reduce操作中可变累加对象的类型,可以简单理解为累加操作中,累加到Container<A>中的可变对象类型
// R:reduce操作结果类型
public interface Collector<T, A, R> {
// 注释中称为Container,用于承载最终结果的可变容器,而此方法的Supplier实例持有的是创建Container实例的get()方法实现,后面称为Supplier
// 也就是一般使用如:Supplier<Container> supplier = () -> new Container();
Supplier<A> supplier();
// Accumulator,翻译为累加器,用于处理值并且把处理结果传递(累加)到Container中,后面称为Accumulator
BiConsumer<A, T> accumulator();
// Combiner,翻译为合并器,真实泛型类型为BinaryOperator<A,A,A>,BiFunction的子类,接收两个部分的结果并且合并为一个结果,后面称为Combiner
// 这个方法可以把一个参数的状态转移到另一个参数,然后返回更新状态后的参数,例如:(arg1, arg2) -> {arg2.state = arg1.state; return arg2;}
// 可以把一个参数的状态转移到另一个参数,然后返回一个新的容器,例如:(arg1, arg2) -> {arg2.state = arg1.state; return new Container(arg2);}
BinaryOperator<A> combiner();
// Finisher,直接翻译感觉意义不合理,实际上就是做最后一步转换工作的处理器,后面称为Finisher
Function<A, R> finisher();
// Collector支持的特性集合,见枚举Characteristics
Set<Characteristics> characteristics();
// 这里忽略两个Collector的静态工厂方法,因为并不常用
enum Characteristics {
// 标记Collector支持并发执行,一般和并发容器相关
CONCURRENT,
// 标记Collector处理元素时候无序
UNORDERED,
// 标记Collector的输入和输出元素是同类型,也就是Finisher在实现上R -> A可以等效于A -> R,unchecked cast会成功(也就是类型强转可以成功)
// 在这种场景下,对于Container来说其实类型强制转换也是等效的,也就是Supplier<A>和Supplier<R>得出的Container是同一种类型的Container
IDENTITY_FINISH
}
}
// Collector的实现Collectors.CollectorImpl
public final class Collectors {
// 这一大堆常量就是预设的多种特性组合,CH_NOID比较特殊,是空集合,也就是Collector三种特性都不支持
static final Set<Collector.Characteristics> CH_CONCURRENT_ID
= Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.CONCURRENT,
Collector.Characteristics.UNORDERED,
Collector.Characteristics.IDENTITY_FINISH));
static final Set<Collector.Characteristics> CH_CONCURRENT_NOID
= Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.CONCURRENT,
Collector.Characteristics.UNORDERED));
static final Set<Collector.Characteristics> CH_ID
= Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.IDENTITY_FINISH));
static final Set<Collector.Characteristics> CH_UNORDERED_ID
= Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.UNORDERED,
Collector.Characteristics.IDENTITY_FINISH));
static final Set<Collector.Characteristics> CH_NOID = Collections.emptySet();
static final Set<Collector.Characteristics> CH_UNORDERED_NOID
= Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.UNORDERED));
private Collectors() { }
// 省略大量代码
// 静态类,Collector的实现,实现其实就是Supplier、Accumulator、Combiner、Finisher和Characteristics集合的成员属性承载
static class CollectorImpl<T, A, R> implements Collector<T, A, R> {
private final Supplier<A> supplier;
private final BiConsumer<A, T> accumulator;
private final BinaryOperator<A> combiner;
private final Function<A, R> finisher;
private final Set<Characteristics> characteristics;
CollectorImpl(Supplier<A> supplier,
BiConsumer<A, T> accumulator,
BinaryOperator<A> combiner,
Function<A,R> finisher,
Set<Characteristics> characteristics) {
this.supplier = supplier;
this.accumulator = accumulator;
this.combiner = combiner;
this.finisher = finisher;
this.characteristics = characteristics;
}
CollectorImpl(Supplier<A> supplier,
BiConsumer<A, T> accumulator,
BinaryOperator<A> combiner,
Set<Characteristics> characteristics) {
this(supplier, accumulator, combiner, castingIdentity(), characteristics);
}
@Override
public BiConsumer<A, T> accumulator() {
return accumulator;
}
@Override
public Supplier<A> supplier() {
return supplier;
}
@Override
public BinaryOperator<A> combiner() {
return combiner;
}
@Override
public Function<A, R> finisher() {
return finisher;
}
@Override
public Set<Characteristics> characteristics() {
return characteristics;
}
}
// 省略大量代码
// IDENTITY_FINISH特性下,Finisher的实现,也就是之前提到的A->R和R->A等效,可以强转
private static <I, R> Function<I, R> castingIdentity() {
return i -> (R) i;
}
// 省略大量代码
}collect()方法的求值执行入口在ReferencePipeline中:
// ReferencePipeline
abstract class ReferencePipeline<P_IN, P_OUT>
extends AbstractPipeline<P_IN, P_OUT, Stream<P_OUT>>
implements Stream<P_OUT> {
// 暂时省略其他代码
// 基于Collector实例进行求值
public final <R, A> R collect(Collector<? super P_OUT, A, R> collector) {
A container;
// 并发求值场景暂不考虑
if (isParallel()
&& (collector.characteristics().contains(Collector.Characteristics.CONCURRENT))
&& (!isOrdered() || collector.characteristics().contains(Collector.Characteristics.UNORDERED))) {
container = collector.supplier().get();
BiConsumer<A, ? super P_OUT> accumulator = collector.accumulator();
forEach(u -> accumulator.accept(container, u));
}
else {
// 这里就是同步执行场景下的求值过程,这里可以看出其实所有Collector的求值都是Reduce操作
container = evaluate(ReduceOps.makeRef(collector));
}
// 如果Collector的Finisher输入类型和输出类型相同,所以Supplier<A>和Supplier<R>得出的Container是同一种类型的Container,可以直接类型转换,否则就要调用Collector中的Finisher进行最后一步处理
return collector.characteristics().contains(Collector.Characteristics.IDENTITY_FINISH)
? (R) container
: collector.finisher().apply(container);
}
// 暂时省略其他代码
}
// ReduceOps
final class ReduceOps {
private ReduceOps() { }
// 暂时省略其他代码
// 引用类型Reduce操作创建TerminalOp实例
public static <T, I> TerminalOp<T, I>
makeRef(Collector<? super T, I, ?> collector) {
// Supplier
Supplier<I> supplier = Objects.requireNonNull(collector).supplier();
// Accumulator
BiConsumer<I, ? super T> accumulator = collector.accumulator();
// Combiner
BinaryOperator<I> combiner = collector.combiner();
// 这里注意一点,ReducingSink是方法makeRef中的内部类,作用域只在方法内,它是封装为TerminalOp最终转化为Sink链中最后一个Sink实例的类型
class ReducingSink extends Box<I>
implements AccumulatingSink<T, I, ReducingSink> {
@Override
public void begin(long size) {
// 这里把从Supplier创建的新Container实例存放在父类Box的状态属性中
state = supplier.get();
}
@Override
public void accept(T t) {
// 处理元素,Accumulator处理状态(容器实例)和元素,这里可以想象,如果state为一个ArrayList实例,这里的accept()实现可能为add(ele)操作
accumulator.accept(state, t);
}
@Override
public void combine(ReducingSink other) {
// Combiner合并两个状态(容器实例)
state = combiner.apply(state, other.state);
}
}
return new ReduceOp<T, I, ReducingSink>(StreamShape.REFERENCE) {
@Override
public ReducingSink makeSink() {
return new ReducingSink();
}
@Override
public int getOpFlags() {
return collector.characteristics().contains(Collector.Characteristics.UNORDERED)
? StreamOpFlag.NOT_ORDERED
: 0;
}
};
}
// 暂时省略其他代码
// 继承自接口TerminalSink,主要添加了combine()抽象方法,用于合并元素
private interface AccumulatingSink<T, R, K extends AccumulatingSink<T, R, K>>
extends TerminalSink<T, R> {
void combine(K other);
}
// 状态盒,用于持有和获取状态,状态属性的修饰符为default,包内的类实例都能修改
private abstract static class Box<U> {
U state;
Box() {} // Avoid creation of special accessor
public U get() {
return state;
}
}
// ReduceOp的最终实现,这个就是Reduce操作终结操作的实现
private abstract static class ReduceOp<T, R, S extends AccumulatingSink<T, R, S>>
implements TerminalOp<T, R> {
// 流输入元素"形状"
private final StreamShape inputShape;
ReduceOp(StreamShape shape) {
inputShape = shape;
}
// 抽象方法,让子类生成终结操作的Sink
public abstract S makeSink();
// 获取流输入元素"形状"
@Override
public StreamShape inputShape() {
return inputShape;
}
// 同步执行求值,还是相似的思路,使用wrapAndCopyInto()进行Sink链构建和元素遍历
@Override
public <P_IN> R evaluateSequential(PipelineHelper<T> helper,
Spliterator<P_IN> spliterator) {
// 以当前的ReduceOp实例的makeSink()返回的Sink实例作为最后一个Sink添加到Sink链(也就是前面经常说的元素引用链),然后对Sink链进行遍历
// 这里向上一步一步推演思考,最终get()方法执行完毕拿到的结果就是ReducingSink父类Box中的state变量,也就是容器实例
return helper.wrapAndCopyInto(makeSink(), spliterator).get();
}
// 异步执行求值,暂时忽略
@Override
public <P_IN> R evaluateParallel(PipelineHelper<T> helper,
Spliterator<P_IN> spliterator) {
return new ReduceTask<>(this, helper, spliterator).invoke().get();
}
}
// 暂时省略其他代码
}接着就看Collector的静态工厂方法,看一些常用的Collector实例是如何构建的,例如看Collectors.toList():
// Supplier => () -> new ArrayList<T>(); // 初始化ArrayList
// Accumulator => (list,number) -> list.add(number); // 往ArrayList中添加元素
// Combiner => (left, right) -> { left.addAll(right); return left;} // 合并ArrayList
// Finisher => X -> X; // 输入什么就返回什么,这里实际返回的是ArrayList
public static <T>
Collector<T, ?, List<T>> toList() {
return new CollectorImpl<>((Supplier<List<T>>) ArrayList::new, List::add,
(left, right) -> { left.addAll(right); return left; },
CH_ID);
}把过程画成流程图如下:
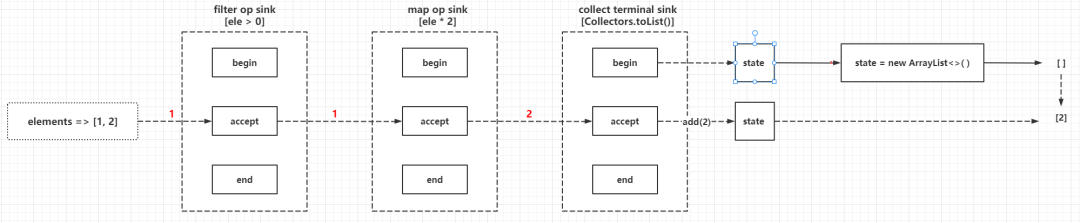
Collector这类Terminal Op的执行过程(还是以Collectors.toList()为例):
[begin]
Supplier supplier = () -> new ArrayList<T>();
Container container = supplier.get();
Box.state = container;
[accept]
Box.state.add(element);
[end]
return supplier.get(); (=> return Box.state);
↓↓↓↓↓↓↓↓↓甚至更加通俗的过程如下↓↓↓↓↓↓↓↓↓↓↓↓↓↓
ArrayList<T> container = new ArrayList<T>();
loop:
container.add(element)
return container;也就是虽然工程化的代码看起来很复杂,最终的实现就是简单的:初始化ArrayList实例由state属性持有,遍历处理元素的时候把元素添加到state中,最终返回state。最后看toArray()的方法实现(下面的方法代码没有按照实际的位置贴出,笔者把零散的代码块放在一起方便分析):
abstract class ReferencePipeline<P_IN, P_OUT>
extends AbstractPipeline<P_IN, P_OUT, Stream<P_OUT>>
implements Stream<P_OUT> {
// 暂时省略其他代码
// 流的所有元素转换为数组,这里的IntFunction有一种比较特殊的用法,就是用于创建数组实例
// 例如IntFunction<String[]> f = String::new; String[] arry = f.apply(2); 相当于String[] arry = new String[2];
@Override
@SuppressWarnings("unchecked")
public final <A> A[] toArray(IntFunction<A[]> generator) {
// 这里主动擦除了IntFunction的类型,只要保证求值的过程是正确,最终可以做类型强转
@SuppressWarnings("rawtypes")
IntFunction rawGenerator = (IntFunction) generator;
// 委托到evaluateToArrayNode()方法进行计算
return (A[]) Nodes.flatten(evaluateToArrayNode(rawGenerator), rawGenerator)
.asArray(rawGenerator);
}
// 流的所有元素转换为Object数组
@Override
public final Object[] toArray() {
return toArray(Object[]::new);
}
// 流元素求值转换为ArrayNode
final Node<E_OUT> evaluateToArrayNode(IntFunction<E_OUT[]> generator) {
// 确保不会处理多次
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
// 并发执行暂时跳过
if (isParallel() && previousStage != null && opIsStateful()) {
depth = 0;
return opEvaluateParallel(previousStage, previousStage.sourceSpliterator(0), generator);
}
else {
return evaluate(sourceSpliterator(0), true, generator);
}
}
// 最终的转换Node的方法
final <P_IN> Node<E_OUT> evaluate(Spliterator<P_IN> spliterator,
boolean flatten,
IntFunction<E_OUT[]> generator) {
// 并发执行暂时跳过
if (isParallel()) {
// @@@ Optimize if op of this pipeline stage is a stateful op
return evaluateToNode(this, spliterator, flatten, generator);
}
else {
// 兜兜转换还是回到了wrapAndCopyInto()方法,遍历Sink链,所以基本可以得知Node.Builder是Sink的一个实现
Node.Builder<E_OUT> nb = makeNodeBuilder(
exactOutputSizeIfKnown(spliterator), generator);
return wrapAndCopyInto(nb, spliterator).build();
}
}
// 获取Node的建造器实例
final Node.Builder<P_OUT> makeNodeBuilder(long exactSizeIfKnown, IntFunction<P_OUT[]> generator) {
return Nodes.builder(exactSizeIfKnown, generator);
}
// 暂时省略其他代码
}
// Node接口定义
interface Node<T> {
// 获取待处理的元素封装成的Spliterator实例
Spliterator<T> spliterator();
// 遍历当前Node实例中所有待处理的元素,回调到Consumer实例中
void forEach(Consumer<? super T> consumer);
// 获取当前Node实例的所有子Node的个数
default int getChildCount() {
return 0;
}
// 获取当前Node实例的子Node实例,入参i是子Node的索引
default Node<T> getChild(int i) {
throw new IndexOutOfBoundsException();
}
// 分割当前Node实例的一个部分,生成一个新的sub Node,类似于ArrayList中的subList方法
default Node<T> truncate(long from, long to, IntFunction<T[]> generator) {
if (from == 0 && to == count())
return this;
Spliterator<T> spliterator = spliterator();
long size = to - from;
Node.Builder<T> nodeBuilder = Nodes.builder(size, generator);
nodeBuilder.begin(size);
for (int i = 0; i < from && spliterator.tryAdvance(e -> { }); i++) { }
if (to == count()) {
spliterator.forEachRemaining(nodeBuilder);
} else {
for (int i = 0; i < size && spliterator.tryAdvance(nodeBuilder); i++) { }
}
nodeBuilder.end();
return nodeBuilder.build();
}
// 创建一个包含当前Node实例所有元素的元素数组视图
T[] asArray(IntFunction<T[]> generator);
//
void copyInto(T[] array, int offset);
// 返回Node实例基于Stream的元素"形状"
default StreamShape getShape() {
return StreamShape.REFERENCE;
}
// 获取当前Node实例包含的元素个数
long count();
// Node建造器,注意这个Node.Builder接口是继承自Sink,那么其子类实现都可以添加到Sink链中作为一个节点(终结节点)
interface Builder<T> extends Sink<T> {
// 创建Node实例
Node<T> build();
// 基于Integer元素类型的特化类型Node.Builder
interface OfInt extends Node.Builder<Integer>, Sink.OfInt {
@Override
Node.OfInt build();
}
// 基于Long元素类型的特化类型Node.Builder
interface OfLong extends Node.Builder<Long>, Sink.OfLong {
@Override
Node.OfLong build();
}
// 基于Double元素类型的特化类型Node.Builder
interface OfDouble extends Node.Builder<Double>, Sink.OfDouble {
@Override
Node.OfDouble build();
}
}
// 暂时省略其他代码
}
// 这里下面的方法来源于Nodes类
final class Nodes {
// 暂时省略其他代码
// Node扁平化处理,如果传入的Node实例存在子Node实例,则使用fork-join对Node进行分割和并发计算,结果添加到IntFunction生成的数组中,如果不存在子Node,直接返回传入的Node实例
// 关于并发计算部分暂时不分析
public static <T> Node<T> flatten(Node<T> node, IntFunction<T[]> generator) {
if (node.getChildCount() > 0) {
long size = node.count();
if (size >= MAX_ARRAY_SIZE)
throw new IllegalArgumentException(BAD_SIZE);
T[] array = generator.apply((int) size);
new ToArrayTask.OfRef<>(node, array, 0).invoke();
return node(array);
} else {
return node;
}
}
// 创建Node的建造器实例
static <T> Node.Builder<T> builder(long exactSizeIfKnown, IntFunction<T[]> generator) {
// 当知道待处理元素的准确数量并且小于允许创建的数组的最大长度MAX_ARRAY_SIZE(Integer.MAX_VALUE - 8),使用FixedNodeBuilder(固定长度数组Node建造器),否则使用SpinedNodeBuilder实例
return (exactSizeIfKnown >= 0 && exactSizeIfKnown < MAX_ARRAY_SIZE)
? new FixedNodeBuilder<>(exactSizeIfKnown, generator)
: builder();
}
// 创建Node的建造器实例,使用SpinedNodeBuilder的实例,此SpinedNode支持元素添加,但是不支持元素移除
static <T> Node.Builder<T> builder() {
return new SpinedNodeBuilder<>();
}
// 固定长度固定长度数组Node实现(也就是最终的Node实现是一个ArrayNode,最终的容器为一个T类型元素的数组T[])
private static final class FixedNodeBuilder<T>
extends ArrayNode<T>
implements Node.Builder<T> {
// 基于size(元素个数,或者说创建数组的长度)和数组创建方法IntFunction构建FixedNodeBuilder实例
FixedNodeBuilder(long size, IntFunction<T[]> generator) {
super(size, generator);
assert size < MAX_ARRAY_SIZE;
}
// 返回当前FixedNodeBuilder实例,判断数组元素计数值curSize必须大于等于实际数组容器中元素的个数
@Override
public Node<T> build() {
if (curSize < array.length)
throw new IllegalStateException(String.format("Current size %d is less than fixed size %d",
curSize, array.length));
return this;
}
// Sink的begin方法回调,传入的size必须和数组长度相等,因为后面的accept()方法会执行size此
@Override
public void begin(long size) {
if (size != array.length)
throw new IllegalStateException(String.format("Begin size %d is not equal to fixed size %d",
size, array.length));
// 重置数组元素计数值为0
curSize = 0;
}
// Sink的accept方法回调,当数组元素计数值小于数组长度,直接向数组下标curSize++添加传入的元素
@Override
public void accept(T t) {
if (curSize < array.length) {
array[curSize++] = t;
} else {
throw new IllegalStateException(String.format("Accept exceeded fixed size of %d",
array.length));
}
}
// Sink的end方法回调,再次判断数组元素计数值curSize必须大于等于实际数组容器中元素的个数
@Override
public void end() {
if (curSize < array.length)
throw new IllegalStateException(String.format("End size %d is less than fixed size %d",
curSize, array.length));
}
// 返回FixedNodeBuilder当前信息,当前处理的下标和当前数组中所有的元素
@Override
public String toString() {
return String.format("FixedNodeBuilder[%d][%s]",
array.length - curSize, Arrays.toString(array));
}
}
// Node实现,容器为一个固定长度的数组
private static class ArrayNode<T> implements Node<T> {
// 数组容器
final T[] array;
// 数组容器中当前元素的个数,这个值是一个固定值,或者在FixedNodeBuilder的accept()方法回调中递增
int curSize;
// 基于size和数组创建的工厂IntFunction构建ArrayNode实例
@SuppressWarnings("unchecked")
ArrayNode(long size, IntFunction<T[]> generator) {
if (size >= MAX_ARRAY_SIZE)
throw new IllegalArgumentException(BAD_SIZE);
// 创建szie长度的数组容器
this.array = generator.apply((int) size);
this.curSize = 0;
}
// 这个方法是基于一个现成的数组创建ArrayNode实例,直接改变数组的引用为array,元素个数curSize置为输入参数长度
ArrayNode(T[] array) {
this.array = array;
this.curSize = array.length;
}
// Node - 接下来是Node接口的实现
// 基于数组实例,起始索引0和结束索引curSize构造一个全新的Spliterator实例
@Override
public Spliterator<T> spliterator() {
return Arrays.spliterator(array, 0, curSize);
}
// 拷贝array中的元素到外部传入的dest数组中
@Override
public void copyInto(T[] dest, int destOffset) {
System.arraycopy(array, 0, dest, destOffset, curSize);
}
// 返回元素数组视图,这里直接返回array引用
@Override
public T[] asArray(IntFunction<T[]> generator) {
if (array.length == curSize) {
return array;
} else {
throw new IllegalStateException();
}
}
// 获取array中的元素个数
@Override
public long count() {
return curSize;
}
// 遍历array,每个元素回调Consumer实例
@Override
public void forEach(Consumer<? super T> consumer) {
for (int i = 0; i < curSize; i++) {
consumer.accept(array[i]);
}
}
// 返回ArrayNode当前信息,当前处理的下标和当前数组中所有的元素
@Override
public String toString() {
return String.format("ArrayNode[%d][%s]",
array.length - curSize, Arrays.toString(array));
}
}
// 暂时省略其他代码
}很多集合容器的Spliterator其实并不支持SIZED特性,其实Node的最终实现很多情况下都是Nodes.SpinedNodeBuilder,因为SpinedNodeBuilder重实现实现了数组扩容和Spliterator基于数组进行分割的方法,源码相对复杂(特别是spliterator()方法),这里挑部分进行分析,由于SpinedNodeBuilder绝大部分方法都是使用父类SpinedBuffer中的实现,这里可以直接分析SpinedBuffer:
// SpinedBuffer的当前数组在超过了元素数量阈值之后,会拆分为多个数组块,存储到spine中,而curChunk引用指向的是当前处理的数组块
class SpinedBuffer<E>
extends AbstractSpinedBuffer
implements Consumer<E>, Iterable<E> {
// 暂时省略其他代码
// 当前的数组块
protected E[] curChunk;
// 所有数组块
protected E[][] spine;
// 构造函数,指定初始化容量
SpinedBuffer(int initialCapacity) {
super(initialCapacity);
curChunk = (E[]) new Object[1 << initialChunkPower];
}
// 构造函数,指定默认初始化容量
@SuppressWarnings("unchecked")
SpinedBuffer() {
super();
curChunk = (E[]) new Object[1 << initialChunkPower];
}
// 拷贝当前SpinedBuffer中的数组元素到传入的数组实例
public void copyInto(E[] array, int offset) {
// 计算最终的offset,区分单个chunk和多个chunk的情况
long finalOffset = offset + count();
if (finalOffset > array.length || finalOffset < offset) {
throw new IndexOutOfBoundsException("does not fit");
}
// 单个chunk的情况,由curChunk最接拷贝
if (spineIndex == 0)
System.arraycopy(curChunk, 0, array, offset, elementIndex);
else {
// 多个chunk的情况,由遍历spine并且对每个chunk进行拷贝
// full chunks
for (int i=0; i < spineIndex; i++) {
System.arraycopy(spine[i], 0, array, offset, spine[i].length);
offset += spine[i].length;
}
if (elementIndex > 0)
System.arraycopy(curChunk, 0, array, offset, elementIndex);
}
}
// 返回数组元素视图,基于IntFunction构建数组实例,使用copyInto()方法进行元素拷贝
public E[] asArray(IntFunction<E[]> arrayFactory) {
long size = count();
if (size >= Nodes.MAX_ARRAY_SIZE)
throw new IllegalArgumentException(Nodes.BAD_SIZE);
E[] result = arrayFactory.apply((int) size);
copyInto(result, 0);
return result;
}
// 清空SpinedBuffer,清空分块元素和所有引用
@Override
public void clear() {
if (spine != null) {
curChunk = spine[0];
for (int i=0; i<curChunk.length; i++)
curChunk[i] = null;
spine = null;
priorElementCount = null;
}
else {
for (int i=0; i<elementIndex; i++)
curChunk[i] = null;
}
elementIndex = 0;
spineIndex = 0;
}
// 遍历元素回调Consumer,分别遍历spine和curChunk
@Override
public void forEach(Consumer<? super E> consumer) {
// completed chunks, if any
for (int j = 0; j < spineIndex; j++)
for (E t : spine[j])
consumer.accept(t);
// current chunk
for (int i=0; i<elementIndex; i++)
consumer.accept(curChunk[i]);
}
// Consumer的accept实现,最终会作为Sink接口的accept方法调用
@Override
public void accept(E e) {
// 如果当前分块(第一个)的元素已经满了,就初始化spine,然后元素添加到spine[0]中
if (elementIndex == curChunk.length) {
inflateSpine();
// 然后元素添加到spine[0]中的元素已经满了,就新增spine[n],把元素放进spine[n]中
if (spineIndex+1 >= spine.length || spine[spineIndex+1] == null)
increaseCapacity();
elementIndex = 0;
++spineIndex;
// 当前的chunk更新为最新的chunk,就是spine中的最新一个chunk
curChunk = spine[spineIndex];
}
// 当前的curChunk添加元素
curChunk[elementIndex++] = e;
}
// 暂时省略其他代码
}源码已经基本分析完毕,下面还是用一个例子转化为流程图:
如果流实例调用了parallel(),注释中提到会返回一个异步执行流的变体,实际上并没有构造变体,只是把sourceStage.parallel标记为true,异步求值的基本过程是:构建流管道结构的时候和同步求值的过程一致,构建完Sink链之后,Spliterator会使用特定算法基于trySplit()进行自分割,自分割算法由具体的子类决定,例如ArrayList采用的就是二分法,分割完成后每个Spliterator持有所有元素中的一小部分,然后把每个Spliterator作为sourceSpliterator在fork-join线程池中执行Sink链,得到多个部分的结果在当前调用线程中聚合,得到最终结果。这里用到的技巧就是:线程封闭和fork-join。因为不同Terminal Op的并发求值过程大同小异,这里只分析forEach并发执行的实现。首先展示一个使用fork-join线程池的简单例子:
public class MapReduceApp {
public static void main(String[] args) {
// 数组中每个元素*2,再求和
Integer result = new MapReducer<>(new Integer[]{1, 2, 3, 4}, x -> x * 2, Integer::sum).invoke();
System.out.println(result);
}
interface Mapper<S, T> {
T apply(S source);
}
interface Reducer<S, T> {
T apply(S first, S second);
}
public static class MapReducer<T> extends CountedCompleter<T> {
final T[] array;
final Mapper<T, T> mapper;
final Reducer<T, T> reducer;
final int lo, hi;
MapReducer<T> sibling;
T result;
public MapReducer(T[] array,
Mapper<T, T> mapper,
Reducer<T, T> reducer) {
this.array = array;
this.mapper = mapper;
this.reducer = reducer;
this.lo = 0;
this.hi = array.length;
}
public MapReducer(CountedCompleter<?> p,
T[] array,
Mapper<T, T> mapper,
Reducer<T, T> reducer,
int lo,
int hi) {
super(p);
this.array = array;
this.mapper = mapper;
this.reducer = reducer;
this.lo = lo;
this.hi = hi;
}
@Override
public void compute() {
if (hi - lo >= 2) {
int mid = (lo + hi) >> 1;
MapReducer<T> left = new MapReducer<>(this, array, mapper, reducer, lo, mid);
MapReducer<T> right = new MapReducer<>(this, array, mapper, reducer, mid, hi);
left.sibling = right;
right.sibling = left;
// 创建子任务父任务的pending计数器加1
setPendingCount(1);
// 提交右子任务
right.fork();
// 在当前线程计算左子任务
left.compute();
} else {
if (hi > lo) {
result = mapper.apply(array[lo]);
}
// 叶子节点完成,尝试合并其他兄弟节点的结果,会调用onCompletion方法
tryComplete();
}
}
@Override
public T getRawResult() {
return result;
}
@SuppressWarnings("unchecked")
@Override
public void onCompletion(CountedCompleter<?> caller) {
if (caller != this) {
MapReducer<T> child = (MapReducer<T>) caller;
MapReducer<T> sib = child.sibling;
// 合并子任务结果,只有两个子任务
if (Objects.isNull(sib) || Objects.isNull(sib.result)) {
result = child.result;
} else {
result = reducer.apply(child.result, sib.result);
}
}
}
}
}这里简单使用了fork-join编写了一个简易的MapReduce应用,main方法中运行的是数组[1,2,3,4]中的所有元素先映射为i -> i * 2,再进行reduce(求和)的过程,代码中也是简单使用二分法对原始的array进行分割,当最终的任务只包含一个元素,也就是lo < hi且hi - lo == 1的时候,会基于单个元素调用Mapper的方法进行完成通知tryComplete(),任务完成会最终通知onCompletion()方法,Reducer就是在此方法中进行结果的聚合操作。对于流的并发求值来说,过程是类似的,ForEachOp中最终调用ForEachOrderedTask或者ForEachTask,这里挑选ForEachTask进行分析:
abstract static class ForEachOp<T>
implements TerminalOp<T, Void>, TerminalSink<T, Void> {
// 暂时省略其他代码
@Override
public <S> Void evaluateParallel(PipelineHelper<T> helper,
Spliterator<S> spliterator) {
if (ordered)
new ForEachOrderedTask<>(helper, spliterator, this).invoke();
else
// 最终是调用ForEachTask的invoke方法,invoke会阻塞到所有fork任务执行完,获取最终的结果
new ForEachTask<>(helper, spliterator, helper.wrapSink(this)).invoke();
return null;
}
// 暂时省略其他代码
}
// ForEachOps类
final class ForEachOps {
private ForEachOps() { }
// forEach的fork-join任务实现,没有覆盖getRawResult()方法,最终只会返回NULL
static final class ForEachTask<S, T> extends CountedCompleter<Void> {
// Spliterator实例,如果是父任务则代表所有待处理的元素,如果是子任务则是一个分割后的新Spliterator实例
private Spliterator<S> spliterator;
// Sink链实例
private final Sink<S> sink;
// 流管道引用
private final PipelineHelper<T> helper;
// 目标数量,其实是每个任务处理元素数量的建议值
private long targetSize;
// 这个构造器是提供给父(根)任务
ForEachTask(PipelineHelper<T> helper,
Spliterator<S> spliterator,
Sink<S> sink) {
super(null);
this.sink = sink;
this.helper = helper;
this.spliterator = spliterator;
this.targetSize = 0L;
}
// 这个构造器是提供给子任务,所以需要父任务的引用和一个分割后的新Spliterator实例作为参数
ForEachTask(ForEachTask<S, T> parent, Spliterator<S> spliterator) {
super(parent);
this.spliterator = spliterator;
this.sink = parent.sink;
this.targetSize = parent.targetSize;
this.helper = parent.helper;
}
// Similar to AbstractTask but doesn't need to track child tasks
// 实现compute方法,用于分割Spliterator成多个子任务,这里不需要跟踪所有子任务
public void compute() {
// 神奇的赋值,相当于Spliterator<S> rightSplit = spliterator; Spliterator<S> leftSplit;
// rightSplit总是指向当前的spliterator实例
Spliterator<S> rightSplit = spliterator, leftSplit;
// 这里也是神奇的赋值,相当于long sizeEstimate = rightSplit.estimateSize(); long sizeThreshold;
long sizeEstimate = rightSplit.estimateSize(), sizeThreshold;
// sizeThreshold赋值为targetSize
if ((sizeThreshold = targetSize) == 0L)
// 基于Spliterator分割后的右分支实例的元素数量重新赋值sizeThreshold和targetSize
// 计算方式是待处理元素数量/(fork-join线程池并行度<<2)或者1(当前一个计算方式结果为0的时候)
targetSize = sizeThreshold = AbstractTask.suggestTargetSize(sizeEstimate);
// 当前的流是否支持SHORT_CIRCUIT,也就是短路特性
boolean isShortCircuit = StreamOpFlag.SHORT_CIRCUIT.isKnown(helper.getStreamAndOpFlags());
// 当前的任务是否fork右分支
boolean forkRight = false;
// taskSink作为Sink的临时变量
Sink<S> taskSink = sink;
// 当前任务的临时变量
ForEachTask<S, T> task = this;
// Spliterator分割和创建新的fork任务ForEachTask,前提是不支持短路或者Sink不支持取消
while (!isShortCircuit || !taskSink.cancellationRequested()) {
// 当前的任务中的Spliterator(rightSplit)中的待处理元素小于等于每个任务应该处理的元素阈值或者再分割后得到NULL,则不需要再分割,直接基于rightSplit和Sink链执行循环处理元素
if (sizeEstimate <= sizeThreshold || (leftSplit = rightSplit.trySplit()) == null) {
// 这里就是遍历rightSplit元素回调Sink链的操作
task.helper.copyInto(taskSink, rightSplit);
break;
}
// rightSplit还能分割,则基于分割后的leftSplit和以当前任务作为父任务创建一个新的fork任务
ForEachTask<S, T> leftTask = new ForEachTask<>(task, leftSplit);
// 待处理子任务加1
task.addToPendingCount(1);
// 需要fork的任务实例临时变量
ForEachTask<S, T> taskToFork;
// 因为rightSplit总是分割Spliterator后对应原来的Spliterator引用,而leftSplit总是trySplit()后生成的新的Spliterator
// 所以这里leftSplit也需要作为rightSplit进行分割,通俗来说就是周星驰007那把梅花间足发射的枪
if (forkRight) {
// 这里交换leftSplit为rightSplit,所以forkRight设置为false,下一轮循环相当于fork left
forkRight = false;
rightSplit = leftSplit;
taskToFork = task;
// 赋值下一轮的父Task为当前的fork task
task = leftTask;
}
else {
forkRight = true;
taskToFork = leftTask;
}
// 添加fork任务到任务队列中
taskToFork.fork();
// 其实这里是更新剩余待分割的Spliterator中的所有元素数量到sizeEstimate
sizeEstimate = rightSplit.estimateSize();
}
// 置空spliterator实例并且传播任务完成状态,等待所有任务执行完成
task.spliterator = null;
task.propagateCompletion();
}
}
}上面的源码分析看起来可能比较难理解,这里举个简单的例子:
public static void main(String[] args) throws Exception {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.stream().parallel().forEach(System.out::println);
}这段代码中最终转换成ForEachTask中评估后得到的targetSize = sizeThreshold == 1,当前调用线程会参与计算,会执行3次fork,也就是一共有4个处理流程实例(也就是原始的Spliterator实例最终会分割出3个全新的Spliterator实例,加上自身一个4个Spliterator实例),每个处理流程实例只处理1个元素,对应的流程图如下:
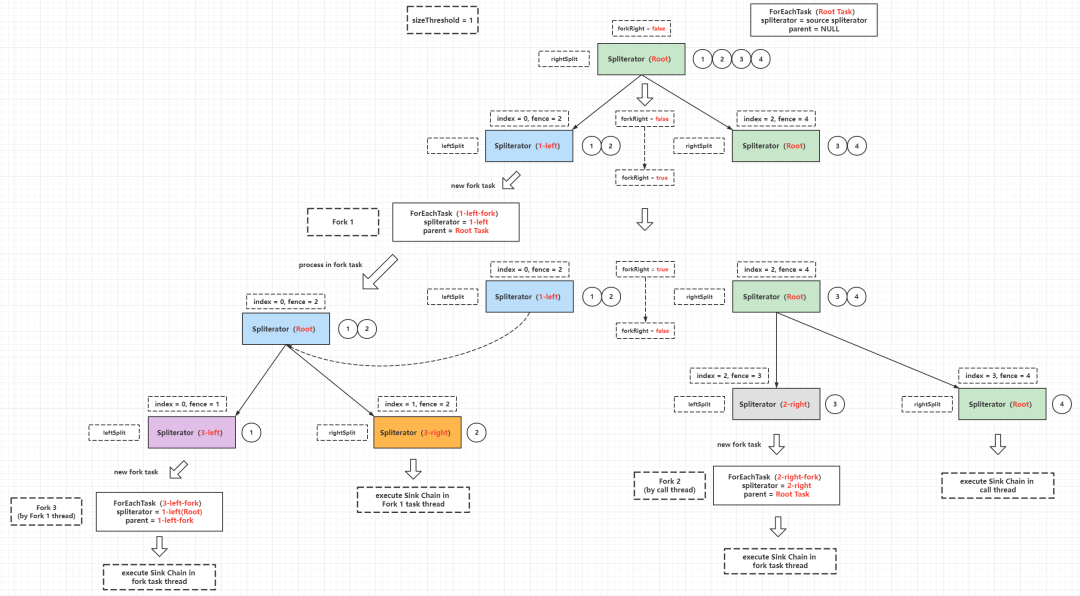
CountedCompleter.invoke()方法获取的,此方法会阻塞直到所有子任务处理完成,当然forEach终结操作不需要返回值,所以没有实现getRawResult()方法,这里只是为了阻塞到所有任务执行完毕才解除调用线程的阻塞状态。
Stream中按照「中间操作」是否有状态可以把这些操作分为「无状态操作」和「有状态操作」。Stream中按照「终结操作」是否支持短路特性可以把这些操作分为「非短路操作」和「短路操作」。理解如下:
filter、map等操作sort、limit等操作,以sort操作为例,一般是把所有待处理的元素全部添加到一个容器如ArrayList,再进行所有元素的排序,然后再重新模拟Spliterator把元素推送到后一个节点forEachanyMatch(实际上anyMatch会遍历完所有的元素,不过在命中了短路条件下,元素回调Sink.accept()方法时候会基于stop短路标记跳过具体的处理流程)这里不展开源码进行分析,仅仅展示一个经常见到的Stream操作汇总表如下:
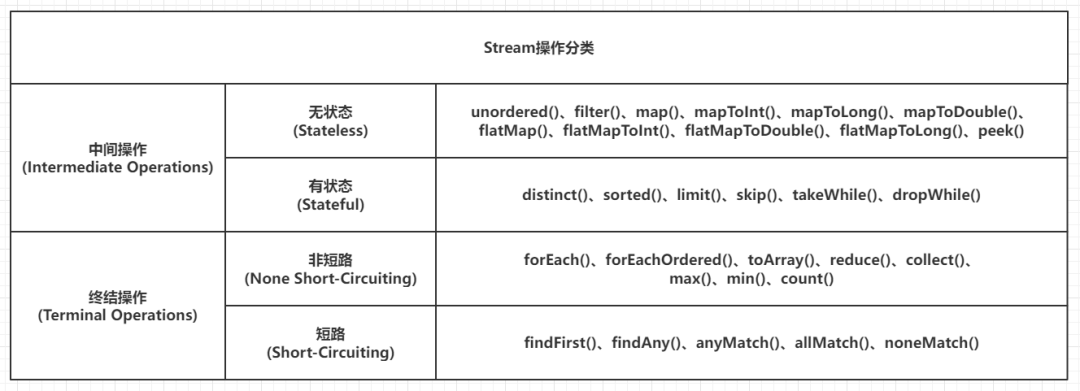
slice和while相关操作find相关终结操作中findFirst、findAny均支持和判断StreamOpFlag.SHORT_CIRCUIT,而match相关终结操作是通过内部的临时状态stop和value进行短路控制前前后后写了十多万字,其实也仅仅相对浅层次介绍了Stream的基本实现,笔者认为很多没分析到的中间操作实现和终结操作实现,特别是并发执行的终结操作实现是十分复杂的,多线程环境下需要进行一些想象和多处DEBUG定位执行位置和推演执行的过程。简单总结一下:
JDK中Stream的实现是精炼的高度工程化代码Stream的载体虽然是AbstractPipeline,管道结构,但是只用其型,实际求值操作之前会转化为一个多层包裹的Sink结构,也就是前文一直说的Sink链,从编程模式来看,应用的是Reactor编程模式Stream目前支持的固有求值执行结构一定是Head(Source Spliterator) -> Op -> Op ... -> Terminal Op的形式,这算是一个局限性,没有办法做到像LINQ那样可以灵活实现类似内存视图的功能Stream目前支持并发求值方案是针对Source Spliterator进行分割,封装Terminal Op和固定Sink链构造的ForkJoinTask进行并发计算,调用线程和fork-join线程池中的工作线程都可以参与求值过程,笔者认为这部分是Stream中除了那些标志集合位运算外最复杂的实现Stream实现的功能是一个突破,也有人说过此功能是一个"早产儿",在此希望JDK能够在矛盾螺旋中前进和发展本文由哈喽比特于3年以前收录,如有侵权请联系我们。
文章来源:https://mp.weixin.qq.com/s/J_A_nL-QDSzZmTKhD-Nung
京东创始人刘强东和其妻子章泽天最近成为了互联网舆论关注的焦点。有关他们“移民美国”和在美国购买豪宅的传言在互联网上广泛传播。然而,京东官方通过微博发言人发布的消息澄清了这些传言,称这些言论纯属虚假信息和蓄意捏造。
日前,据博主“@超能数码君老周”爆料,国内三大运营商中国移动、中国电信和中国联通预计将集体采购百万台规模的华为Mate60系列手机。
据报道,荷兰半导体设备公司ASML正看到美国对华遏制政策的负面影响。阿斯麦(ASML)CEO彼得·温宁克在一档电视节目中分享了他对中国大陆问题以及该公司面临的出口管制和保护主义的看法。彼得曾在多个场合表达了他对出口管制以及中荷经济关系的担忧。
今年早些时候,抖音悄然上线了一款名为“青桃”的 App,Slogan 为“看见你的热爱”,根据应用介绍可知,“青桃”是一个属于年轻人的兴趣知识视频平台,由抖音官方出品的中长视频关联版本,整体风格有些类似B站。
日前,威马汽车首席数据官梅松林转发了一份“世界各国地区拥车率排行榜”,同时,他发文表示:中国汽车普及率低于非洲国家尼日利亚,每百户家庭仅17户有车。意大利世界排名第一,每十户中九户有车。
近日,一项新的研究发现,维生素 C 和 E 等抗氧化剂会激活一种机制,刺激癌症肿瘤中新血管的生长,帮助它们生长和扩散。
据媒体援引消息人士报道,苹果公司正在测试使用3D打印技术来生产其智能手表的钢质底盘。消息传出后,3D系统一度大涨超10%,不过截至周三收盘,该股涨幅回落至2%以内。
9月2日,坐拥千万粉丝的网红主播“秀才”账号被封禁,在社交媒体平台上引发热议。平台相关负责人表示,“秀才”账号违反平台相关规定,已封禁。据知情人士透露,秀才近期被举报存在违法行为,这可能是他被封禁的部分原因。据悉,“秀才”年龄39岁,是安徽省亳州市蒙城县人,抖音网红,粉丝数量超1200万。他曾被称为“中老年...
9月3日消息,亚马逊的一些股东,包括持有该公司股票的一家养老基金,日前对亚马逊、其创始人贝索斯和其董事会提起诉讼,指控他们在为 Project Kuiper 卫星星座项目购买发射服务时“违反了信义义务”。
据消息,为推广自家应用,苹果现推出了一个名为“Apps by Apple”的网站,展示了苹果为旗下产品(如 iPhone、iPad、Apple Watch、Mac 和 Apple TV)开发的各种应用程序。
特斯拉本周在美国大幅下调Model S和X售价,引发了该公司一些最坚定支持者的不满。知名特斯拉多头、未来基金(Future Fund)管理合伙人加里·布莱克发帖称,降价是一种“短期麻醉剂”,会让潜在客户等待进一步降价。
据外媒9月2日报道,荷兰半导体设备制造商阿斯麦称,尽管荷兰政府颁布的半导体设备出口管制新规9月正式生效,但该公司已获得在2023年底以前向中国运送受限制芯片制造机器的许可。
近日,根据美国证券交易委员会的文件显示,苹果卫星服务提供商 Globalstar 近期向马斯克旗下的 SpaceX 支付 6400 万美元(约 4.65 亿元人民币)。用于在 2023-2025 年期间,发射卫星,进一步扩展苹果 iPhone 系列的 SOS 卫星服务。
据报道,马斯克旗下社交平台𝕏(推特)日前调整了隐私政策,允许 𝕏 使用用户发布的信息来训练其人工智能(AI)模型。新的隐私政策将于 9 月 29 日生效。新政策规定,𝕏可能会使用所收集到的平台信息和公开可用的信息,来帮助训练 𝕏 的机器学习或人工智能模型。
9月2日,荣耀CEO赵明在采访中谈及华为手机回归时表示,替老同事们高兴,觉得手机行业,由于华为的回归,让竞争充满了更多的可能性和更多的魅力,对行业来说也是件好事。
《自然》30日发表的一篇论文报道了一个名为Swift的人工智能(AI)系统,该系统驾驶无人机的能力可在真实世界中一对一冠军赛里战胜人类对手。
近日,非营利组织纽约真菌学会(NYMS)发出警告,表示亚马逊为代表的电商平台上,充斥着各种AI生成的蘑菇觅食科普书籍,其中存在诸多错误。
社交媒体平台𝕏(原推特)新隐私政策提到:“在您同意的情况下,我们可能出于安全、安保和身份识别目的收集和使用您的生物识别信息。”
2023年德国柏林消费电子展上,各大企业都带来了最新的理念和产品,而高端化、本土化的中国产品正在不断吸引欧洲等国际市场的目光。
罗永浩日前在直播中吐槽苹果即将推出的 iPhone 新品,具体内容为:“以我对我‘子公司’的了解,我认为 iPhone 15 跟 iPhone 14 不会有什么区别的,除了序(列)号变了,这个‘不要脸’的东西,这个‘臭厨子’。