上周刚在公司进行了一次 React 运行时优化方案的分享,以下是分享的文字版,文章比较长,干货也很多,相信你看完后会对 React 有不一样的理解。
就在前两个月,React 刚刚发布了 18 版本,记得上一次详细阅读 React 源码,还是在三年前,当时读的是 React 的 15 版本,那时候主要是去研究了一下,当时的 虚拟 DOM 的渲染机制、setState 的执行机制,以及 React 的合成事件,也写了下面几篇 React 的文章:
当时研究完了之后,不禁感叹,以后再也不读 React 源码了,相比其他框架,React 的源码实在是太难读了。
但是,后面随着 React 16-18 的更新,React 的底层架构发生了非常大的变化,也带了非常多有意思的新特性,这些特性在老的架构下肯定是实现不了的。这也重新勾起了我的好奇心,React 源码究竟发生了哪些变化,于是下定决心再读一遍最新版本的源码。
好在前人栽树、后人乘凉,社区里有很多大牛已经做过了非常好的源码解读,比如卡颂的 React 技术揭秘、7kms 的 图解React源码 。根据这些教程,我重新梳理了新版 React 架构的源码划分,重新走了一遍整体的流程,并且对重要的模块进行了自己阅读和研究。
再出一个新的源码解读系列,我觉得没有必要,前面两位已经做的很好了,但是,我希望用更简短的方式帮大家分析和解读一下 React 主要的发展方向、最近的几次重大更新,都做了什么。
从 16 年到现在,React 经历了 15-18 几个大的版本,除了 Hooks,React 在新特性上几乎没有什么大的更新,直到前段时间,沉寂了很久的 React 终于有了一波新的 API。
但是,在之前的几个版本他也没有闲着,给我们造了很多概念,Concurrent Mode、Fiber、Suspense、lanes、Scheduler、Concurrent Rendering ,这些概念让一些新手开发者望而却步。
这篇文章的主要目,就是根据 React 主要优化策略几个阶段的演进,来把这些概念梳理清楚,看看 React 这几年到底在搞什么东西,以及顺便解读一下最新更新的这些特性。在分享里面我们可能不会很详细的去分析具体的调度流程和细节,但是我们会在一些优化策略上节选一些源码进行解读。
那么,为什么本篇文章的主题是运行时呢?我们先来看看几大框架在设计上的对比。

React,React 是一个重运行时的框架,在数据发生变化后,并没有直接去操作 dom,而是生成一个新的所谓的虚拟 dom,它可以帮助我们解决跨平台和兼容性问题,并且通过 diff 算法得出最小的操作行为,这些全部都是在运行时来做的。
最近很火的 Svelte ,就是一个典型的重编译的框架,作为开发者我们只需要去写模版和数据,经过 Svelte 的编译和预处理,代码基本全部会解析成原生的 DOM 操作,Svelte 的性能也是最接近原生 js 的。
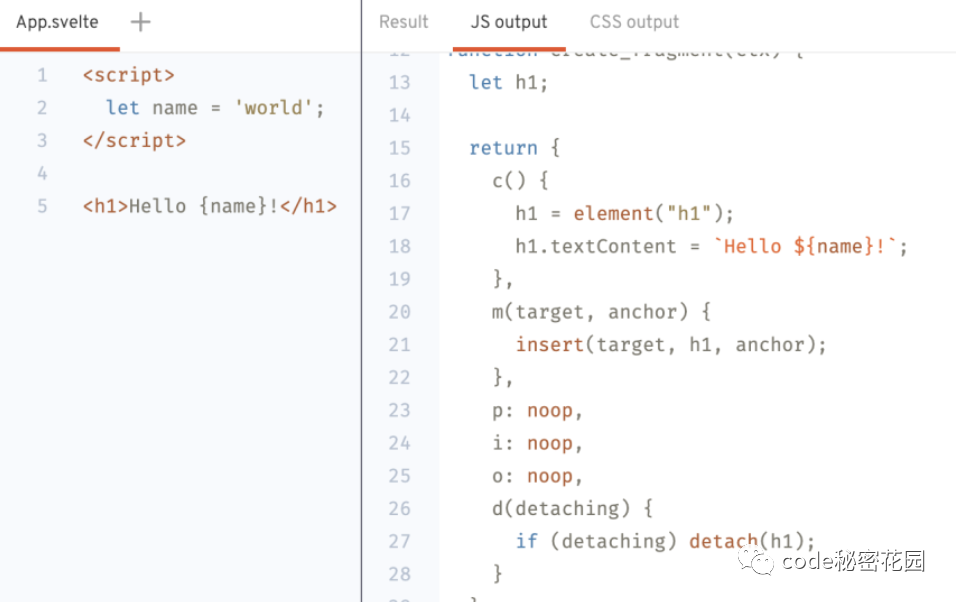
Vue 这个框架,在运行时和预编译取了一个很好地权衡,它保留了虚拟 dom,但是会通过响应式去控制虚拟 dom 的颗粒度,在预编译里面,又做了足够多的性能优化,做到了按需更新。
那么,下面我们再来看看,什么是编译时的优化。
Vue 使用的是模版语法,模版 的特点,就是语法受限,我们可以使用 v-if v-for 这些指定的语法去编码,虽然这不够动态,但是由于语法是可枚举的,所以它可以在预编译层面做更多的预判,让 Vue 在运行时有更好的性能。下面我们可以看一个 Vue 3.0 具体在编译时所做的优化。

vdom 的 Diff 算法总归要按照 vdom 树的层级结构一层一层的遍历,所以 diff 性能会和模版的大小正相关,跟动态节点的数量无关。在一些组件整个模版内只有少量动态节点的情况下,这些遍历都是性能的浪费。
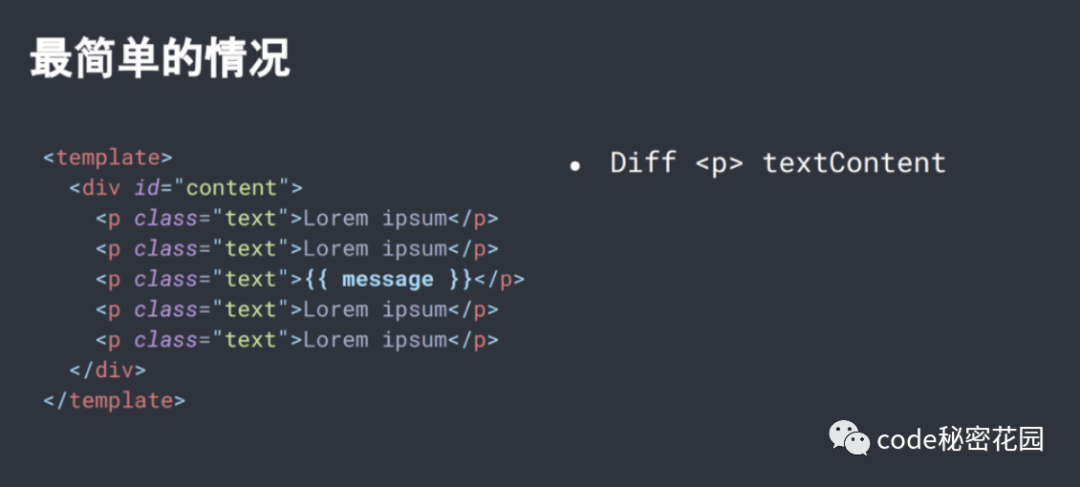
diff 阶段跳过静态内容,那我们就可以避免无用的 dom 树的遍历和比对。
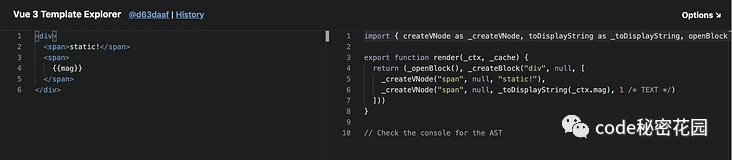
Vue3.0 里面,就有这样一条类似的优化策略,它的 compiler 可以根据节点的动态属性,为每个 虚拟 dom 创建不同的 patchflag,比如说,节点具有动态的 text,或者具有动态的 class,都会被打上不同的 patchflag。
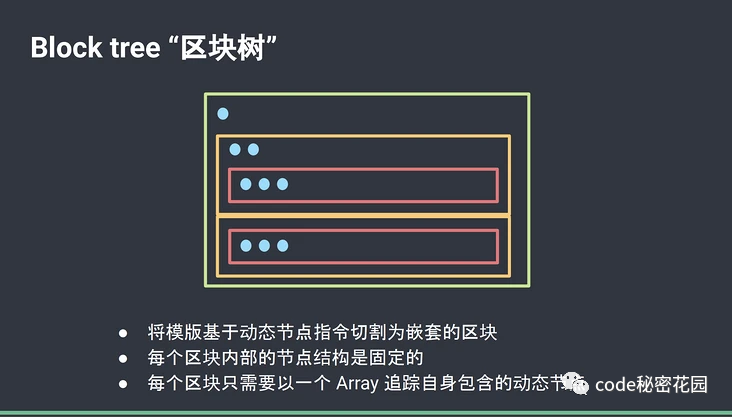
patchflag 再配合 block tree,就可以做到对不同节点的靶向更新。

React ,它本身的思路是纯 JS 写法,这种方式非常灵活,但是,这也使它在编译时很难做太多的事情,像上面这样的编译时优化是很难实现的。所以,我们可以看到 React 几个大版本的的优化主要都在运行时。
那么,运行时我们主要关注什么问题呢?
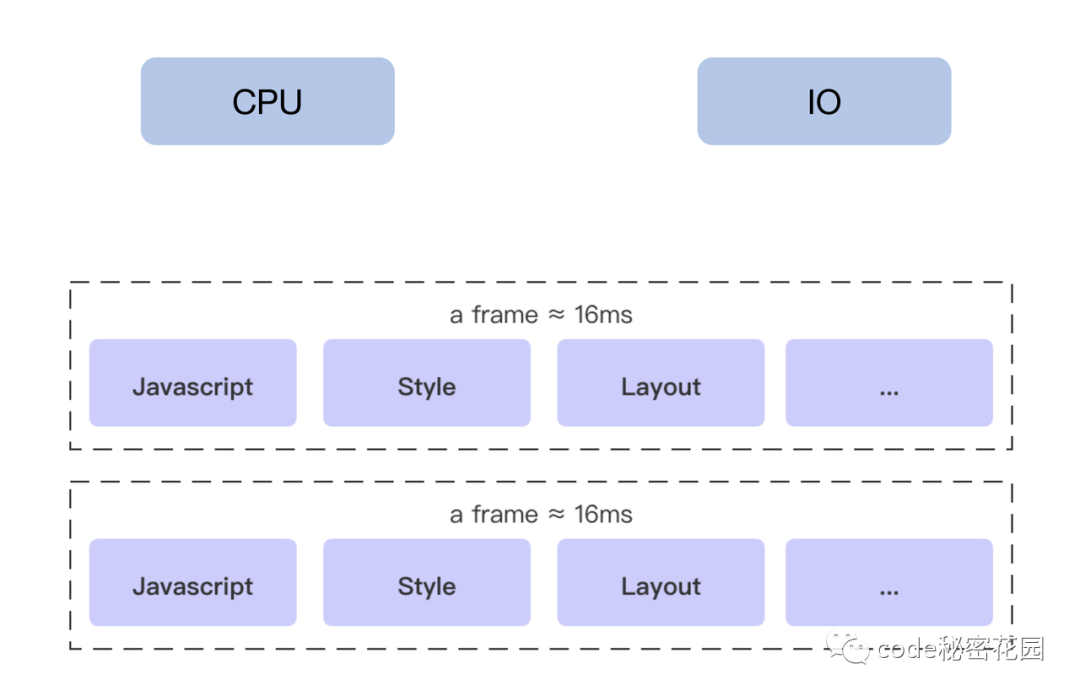
60Hz,也就是每秒刷新 60 次,大概 16.6ms 浏览器刷新一次。由于 GUI 渲染线程和 JS 线程是互斥的,所以 JS 脚本执行和浏览器布局、绘制不能同时执行。
在这 16.6ms 的时间里,浏览器既需要完成 JS 的执行,也需要完成样式的重排和重绘,如果 JS 执行的时间过长,超出了 16.6ms,这次刷新就没有时间执行样式布局和样式绘制了,于是在页面上就会表现为卡顿。
IO 的问题就比较好理解了,很多组件需要等待一些网络延迟,那么怎么样才能在网络延迟存在的情况下,减少用户对网络延迟的感知呢?就是我们需要解决的问题。
好,刚才我们聊完了为什么 React 主要的优化策略都在运行时,以及运行时主要解决的问题,下面我们就来具体看一下,React 最近的这几个大的版本都有什么更新和变化。
我们先来看看 React 15 ,React 应该就是在这个版本之后开始火起来的,也是在这个版本之后,React 的更新也变得越来越慢。
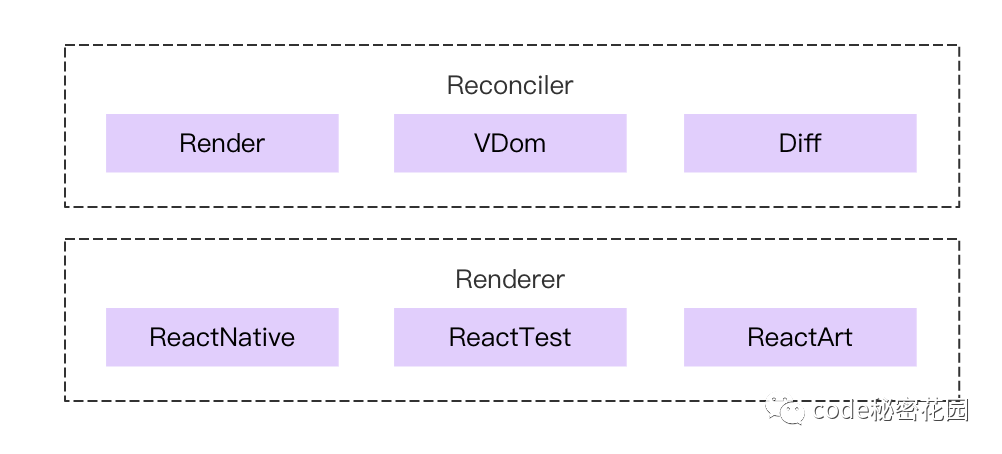
这一版的架构,还比较简单,主要就是分 Reconciler 和 Renderer 两个部分。
Reconciler(协调器)—— 负责调用 render 生成虚拟 Dom 进行 Diff,找出变化后的虚拟 DomRenderer(渲染器)—— 负责接到 Reconciler 通知,将变化的组件渲染在当前宿主环境,比如浏览器,不同的宿主环境会有不同的 Renderer。下面我们来回顾一下,React 15 引入的一项优化:批处理,一道 React 的经典面试题:「setState 到底是同步的还是异步的」就是来源于此,我面试的时候也会经常问,具体的我在两年前的一篇文章中有介绍过:[由实际问题探究 setState 的执行机制] 。
比如下面的代码,在一个生命周期里调用了四次 setState,其中最后两次在 setTimeout 的回调中。
class Example extends React.Component {
constructor() {
super();
this.state = {
val: 0
};
}
componentDidMount() {
this.setState({val: this.state.val + 1});
console.log(this.state.val);
this.setState({val: this.state.val + 1});
console.log(this.state.val);
setTimeout(() => {
this.setState({val: this.state.val + 1});
console.log(this.state.val);
this.setState({val: this.state.val + 1};
console.log(this.state.val);
}, 0);
}
render() {
return null;
}
};我们来考虑一下两种情况:
React 完全没有批处理机制,那么执行一个 setState 就会立即触发一次页面渲染,打印顺序应该是 1、2、3、4React 有一个完美的批处理机制,那么应该等整个函数执行完了之后再统一处理所有渲染,打印顺序应该是 0、0、0、0实际上,在这个版本上面代码的打印顺序是 0、0、2、3,从 setTimeout 回调里的打印结果我们就可以看出,setState 调用本身就是同步的,而外面之所以不能立即拿到结果就是因为 React 的批处理机制。
正是因为 setState 是同步的,当同时触发多次 setState 时浏览器会一直被JS线程阻塞,那么那么浏览器就会掉帧,导致页面卡顿,所以 React 才引入了批处理的机制,主要是为了将同一上下文中触发的更新合并为一个更新。
我们可以来看下源码中 _processPendingState 这个函数,这个函数是用来合并 state 暂存队列的,最后返回一个合并后的 state。
_processPendingState: function (props, context) {
var inst = this._instance;
var queue = this._pendingStateQueue;
var replace = this._pendingReplaceState;
this._pendingReplaceState = false;
this._pendingStateQueue = null;
if (!queue) {
return inst.state;
}
if (replace && queue.length === 1) {
return queue[0];
}
var nextState = _assign({}, replace ? queue[0] : inst.state);
for (var i = replace ? 1 : 0; i < queue.length; i++) {
var partial = queue[i];
_assign(nextState, typeof partial === 'function' ? partial.call(inst, nextState, props, context) : partial);
}
return nextState;
},我们只需要关注下面这段代码:
_assign(nextState, typeof partial === 'function' ? partial.call(inst, nextState, props, context) : partial);
如果传入的是对象,很明显会被合并成一次:
Object.assign(
nextState,
{index: state.index+ 1},
{index: state.index+ 1}
)如果传入的是函数,函数的参数 preState 是前一次合并后的结果,所以计算结果是准确的。
如果在需要处理批处理的环境中(React生命周期、合成事件中)无论调用多少次 setState,都会不会执行更新,而是将要更新的 state 存入 _pendingStateQueue,将要更新的组件存入 dirtyComponent。当上一次更新机制执行完毕,以生命周期为例,所有组件,即最顶层组件 didmount 后会将 isBranchUpdate 设置为false。这时将执行之前累积的 setState。
React 内部会通过一个 batchedUpdates 函数去调用所有需要批处理的函数,执行逻辑大概如下:
batchedUpdates(onClick, e);
export function batchedUpdates<A, R>(fn: A => R, a: A): R {
// ...
try {
return fn(a);
} finally {
// ....
}
}因为 batchedUpdates 本身是同步调用的,如果 fn 内部有异步执行,这时批处理早已执行完,所以这个版本的批处理无法处理异步函数,也被称作是半自动批处理。
所以呢,React 给我们提供了 unstable batchedUpdates 这样的函数支持我们手动执行批处理。

React 15 中引入批处理这样的优化逻辑,但是由于 React 15 本身的架构是递归同步更新的,如果节点非常多,即使只有一次 state 变更,React 也需要进行复杂的递归更新,更新一旦开始,中途就无法中断,直到遍历完整颗树,才能释放主线程。

16ms ,如果这时有用户操作或动画渲染等,就会表现为卡顿。
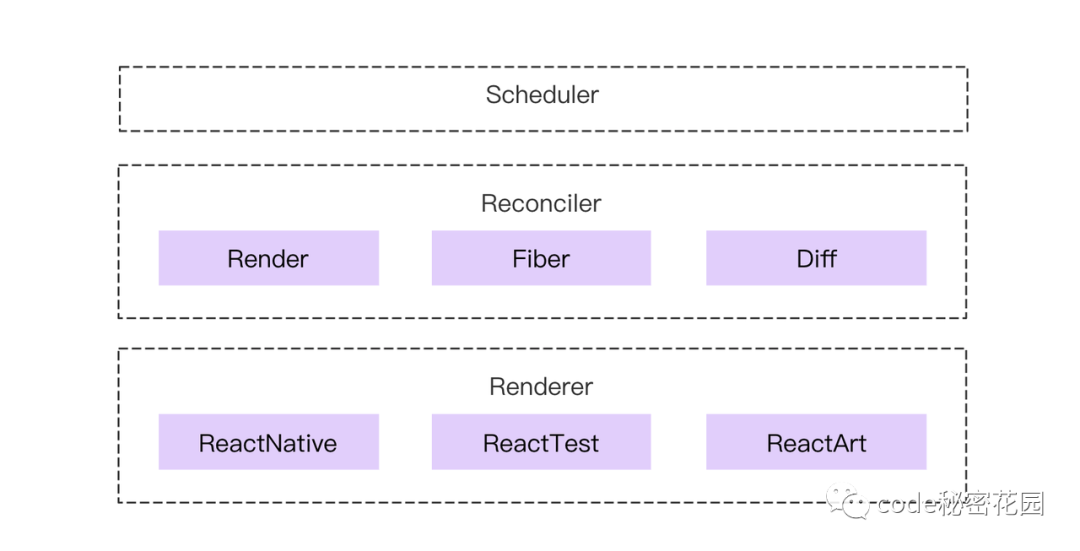
下面,我们再来看看 React 16 这个版本,相比 React 15,我们可以看到新的架构中多了一层 Scheduler,也就是调度器,然后在 Reconciler 这一层,使用 Fiber 架构进行了重构。具体的细节我们会在后面的章节进介绍。
Scheduler(调度器)—— 调度任务的优先级,高优任务优先进入 ReconcilerReconciler(协调器)—— 负责找出变化的组件(使用 Fiber 重构)Renderer(渲染器)—— 负责将变化的组件渲染到页面上React ,也在后续的几个大版本中,都沿用了这个架构。
除了架构上的变化,React 在这个版本提出了一个非常重要的概念,Concurrent Mode。
React 官方的描述,是这样的:
Concurrent 模式是一组 React 的新功能,可帮助应用保持响应,并根据用户的设备性能和网速进行适当的调整。
为了让应用保持响应,我们需要先了解是什么在制约应用保持响应?
里面比较重点的就是,让应用保持响应,我们可以先想一下到底是啥在限制应用保持响应呢?
在上面的章节中,我们,我们也提到了,在运行时的主要瓶颈就是 CPU、IO ,如果能够破这两个瓶颈,就可以实现应用的保持响应。
在 CPU 上,我们的主要问题是,在 JS 执行超过 16.6 ms 时,页面就会产生卡顿,那么 React 的解决思路,就是在浏览器每一帧的时间中预留一些时间给 JS 线程,React 利用这部分时间更新组件。当预留的时间不够用时,React 将线程控制权交还给浏览器让他有时间渲染UI,React 则等待下一帧再继续被中断的工作。
其实,上面我们提到的,这种将长任务分拆到每一帧中,每一帧执行一小段任务的操作,就是我们常说的时间切片。
那么在 IO 上面,需要解决的是发送网络请求后,由于需要等待数据返回才能进一步操作导致不能快速响应的问题。React 希望通过控制组件渲染的优先级去解决这个问题。
实际上,Concurrent Mode 就是为了解决以上两个问题而设计的一套新的架构,重点就是,让组件的渲染 “可中断” 并且具有 “优先级”,其中包括几个不同的模块,他们各自负责不同的工作。首先,我们先来看看,如何让组件的渲染 “可中断” 呢?
在上面的章节我们讲到 React15 的 Reconciler 采用递归的方式执行,数据保存在递归调用栈中,这种递归的遍历方式肯定是无法中断的。
所以,React 花费2年时间重构完成了Fiber架构,React16 的 Reconciler 基于 Fiber 节点实现。每个 Fiber 节点对应一个 React element,注意一下,这里是对应,而不是等于。我们调用 render 函数产生的结果是 React element,而 Fiber 节点,由 React Element 创建而来。
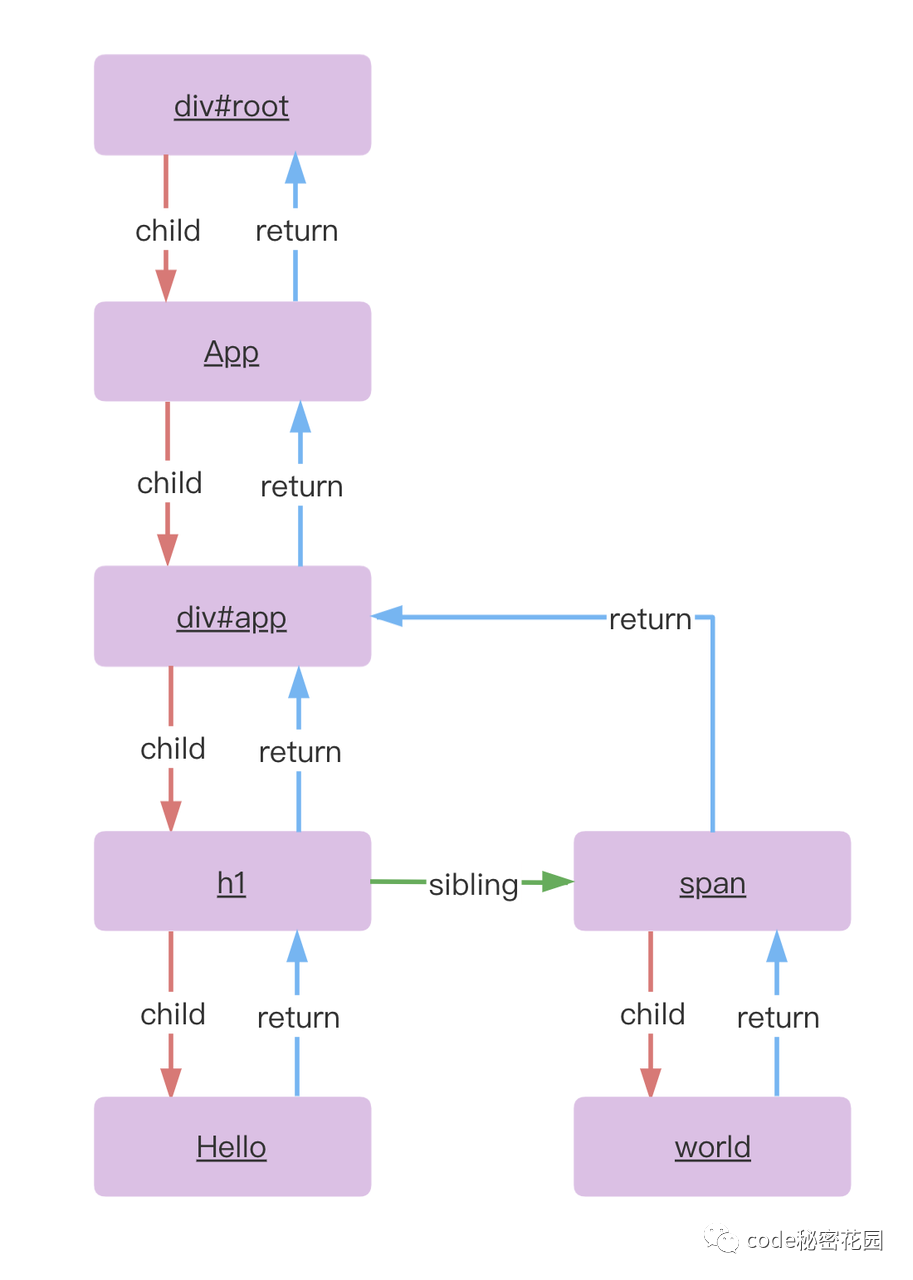
Fiber 节点的示例,除了包含 组件的类型,组件对应的 DOM 信息之外,Fiber 节点还保存了本次更新中该组件改变的状态、要执行的工作,需要被删除,被插入页面中,还是被更新。
function FiberNode(
tag: WorkTag,
pendingProps: mixed,
key: null | string,
mode: TypeOfMode,
) {
// 作为静态数据结构的属性
this.tag = tag;
this.key = key;
this.elementType = null;
this.type = null;
this.stateNode = null;
// 用于连接其他Fiber节点形成Fiber树
this.return = null;
this.child = null;
this.sibling = null;
this.index = 0;
this.ref = null;
// 动态工作单元的属性
this.pendingProps = pendingProps;
this.memoizedProps = null;
this.updateQueue = null;
this.memoizedState = null;
this.dependencies = null;
this.mode = mode;
this.effectTag = NoEffect;
this.nextEffect = null;
this.firstEffect = null;
this.lastEffect = null;
// 调度优先级相关
this.lanes = NoLanes;
this.childLanes = NoLanes;
// 指向该fiber在另一次更新时对应的fiber
this.alternate = null;
}另外,我们还可以看到当前节点与其他节点的链接关系,一个 Fiber 节点包括了他的 child(第一个子节点)、sibling(兄弟节点)、return(父节点)等属性。
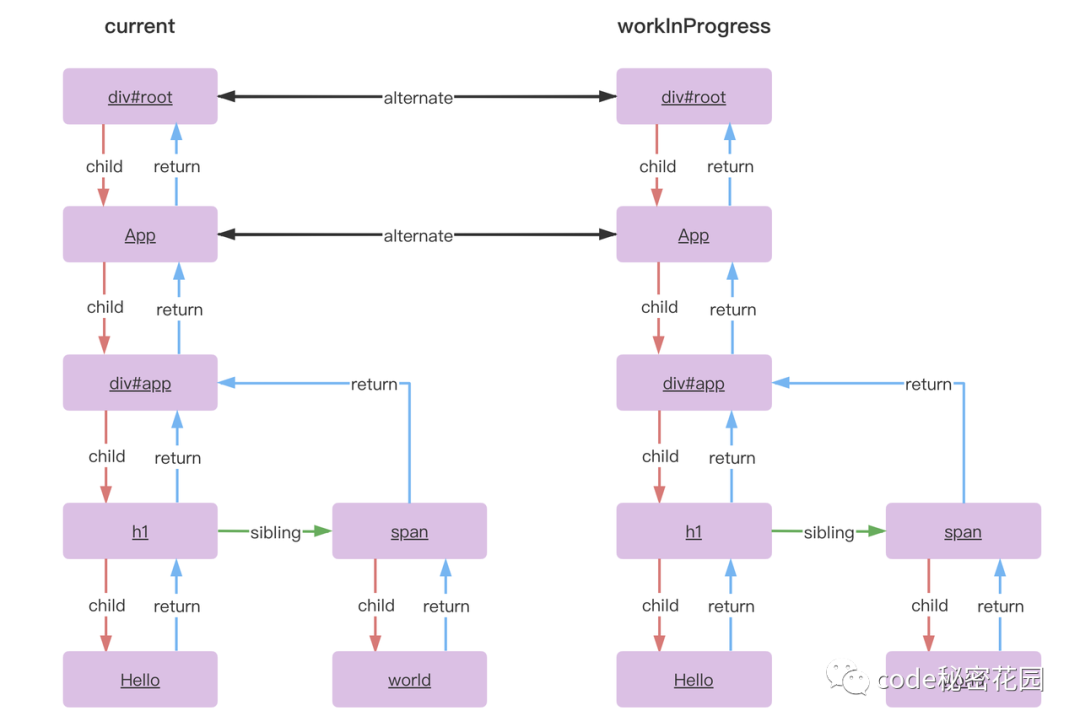
React 中最多会同时存在两棵Fiber树。当前屏幕上显示内容对应的Fiber树叫做 current Fiber 树,正在内存中构建的Fiber树叫做 workInProgress Fiber树,他们通过一个 alternate 属性连接。
React应用的根节点会使用一个 current 指针指向当前的 current Fiber 树。当 workInProgress Fiber 树构建完成交给 Renderer 渲染在页面上后,应用根节点的 current 指针就会 指向 workInProgress Fiber 树,此时 workInProgress Fiber 树就变为 current Fiber 树。
由于 React 将渲染 DOM 树的机制改成了两个 Fiber 树交替工作的形式,所以可以在更新全部完成之后再切换指针指向,而在指针切换之前,我们随时可以放弃对另一颗树的修改。这,就让更新可中断成为了可能。
在上面,我们提到了几个概念,current Fiber、workInProgress Fiber、jsx 对象 也就是 React Element、还有真正的 DOM 节点。
那么,Reconciler 的工作就是使用 Diff 算法对比 current Fiber 和 React Element ,生成 workInProgress Fiber ,这个阶段是可中断的,Renderer 的工作是把 workInProgress Fiber 转换成真正的 DOM 节点。
如果我们,还是用 ReactDOM.render 去同步运行 Fiber 架构,则 Fiber 架构与重构前并无区别。但是当我们配合上面提到的时间切片,就可以根据当前的宿主环境性能,为每个工作单元分配一个可运行时间,从而实现“异步可中断的更新”。

Scheduler 就可以帮我们完成这件事情,我们可以看到,我们一次耗时很长的更新任务被拆分成一小段一小段的。这样浏览器就有剩余时间执行样式布局和样式绘制,减少掉帧的可能性。


requestIdleCallback 函数,在这个函数里我们可以拿到浏览器当前一祯的剩余时间。
那这个 API 可以用来干啥呢?我们来看一个例子:

16.6ms 的。
这里我们借助 requestIdleCallback 这个函数,可以将一个大任务分割成多个个小任务,在每一帧有空余时间情况下,逐步去执行小任务。
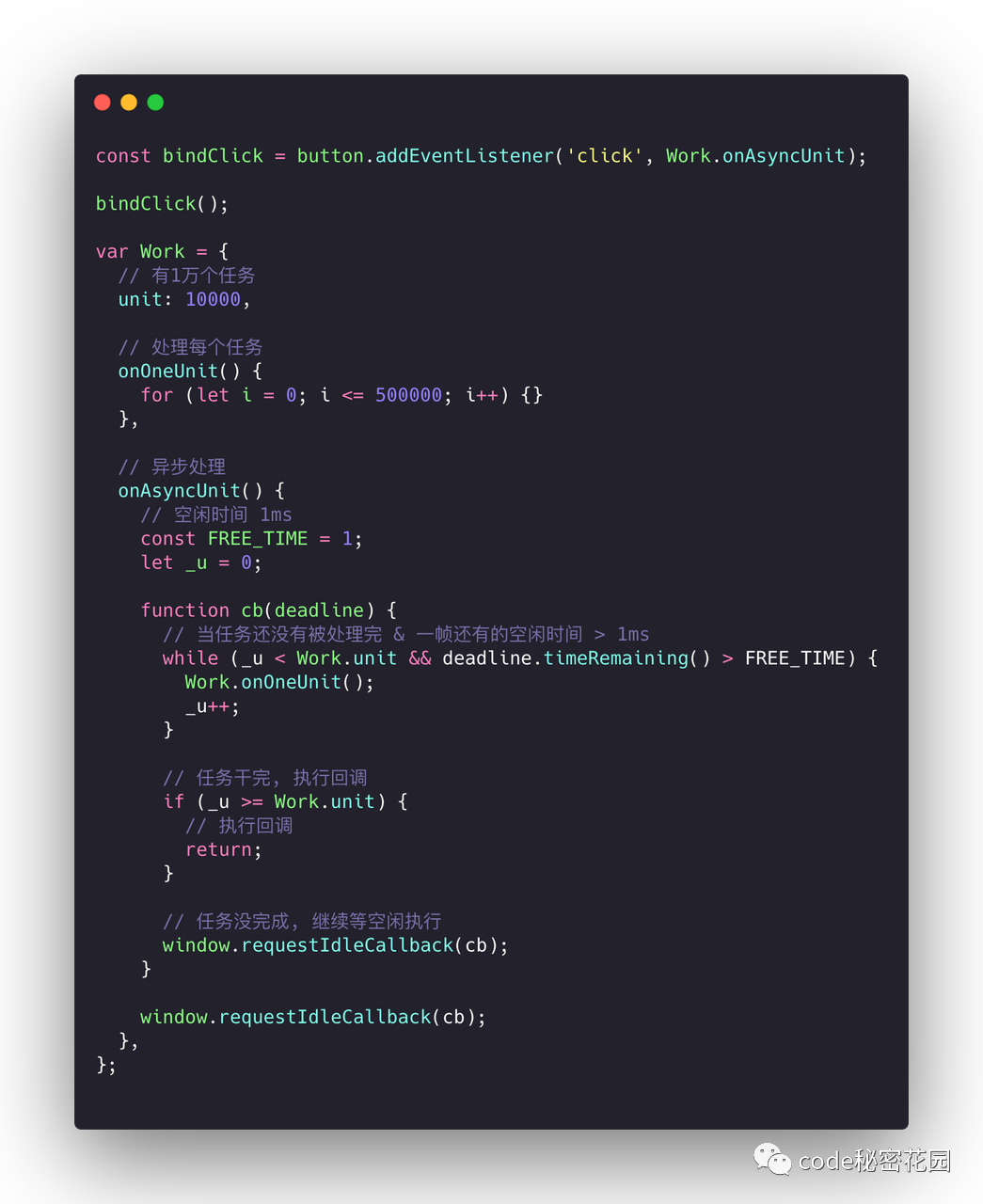
API ,我们就可以让浏览器仅在空闲时期的时候执行脚本。时间切片的本质,也就是模拟实现 requestIdleCallback 这个函数。
由于兼容性和刷新帧率的问题,
React并没有直接使用requestIdleCallback, 而是使用了MessageChannel模拟实现,原理是一样的。
在 React 的 render 阶段,开启 Concurrent Mode 时,每次遍历前,都会通过 Scheduler 提供的 shouldYield 方法判断是否需要中断遍历,使浏览器有时间渲染,参考下面的 workLoopConcurrent 函数。
function workLoopConcurrent() {
// Perform work until Scheduler asks us to yield
while (workInProgress !== null && !shouldYield()) {
performUnitOfWork(workInProgress);
}
}是否中断的判断依据,最重要的一点便是每个任务的剩余时间是否用完,shouldYield() 函数的作用就是检查时间是否到期。
shouldYield(...) --> Scheduler_shouldYield(...) --> unstable_shouldYield(...)
--> shouldYieldToHost(...)
--> getCurrentTime() >= deadline
-->
var yieldInterval = 5; var deadline = 0;
var performWorkUntilDeadline = function() {
...
var currentTime = getCurrentTime()
deadline = currentTime + yieldInterval
...
}可以看到,在 Schdeduler 中,那么每次到期,就会跳出工作循环,把线程的控制权交给浏览器,然后下次任务再继续当前的工作。这样,一个长的 JS 任务就会被切割成多个小段的任务。
下面我们可以看下这段代码,yieldInterval 会根据当前设备的 fps 进行动态计算,这就响应了前面我们提到了 Concurrent Mode 这个概念的的定义,帮助应用保持响应,并根据用户的设备性能和网速进行适当的调整。
if (fps > 0) {
yieldInterval = Math.floor(1000 / fps);
} else {
// reset the framerate
yieldInterval = 5;
}Fiber 架构配合 Scheduler 实现了 Concurrent Mode 的底层 — “异步可中断的更新”。
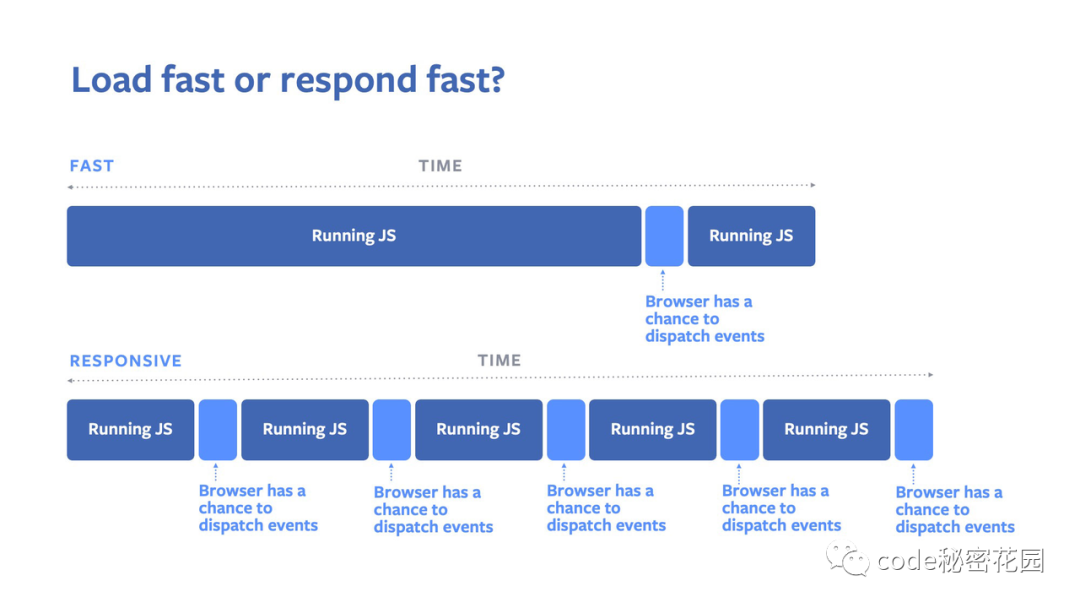
React 的时候才能享受到这个优化策略。
在 Chrome 87 版本,React 团队和 Chrome 团队合作,在浏览器上加入了一个新的 API isInputPending。这也是第一个将中断这个操作系统概念用于网页开发的API。
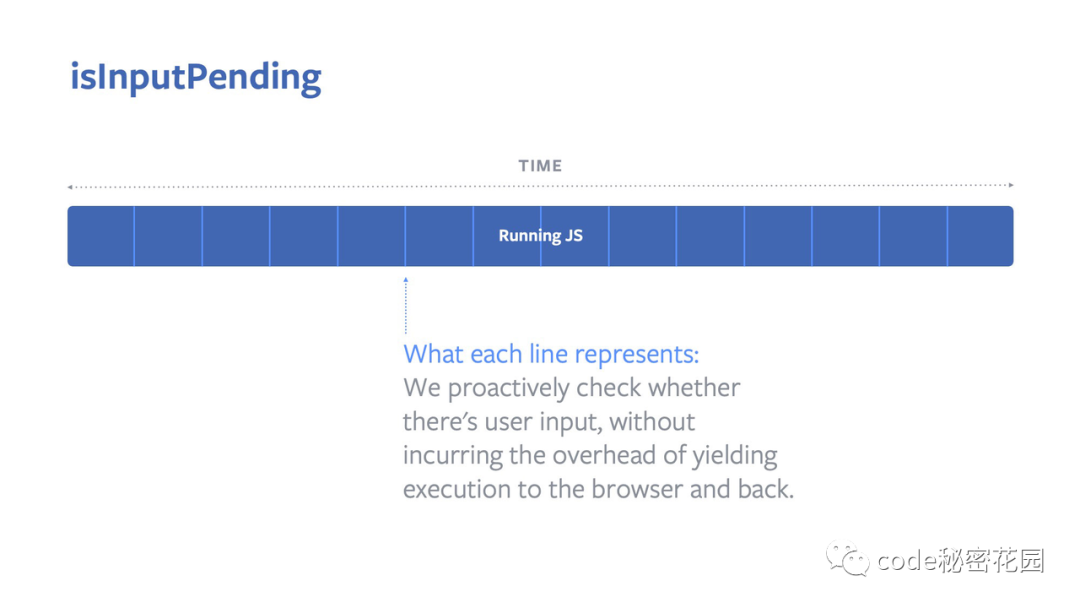
React,我们也可以利用这个 API,来平衡 JS 执行、页面渲染及用户输入之间的优先级。

isInputPending 方法,我们可以在页面渲染的时候及时响应用户输入,并且,当有长耗时的JS任务要执行时,可以通过 isInputPending 来中断JS的执行,将控制权交还给浏览器来执行用户响应。
如果一次更新在运行过程中被中断,然后重新开始一次新的更新,我们可以说:后一次更新打断了前一次更新。
举一个简单的例子,我们现在正在吃饭,突然你女朋友给你打电话,你可能要先中断吃饭的操作,接完电话,再继续吃饭。
也就是说,接电话这个操作的优先级,就要高于吃饭的优先级。React 根据人机交互的研究结果,为不同场景下产生的状态更新,赋予了不同的优先级,比如:
suspense、transition 这样的更新,是低优先级执行的。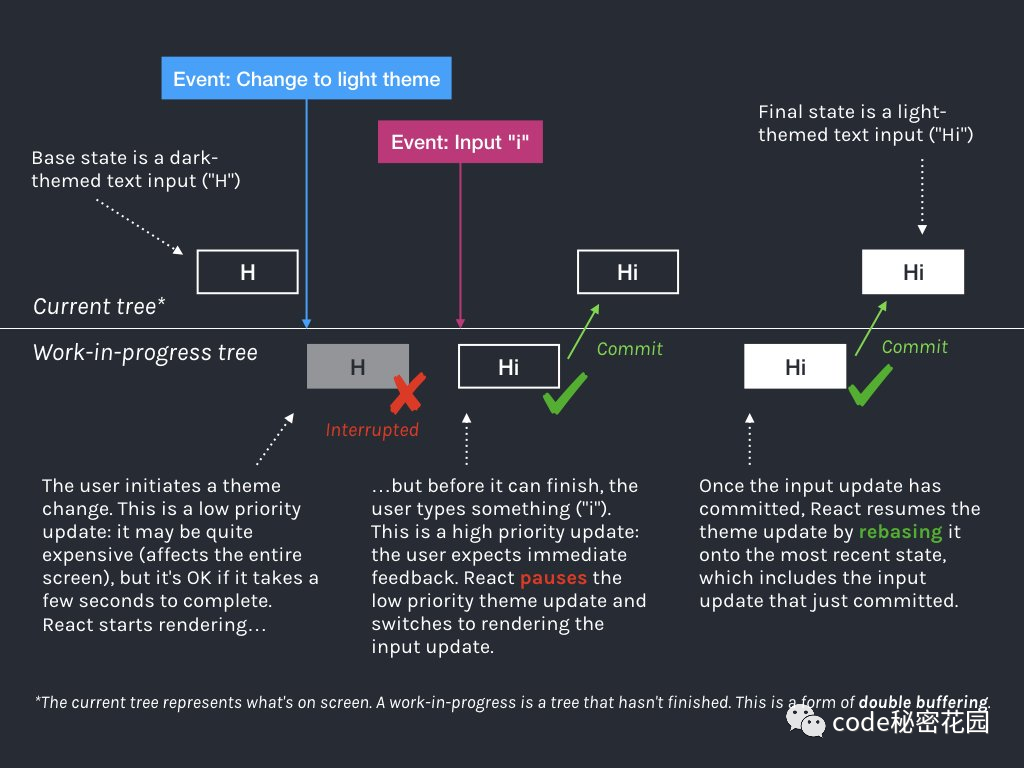
render 阶段还没完成的时候,这时用户在 Input 框输入了一个新的字符。
用户输入这个操作的优先级是比较高的,这时,我们就会先中断 主题更新 这个操作,优先响应用户输入,然后呢再基于上一次更新的结果,继续进行 主题更新的 render 和 commit 流程。这,就是一次高优任务中断低优任务的操作。下面,我们再来看看 React 源码里,优先级是怎样实现的。
我们先来看看这段代码,里面声明了五种不同的优先级:
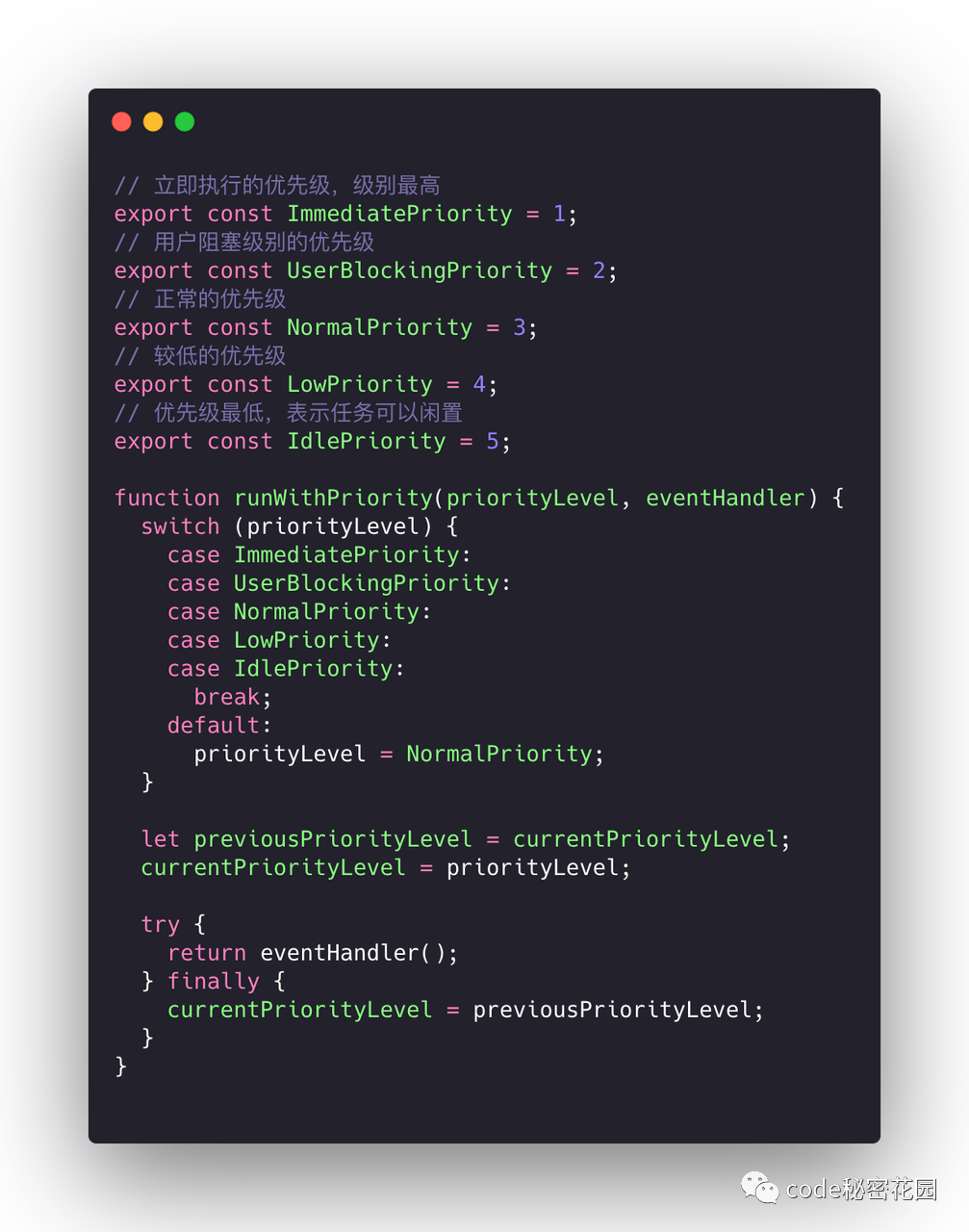
React 内部,只要是涉及到优先级调度的地方,都会使用 runWithPriority 这个函数,这个函数接受一个优先级还有一个回调函数,在这个回调函数的内部调用中,获取优先级的方法都会取到第一个参数传入的优先级。
那么,这几种不同的优先级变量,怎么影响到具体的更新任务呢?
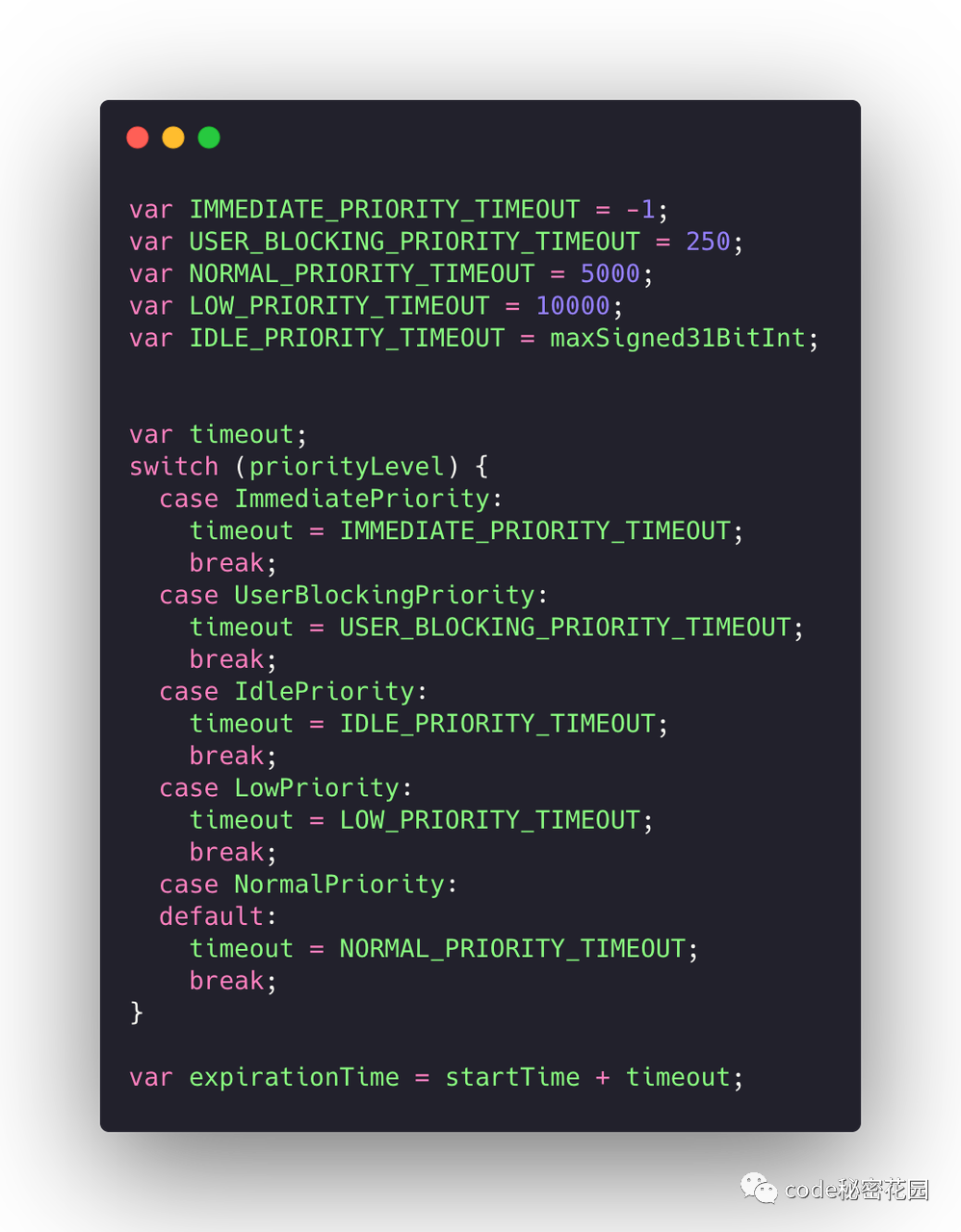
expirationTime。每个更新任务都会有一个 expirationTime, 任务的过期时间离当前时间越近,说明这个任务的优先级越高。
那么,expirationTime ,是通过 startTime 也就是当前时间,加上一个 timeout 得出的。比如 ImmediatePriority 对应的 timeout 是 -1,那么这个任务的过期时间比当前时间还短,表示他已经过期了,需要立即被执行。
那么,我们一整个 React 应用呢,在同一时间可能会产生不同的任务,我们的 Scheduler 呢,就会优先帮我们找到最高优先级的任务,去调度它的更新。那么,怎么才能最快的找到高优先级的任务呢?
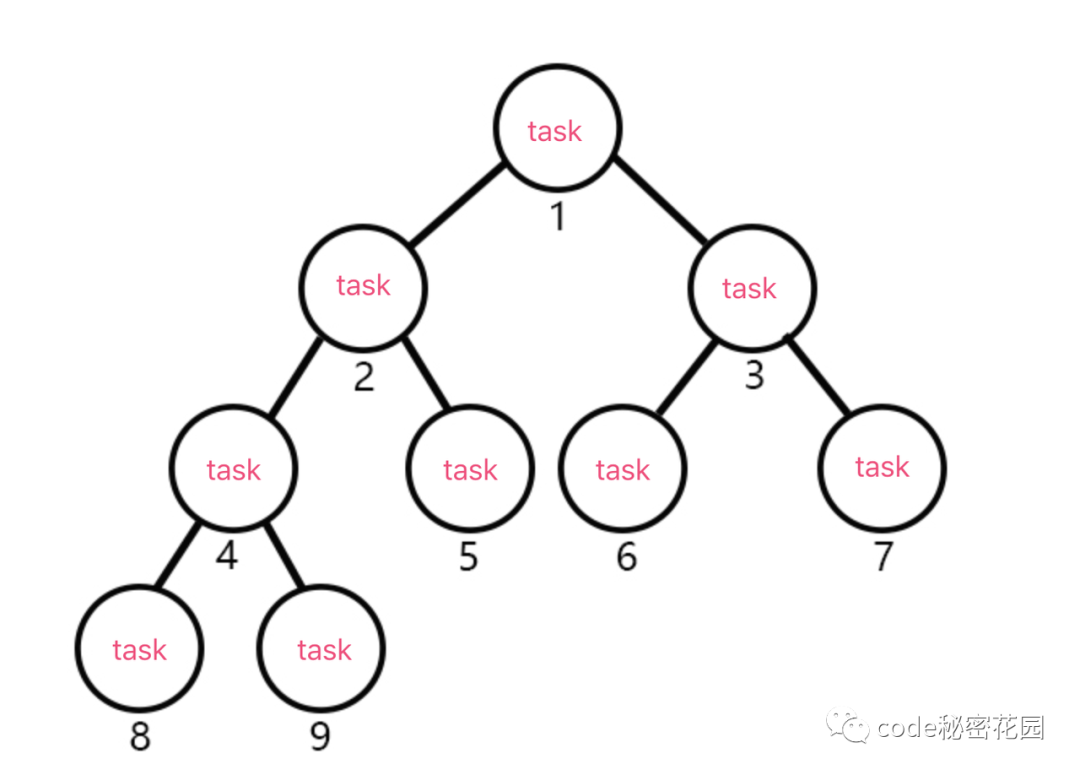
Scheduler 将所有已经准备就绪,可以执行的任务,都存在了一个叫 taskQueue 的队列中,而这个队列使用了小顶堆这种数据结构。在小顶堆中,所有的任务按照任务的过期时间,从小到大进行排列,这样 Scheduler 就可以只花费O(1)复杂度找到队列中最早过期,或者说最高优先级的那个任务。
那么,我们刚刚讲到的这个优先级的机制,实际上是 React 的 Scheduler 的优先级机制,在 React 内部,Scheduler 是一个独立包,它只负责任务的调度,甚至不关心这个任务具体是干什么,即使我们将 Scheduler 脱离 React 使用,也是可以的。
所以 Scheduler 内部的优先级机制也是独立于 React 的, React 内部也有一套自己的优先级机制,因为我们需要知道在一棵 Fiber 树里,哪些 Fiber 以及 哪些 Update 对象,是高优先级的。
在 React16 中,Fiber 和 Update 的优先级和 任务的优先级 是类似。React 会根据不同的操作优先级给每个 Fiber 节点的 Update 增加一个 expirationTime 。但是由于某些问题,React 已经在 Fiber 中不再使用 expirationTime 去表示优先级,这个我们后面再讲。
在新的 React 架构中,一个组件的渲染被分为两个阶段:第一个阶段(也叫做 render 阶段)是可以被 React 打断的,一旦被打断,这阶段所做的所有事情都被废弃,当 React 处理完紧急的事情回来,依然会重新渲染这个组件,这时候第一阶段的工作会重做一遍。
第二个阶段叫做 commit 阶段,一旦开始就不能中断,也就是说第二个阶段的工作会直接做到这个组件的渲染结束。
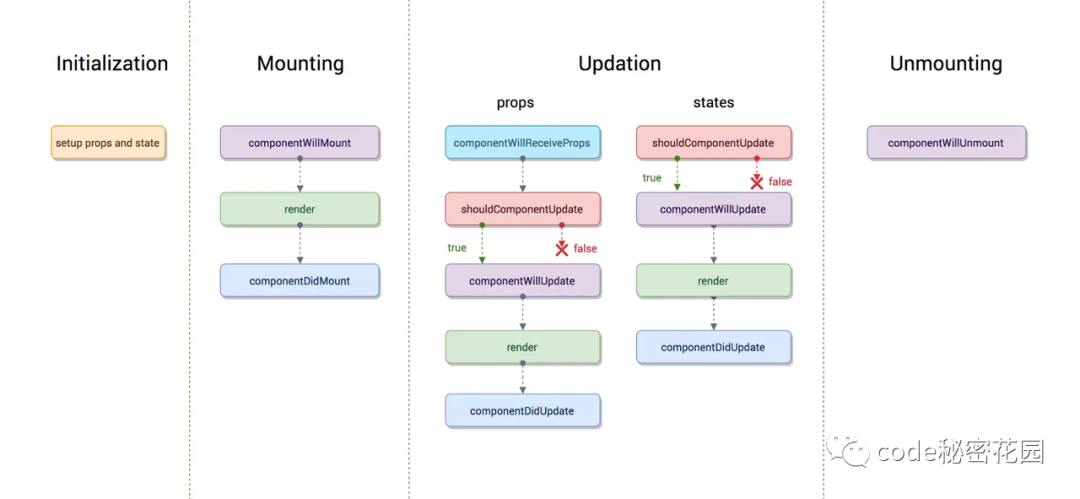
render 函数。render 函数之前的所有生命周期函数(包括 render)都属于第一阶段,之后的都属于第二阶段。开启 Concurrent Mode 之后, render 之前的所有生命周期都有可能会被打断,或者重复调用:
如果我们在这些生命中期中引入了副作用,被重复执行,就可能会给我们的程序带来不可预知的问题,所以到了 React v16.3,React 干脆引入了一个新的生命周期函数 getDerivedStateFromProps,这个生命周期是一个 静态方法,在里面根本不能通过 this 访问到当前组件,输入只能通过参数,对组件渲染的影响只能通过返回值。
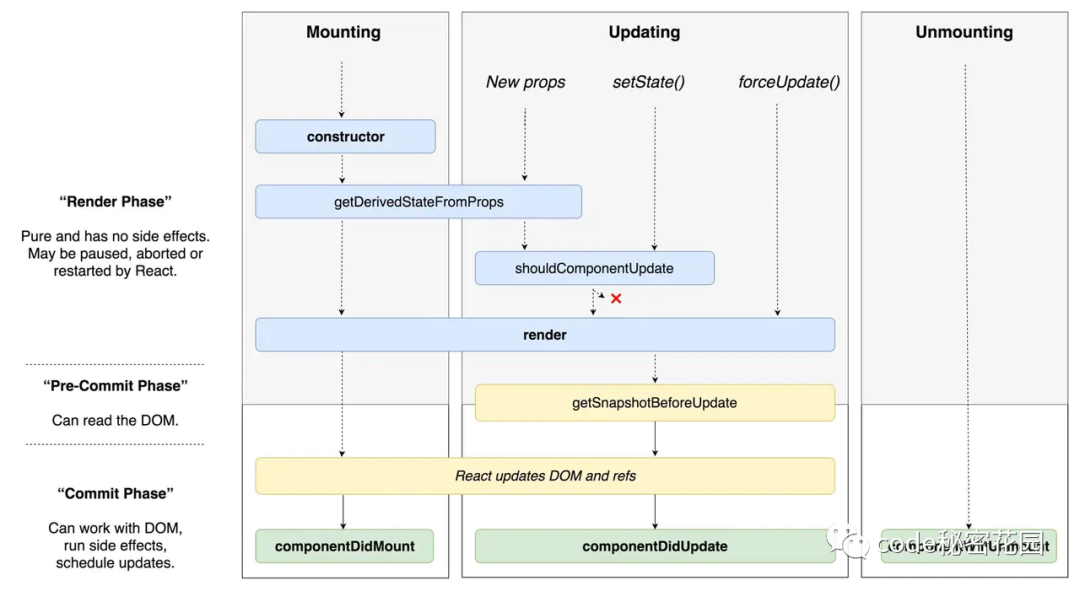
getDerivedStateFromProps 一定是一个纯函数,React 就是通过要求这种纯函数,强制开发者们必须适应 Concurrent Mode 。
那,经过了上面的可中断、和优先级的实现, React 已经可以让程序在突破 CPU 的问题,实现保持响应了,那么 IO 的问题呢?
React 16.6 新增了 <Suspense> 组件,它主要是解决运行时的 IO 问题。
Suspense 可以让组件 “等待” 某个异步操作,直到该异步操作结束再进行渲染。我们可以参考下面这段代码,我们通过 Suspense 实现了一个组件的懒加载。
const MonacoEditor = React.lazy(() => import('react-monaco-editor'));
<Suspense fallback={<div>Editor Loading...</div>}>
<MonacoEditor
height={500}
language="json"
theme="vs"
value={errorFileContext}
options={{}}
/>
</Suspense>那么为啥说 Suspense 可以解决 IO 的问题呢?我们自己通过其他的方式也可以实现这个懒加载。
使用用 Suspense ,我们可以降低加载状的优先级,减少闪屏的问题。比如数据很快返回的时候,我们可以不必显示加载状态,而是直接显示出来,避免闪屏;如果超时没有返回才显式加载状态。本质上讲 Suspense 内的组件子树比组件树的其他部分拥有更低的优先级 我们可以试想一下,如果没有 Suspense ,我们可能要去自己实现一个 loading,那么这个 loading 和其他组件渲染具有相同的优先级,这时无论 IO 有多快,我们的屏幕都会闪一下。
那么如果在请求 IO 的这段时间里,我们利用这段时间加载了其他的组件,只要时间足够小,我们就不需要展示 Lodaing,这样就可以减少闪屏的问题。
当然,Suspense 的作用不止于此,它更重要的还是优化了在 React 内部等待异步操作写法的问题,这个呢,在这里我们就不展开讲了。
虽然 React 16 的核心工作全部都是在 Concurrent Mode 上,但是这并不代表 Concurrent Mode 已经可以稳定使用了,React 16 做的这些所有的工作只是让 Concurrent Mode 称为可能,并且在 Concurrent Mode 下做了一些小小的尝试,在 16 版本默认仍然是采用同步渲染的模式,为了后面的大范围开启 Concurrent Mode ,他还有很多努力要做。
我们可以看到 React17 的更新日志里基本没有什么新特性,但是从官方仅有的一些描述中我们可以发现:React17 是一个用以稳定CM的过渡版本。
由于 Concurrent Mode 带来的 Breaking Change 会使很多库都不兼容,我们不可能都在新项目里去用,所以 React 给我们提供了支持单项目多版本共存的支持,另外还有一个很重要的支持就是:使用 Lanes 重构了 CM 的优先级算法。
先简单说一下多版本共存。
React 采用的是 事件委托 的方式,它自己实现了一套事件机制,自己模拟了事件冒泡和捕获的过程,主要是为了抹平了各个浏览器的兼容性问题。
比如它并不会在你声明它们的时候就将它们 attach 到对应 DOM 节点上。相反地,React 会直接在 document 节点上为每种事件类型 attach 一个处理器。这种方法不但在大型应用树上有性能优势,还会使添加新功能更容易。
但是如果页面上有多个 React 版本,它们都会在 document 上注册事件。这会破坏 事件冒泡这些机制,外部的树仍然会接收到这个事件,这就使嵌套不同版本的 React 难以实现。
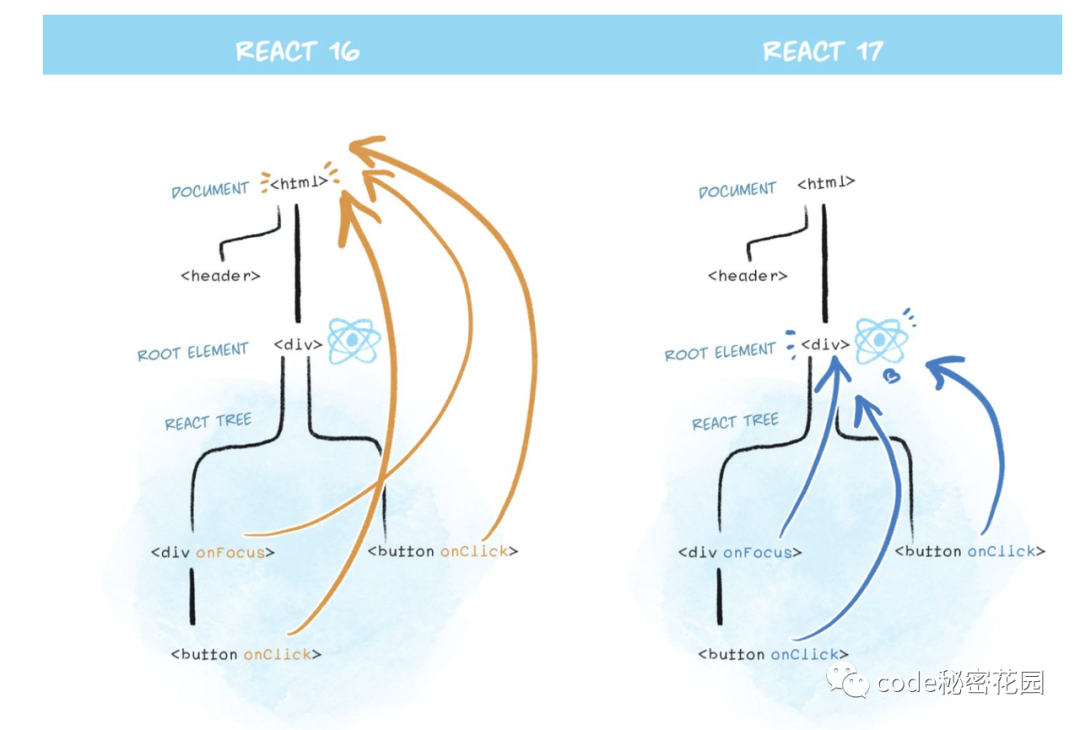
React 要改变 attach 事件到 DOM 的底层实现方式的原因。
在 React 17 中,React 会把事件 attach 到 React 渲染树的根 DOM 容器中,而不再 attach 到 document 级别 :
const rootNode = document.getElementById('root');
ReactDOM.render(<App />, rootNode);这让多版本共存成为可能。
上面的我们讲到,Scheduler 中的优先级和 React 中的优先级是不一致的,在React 16 之前,React 在 Fiber 中也使用 expirationTime 表示优先级,但是在 React 17 中,React 使用 Lanes 重构了 Fiber 的优先级算法。
那么,以前的 expirationTime 有什么问题呢?在 expirationTime 最开始被设计的时候,React 体系中还没有 Suspense 异步渲染 的概念。假如现在有这样的场景: 有 3 个任务, 其优先级 A > B > C,正常来讲只需要按照优先级顺序执行就可以。
但是现在有这样的情况:A 和 C 任务是 CPU 密集型,而 B 是IO密集型 (Suspense 会调用远程 api, 算是 IO 任务), 即 A(cup) > B(IO) > C(cpu),在这种情况下呢,高优先级 IO 任务会中断低优先级 CPU 任务,这显然,是不合理的。
那么使用 expirationTime ,它是以某一优先级作为整棵树的优先级更新标准,而并不是某一个具体的组件,这时我们的需求是需要把 任务B 从 一批任务 中分离出来,先处理 cpu 任务 A 和 C ,如果通过 expirationTime 实现呢,是比较困难的,它很难表示批的概念,也很难从一批任务里抽离单个任务,这时呢,我们就需要一种更细粒度的优先级。
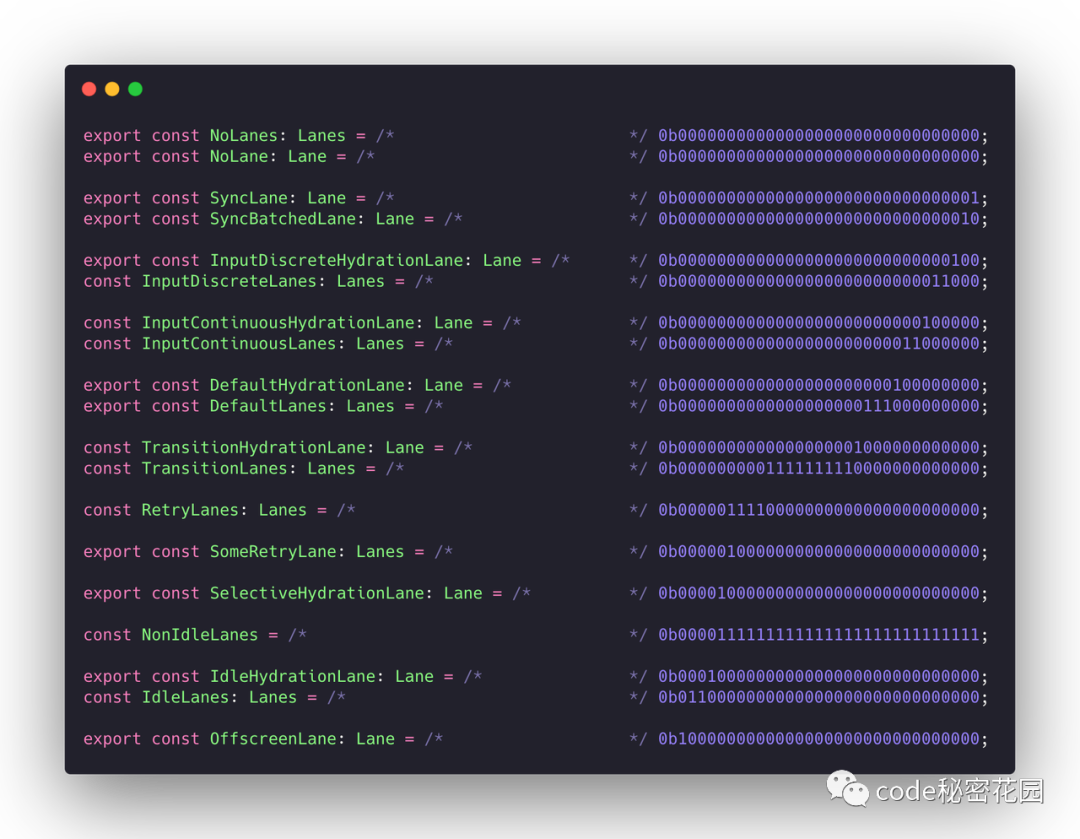
Lanes 就出现了。以前使用 expirationTime 表示的字段,都改为了 lane。比如:
update.expirationTime -> update.lane
fiber.expirationTime -> fiber.lanesLane 和 Lanes 就是单数和复数的关系, 代表单个任务的定义为 Lane ,代表多个任务的定义为 Lanes 。
Lane 的类型,被定义为二进制变量,这样,我们在做优先级计算的时候,用的都是位运算,在频繁更新的时候呢,占用内存少,计算速度也更快。
React 一共定义了18 种 Lane/Lanes 变量 ,每一个变量占有 1 个或多个比特位,每一种 Lane/Lanes 都有对应的优先级。
在代码中我们可以发现,越低优先级的 lanes 占用的位越多。比如 InputDiscreteLanes(也就是离散用交互的优先级)占了2个位,TransitionLanes 占了9个位。原因在于:越低优先级的更新越容易被打断(如果当前优先级的所有赛道都被占有了,则把当前优先级下降一个优先级),导致积压下来,所以需要更多的位。相反,最高优的同步更新的 SyncLane 不需要多余的 lanes。
就在前段时间, React 发布了 18 的 Alpha 版本,由于 Concurrent Mode 带来的巨大的 Break Change ,React 还不能默认开启它。所以,React 干脆换了个名字,叫 Concurrent Rendering 并发渲染机制。
在 React 17 版本里,React 已经支持了多版本共存,所以 React 推荐大家渐进式升级,而不是一刀切。只有由这些 新特性触发的更新会启用并发渲染,所以大家不需要改动很多代码也可以直接使用 React 18,可以根据自己的节奏去尝试这些新特性。
React 给我们提供了三种模式,之前我们一直使用的 ReactDOM.render 创建的应用属于 legacy ,在这个模式下更新还是同步的,一次 render 阶段对应一次 commit 阶段。
如果使用 ReactDOM.createRoot 创建的应用,就默认开启了并发渲染,可以看到 在 React 18 ,createRoot 这个函数已经不再是 unstable。
import React from 'react';
import ReactDOM from 'react-dom';
import App from './App';
const container = document.getElementById('root');
// Create a root.
const root = ReactDOM.createRoot(container);
// Render the top component to the root.
root.render(<App />);另外,还有个通过 createBlockingRoot 函数创建的 blocking 模式,这个函数是方便我们进行上面两种模式的过渡。
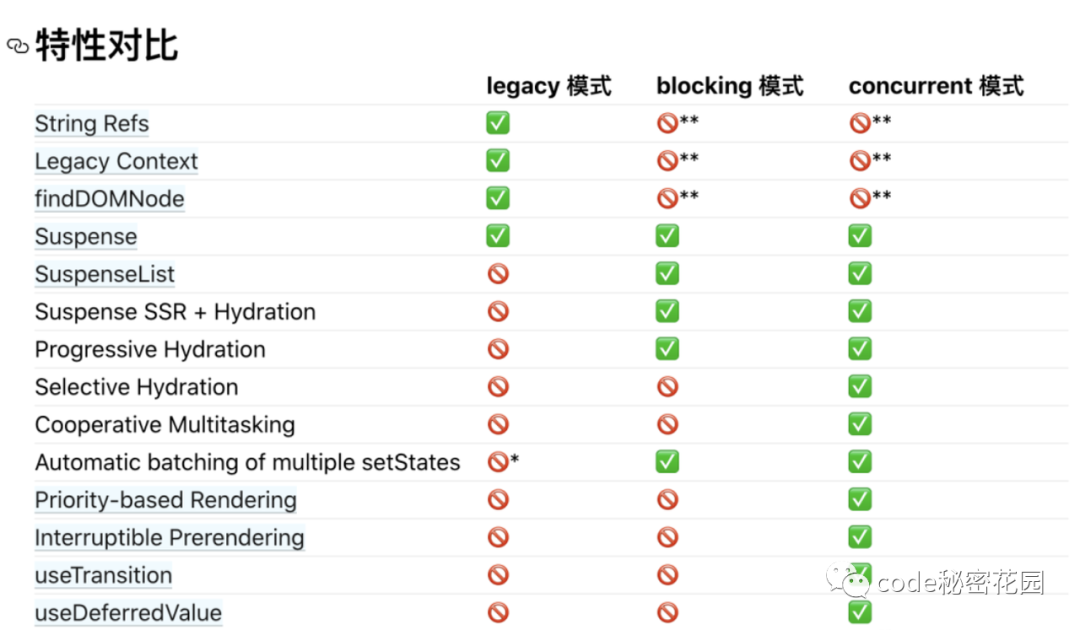
在下面,我们也可以看到不同模式支持的特性对比。
上面我们提到了,在 React 15 中,React 实现了第一版的批处理机制。如果我们在一次事件回调中触发多次更新,他们会被合并为一次更新进行处理。
主要的原因是 batchedUpdates 这个函数本身是同步调用的,如果 fn 内部有异步执行,这时批处理早已执行完,所以这个版本的批处理无法处理异步函数。
但是,在 React 里我们有大量的状态更新要在异步回调里去做,那么在 React 18 呢,如果开启了异步渲染,就可以解决这个问题。
class Example extends React.Component {
constructor() {
super();
this.state = {
val: 0
};
}
componentDidMount() {
this.setState({val: this.state.val + 1});
console.log(this.state.val);
this.setState({val: this.state.val + 1});
console.log(this.state.val);
setTimeout(() => {
this.setState({val: this.state.val + 1});
console.log(this.state.val);
this.setState({val: this.state.val + 1};
console.log(this.state.val);
}, 0);
}
render() {
return null;
}
};在 Concurrent 模式下,是以优先级为依据对更新进行合并的。
我们可以看到,之前我们的这段代码最终的输出已经变成了 0、0、1、1,为啥是这样的输出呢?下面我们简单看下基于优先级的批处理是怎么样的:
在组件对应 fiber 挂载 update 后,就会进入「调度流程」。上面我们也讲到了 Scheduler 调度的作用就是,选出不同优先级的 update 中优先级最高的那个,以该优先级进入更新流程。进入调度后的流程大概如下:
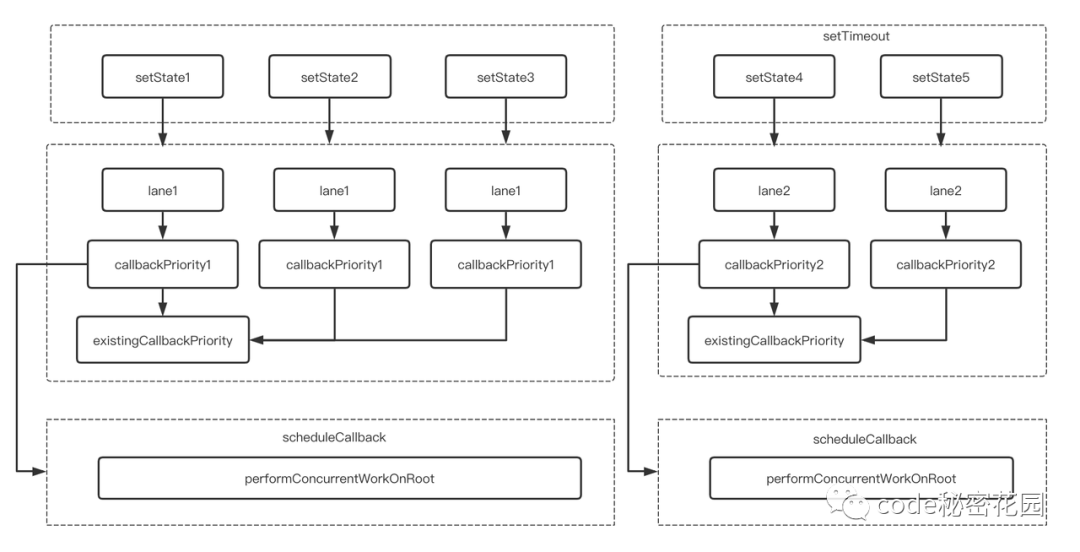
Lane,然后根据 Lane 获取本次需要调度的优先级。
然后我们需要获取在执行正式更新流程之前,是否之前存在一个调度,如果存在的话,和本次调度的优先级进行对比。
如果是第一次执行 setState ,这个 existingCallbackPriority 肯定是不存在的,所以第一次出发会将 更新流程 performConcurrentWorkOnRoot 通过 scheduleCallback 进行调度。
但是第二次 setState 进来,由于之前已经有了一次调度了,而且和本地的优先级是一致的,就会直接 returen,不再调用 scheduleCallback 对 performConcurrentWorkOnRoot 进行调度。
那么,一定时间过后,前面所有同一优先级的更新就会一起进入正式的更新流程。由于后面的 setState 是在 setTimeout 中调用的,setTimeout 具有较低的优先级,所有会放到下一个批次执行,所以,最终打印的结果是 0、0、1、1。
以上,就是基于优先级的自动批处理的流程。有了这样的流程,我们就不需要之前 React 给我们提供的 unstable_batchedUpdates 这样手动批处理的函数了。
下面,我们来看看React 18 新增的一个 API:startTransition:
这个 API 可以让我们手动区分非紧急的状态更新,本质上还是对组件渲染优先级的控制。比如现在有这样一个场景:我们要去 Input 框输入一个值,然后下面需要同时给出通过我们输入后的值过滤出来的一些数据。
setInputValue (input) ;
setSearchQuery (input) ;首先用户输入上去的值肯定是需要立刻渲染出来的,但是过滤出来的联想数据可能不需要那么快的渲染,如果我们不做任何额外的处理,在 React 18 之前,所有更新都会立刻被渲染,如果你的原始数据非常多,那么每次输入新的值后你需要进行的计算量(根据输入的值过滤出符合条件的数据)就非常大,所以每次用户输入后可能会有卡顿现象。
所以,在以前我们可能会自己去加一些防抖这样的操作去人为的延迟过滤数据的计算和渲染。
新的 startTransition API 可以让我们把数据标记成 transitions 状态。
import { startTransition } from 'react';
// Urgent: Show what was typed
setInputValue(input);
// Mark any state updates inside as transitions
startTransition(() => {
// Transition: Show the results
setSearchQuery(input);
});所有在 startTransition 回调中的更新都会被认为是 非紧急处理,如果出现更紧急的更新(比如用户又输入了新的值),则上面的更新都会被中断,直到没有其他紧急操作之后才会去继续执行更新。
怎么样,是不是比我们人工实现一个防抖更优雅
同时,React 还给我们提供了一个带有 isPending 过渡标志的 Hook:
import { useTransition } from 'react' ;
const [ isPending , startTransition ] = useTransition ( ) ;你可以使用它和一些 loading 动画结合使用:
{ isPending && < Spinner / > }
下面,还有一个更典型的例子:
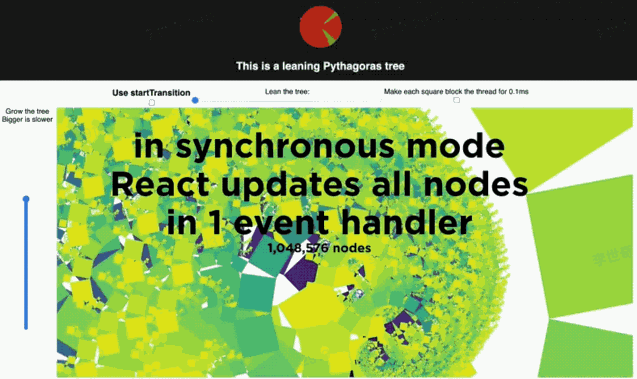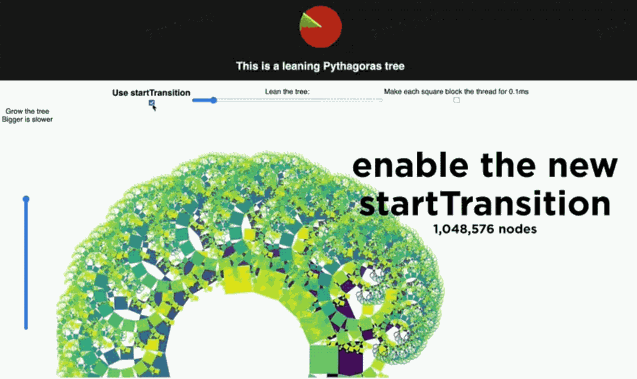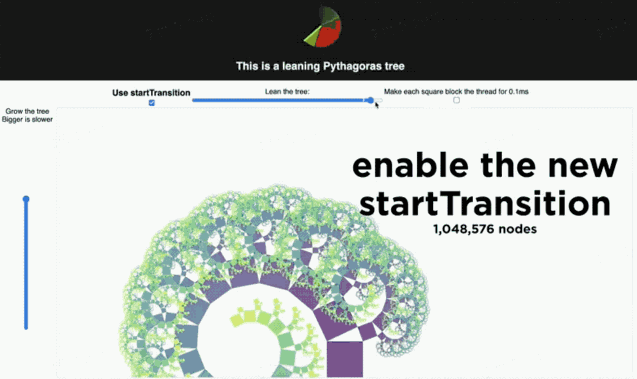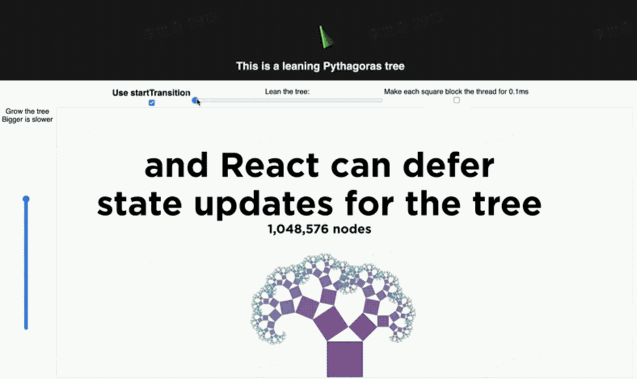
拖动左边滑块会改变树渲染的节点数量。拖动顶部滑块会改变树的倾斜角度。最顶上有个帧雷达,可以实时显示更新过程中的掉帧情况。当不点击 Use startTransition 按钮,拖动顶上的滑块。可以看到:拖动并不流畅,顶上的帧雷达显示掉帧。
这时,我们把 tree 的 render 放到 startTransition 中,虽然 tree 的更新还是很卡顿,但是雷达不会掉帧了。
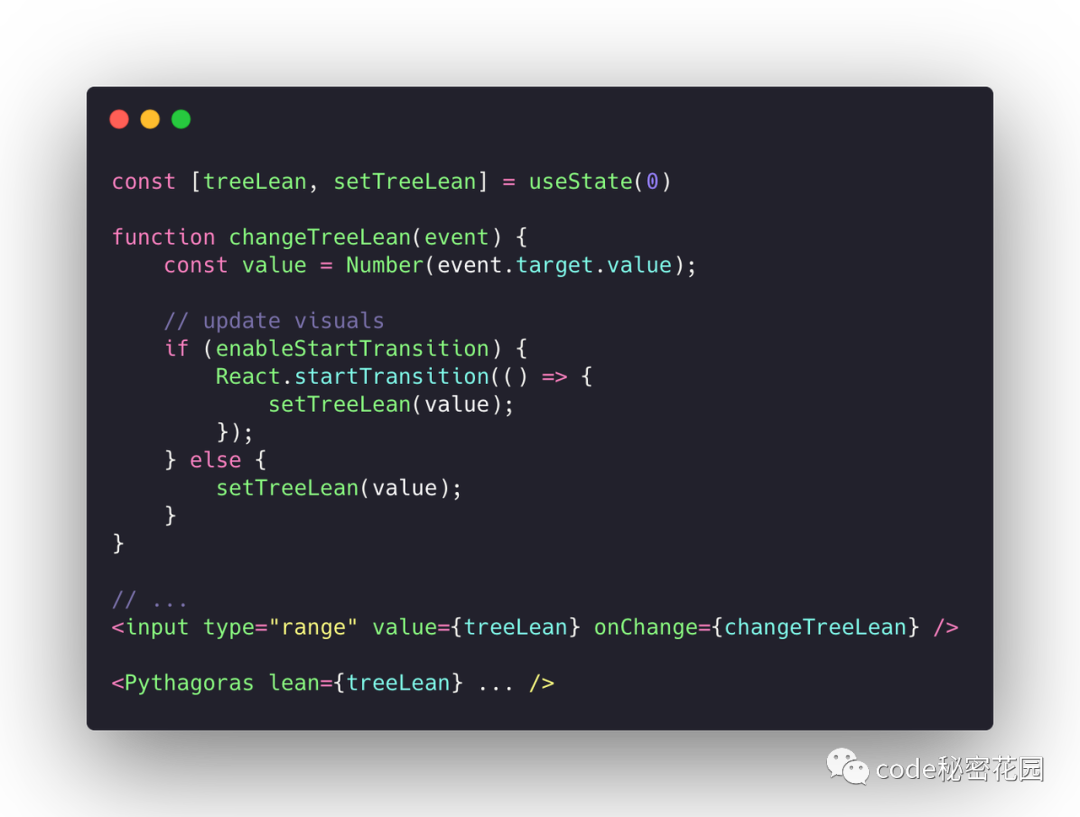
startTransition 的实现其实也很简单,所有 在 startTransition 回调中执行的操作都会拿到一个 isTransition 标记,根据这个标记, React 会把更新赋予更低的优先级。
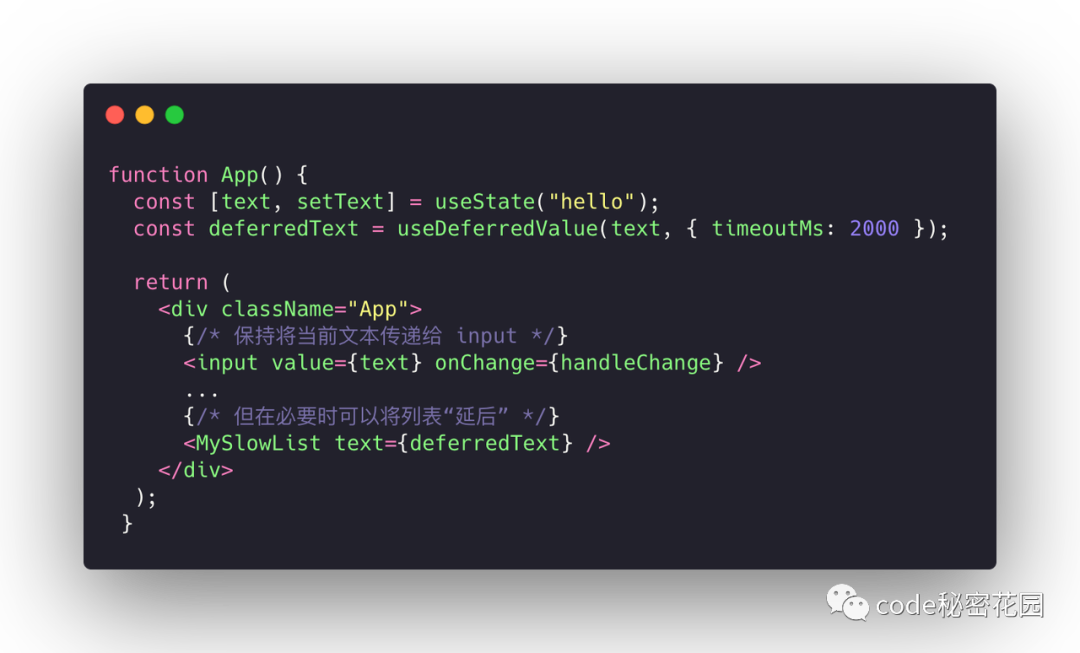
除了手动标记某些操作的优先级,我们还能去标记某个具体状态的优先级。React 18 给我们提供了一个新的 Hook useDeferredValue 。
比如我们现在有这样的场景,用户输入了一些信息后,我们需要对这些信息做一些处理然后渲染到下面的详情里,如果这个处理比较耗时,那么连续的用户输入会有卡顿的感觉。我们可以看图中这个例子,实际上所有的输入都是连续输入的。
实际上,我们希望的是用户的输入能得到快速的响应,但是下面详情的渲染多等待一会其实无所谓。

useDeferredValue 创建一个 deferredText,真正的意思是 deferredText 的渲染被标记为了低优先级,它还有另一个参数,这个渲染的最大延迟时间。我们可以大概猜测到,useDeferredValue 的实现机制应该和 expairedTime 是类似的。

防抖的主要问题是,不管我们的电脑渲染的有多快,它都会有一个固定的延迟,而 useDeferredValue 呢,只会在渲染比较耗时的情况下把优先级滞后,在多数情况下是不会有不必要的延迟的。
最后呢,就是 Suspense 了,在 React 18 以前, SSR 模式下是不支持使用 Suspense 组件的,而在 React 18 中,服务端渲染的组件也支持使用 <Suspense> 了:如果你把组件包裹在了<Suspense>中,服务端首先会把 fallback 中的组件作为 HTML 流式传输,一旦主组件加载完成,React 会发送新的 HTML 来替换整个组件。
<Layout>
< Article />
<Suspense fallback={<Spinner />}>
<Comments />
</Suspense>
</Layout>比如上面的代码,<Article> 组件首先会被渲染,<Comments> 组件将被 fallback 替换为 <Spinner> 。一旦 <Comments> 组件加载完成后,React 会才将其发送到浏览器,替换 <Spinner> 组件。
最后,如果大家想要阅读 React 源码的话,不建议直接去硬啃,因为有些代码确实比较难懂。
推荐大家根据下面两个教程的大纲去看,先了解源码整体架构的划分,再实际去调试走通整个流程,最后根据自己的需求进入各个模块进行有针对性的阅读。
本文由哈喽比特于3年以前收录,如有侵权请联系我们。
文章来源:https://mp.weixin.qq.com/s/mV1Ffc-t6DCfNFfRjPq2_g
京东创始人刘强东和其妻子章泽天最近成为了互联网舆论关注的焦点。有关他们“移民美国”和在美国购买豪宅的传言在互联网上广泛传播。然而,京东官方通过微博发言人发布的消息澄清了这些传言,称这些言论纯属虚假信息和蓄意捏造。
日前,据博主“@超能数码君老周”爆料,国内三大运营商中国移动、中国电信和中国联通预计将集体采购百万台规模的华为Mate60系列手机。
据报道,荷兰半导体设备公司ASML正看到美国对华遏制政策的负面影响。阿斯麦(ASML)CEO彼得·温宁克在一档电视节目中分享了他对中国大陆问题以及该公司面临的出口管制和保护主义的看法。彼得曾在多个场合表达了他对出口管制以及中荷经济关系的担忧。
今年早些时候,抖音悄然上线了一款名为“青桃”的 App,Slogan 为“看见你的热爱”,根据应用介绍可知,“青桃”是一个属于年轻人的兴趣知识视频平台,由抖音官方出品的中长视频关联版本,整体风格有些类似B站。
日前,威马汽车首席数据官梅松林转发了一份“世界各国地区拥车率排行榜”,同时,他发文表示:中国汽车普及率低于非洲国家尼日利亚,每百户家庭仅17户有车。意大利世界排名第一,每十户中九户有车。
近日,一项新的研究发现,维生素 C 和 E 等抗氧化剂会激活一种机制,刺激癌症肿瘤中新血管的生长,帮助它们生长和扩散。
据媒体援引消息人士报道,苹果公司正在测试使用3D打印技术来生产其智能手表的钢质底盘。消息传出后,3D系统一度大涨超10%,不过截至周三收盘,该股涨幅回落至2%以内。
9月2日,坐拥千万粉丝的网红主播“秀才”账号被封禁,在社交媒体平台上引发热议。平台相关负责人表示,“秀才”账号违反平台相关规定,已封禁。据知情人士透露,秀才近期被举报存在违法行为,这可能是他被封禁的部分原因。据悉,“秀才”年龄39岁,是安徽省亳州市蒙城县人,抖音网红,粉丝数量超1200万。他曾被称为“中老年...
9月3日消息,亚马逊的一些股东,包括持有该公司股票的一家养老基金,日前对亚马逊、其创始人贝索斯和其董事会提起诉讼,指控他们在为 Project Kuiper 卫星星座项目购买发射服务时“违反了信义义务”。
据消息,为推广自家应用,苹果现推出了一个名为“Apps by Apple”的网站,展示了苹果为旗下产品(如 iPhone、iPad、Apple Watch、Mac 和 Apple TV)开发的各种应用程序。
特斯拉本周在美国大幅下调Model S和X售价,引发了该公司一些最坚定支持者的不满。知名特斯拉多头、未来基金(Future Fund)管理合伙人加里·布莱克发帖称,降价是一种“短期麻醉剂”,会让潜在客户等待进一步降价。
据外媒9月2日报道,荷兰半导体设备制造商阿斯麦称,尽管荷兰政府颁布的半导体设备出口管制新规9月正式生效,但该公司已获得在2023年底以前向中国运送受限制芯片制造机器的许可。
近日,根据美国证券交易委员会的文件显示,苹果卫星服务提供商 Globalstar 近期向马斯克旗下的 SpaceX 支付 6400 万美元(约 4.65 亿元人民币)。用于在 2023-2025 年期间,发射卫星,进一步扩展苹果 iPhone 系列的 SOS 卫星服务。
据报道,马斯克旗下社交平台𝕏(推特)日前调整了隐私政策,允许 𝕏 使用用户发布的信息来训练其人工智能(AI)模型。新的隐私政策将于 9 月 29 日生效。新政策规定,𝕏可能会使用所收集到的平台信息和公开可用的信息,来帮助训练 𝕏 的机器学习或人工智能模型。
9月2日,荣耀CEO赵明在采访中谈及华为手机回归时表示,替老同事们高兴,觉得手机行业,由于华为的回归,让竞争充满了更多的可能性和更多的魅力,对行业来说也是件好事。
《自然》30日发表的一篇论文报道了一个名为Swift的人工智能(AI)系统,该系统驾驶无人机的能力可在真实世界中一对一冠军赛里战胜人类对手。
近日,非营利组织纽约真菌学会(NYMS)发出警告,表示亚马逊为代表的电商平台上,充斥着各种AI生成的蘑菇觅食科普书籍,其中存在诸多错误。
社交媒体平台𝕏(原推特)新隐私政策提到:“在您同意的情况下,我们可能出于安全、安保和身份识别目的收集和使用您的生物识别信息。”
2023年德国柏林消费电子展上,各大企业都带来了最新的理念和产品,而高端化、本土化的中国产品正在不断吸引欧洲等国际市场的目光。
罗永浩日前在直播中吐槽苹果即将推出的 iPhone 新品,具体内容为:“以我对我‘子公司’的了解,我认为 iPhone 15 跟 iPhone 14 不会有什么区别的,除了序(列)号变了,这个‘不要脸’的东西,这个‘臭厨子’。