ProGit - 2
- 1. 起步
- 2. Git 基础
- 3. Git 分支
- 4. 服务器上的 Git
- 4.1 协议
- 4.2 在服务器上搭建 Git
- 4.3 生成 SSH 公钥
- 4.4 配置服务器
- 4.5 Git 守护进程
- 4.6 Smart HTTP
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 第三方托管的选择
- 5. 分布式 Git
- 6. GitHub
- 7. Git 工具
- 7.1 选择修订版本
- 7.2 交互式暂存
- 7.3 储藏与清理
- 7.4 签署工作
- 7.5 搜索
- 7.6 重写历史
- 7.7 重置揭密
- 7.8 高级合并
- 7.9 Rerere
- 7.10 使用 Git 调试
- 7.11 子模块
- 7.12 打包
- 7.13 替换
- 7.14 凭证存储
- 8. 自定义 Git
- 9. Git 与其他系统
- 9.1 作为客户端的 Git
- 9.2 迁移到 Git
- 10. Git 内部原理
- A1. 其它环境中的 Git
- A1.1 图形界面
- A1.2 Visual Studio 中的 Git
- A1.3 Visual Studio Code 中的 Git
- A1.5 IntelliJ / PyCharm / WebStorm / PhpStorm / RubyMine 中的 Git
- A1.6 Sublime Text 中的 Git
- A1.7 Bash 中的 Git
- A1.8 Zsh 中的 Git
- A1.9 Powershell 中的 Git
- A2. 将 Git 嵌入你的应用
分支简介
为了真正理解 Git 处理分支的方式,我们需要回顾一下 Git 是如何保存数据的。
或许你还记得 <<ch01-getting-started#ch01-getting-started>> 的内容, Git 保存的不是文件的变化或者差异,而是一系列不同时刻的 快照 。
在进行提交操作时,Git 会保存一个提交对象(commit object)。 知道了 Git 保存数据的方式,我们可以很自然的想到——该提交对象会包含一个指向暂存内容快照的指针。 但不仅仅是这样,该提交对象还包含了作者的姓名和邮箱、提交时输入的信息以及指向它的父对象的指针。 首次提交产生的提交对象没有父对象,普通提交操作产生的提交对象有一个父对象, 而由多个分支合并产生的提交对象有多个父对象,
为了更加形象地说明,我们假设现在有一个工作目录,里面包含了三个将要被暂存和提交的文件。 暂存操作会为每一个文件计算校验和(使用我们在 <<ch01-getting-started#ch01-getting-started>> 中提到的 SHA-1 哈希算法),然后会把当前版本的文件快照保存到 Git 仓库中 (Git 使用 blob 对象来保存它们),最终将校验和加入到暂存区域等待提交:
$ git add README test.rb LICENSE
$ git commit -m 'The initial commit of my project'当使用 git commit 进行提交操作时,Git 会先计算每一个子目录(本例中只有项目根目录)的校验和,
然后在 Git 仓库中这些校验和保存为树对象。随后,Git 便会创建一个提交对象,
它除了包含上面提到的那些信息外,还包含指向这个树对象(项目根目录)的指针。
如此一来,Git 就可以在需要的时候重现此次保存的快照。
现在,Git 仓库中有五个对象:三个 blob 对象(保存着文件快照)、一个 树 对象 (记录着目录结构和 blob 对象索引)以及一个 提交 对象(包含着指向前述树对象的指针和所有提交信息)。
.首次提交对象及其树结构
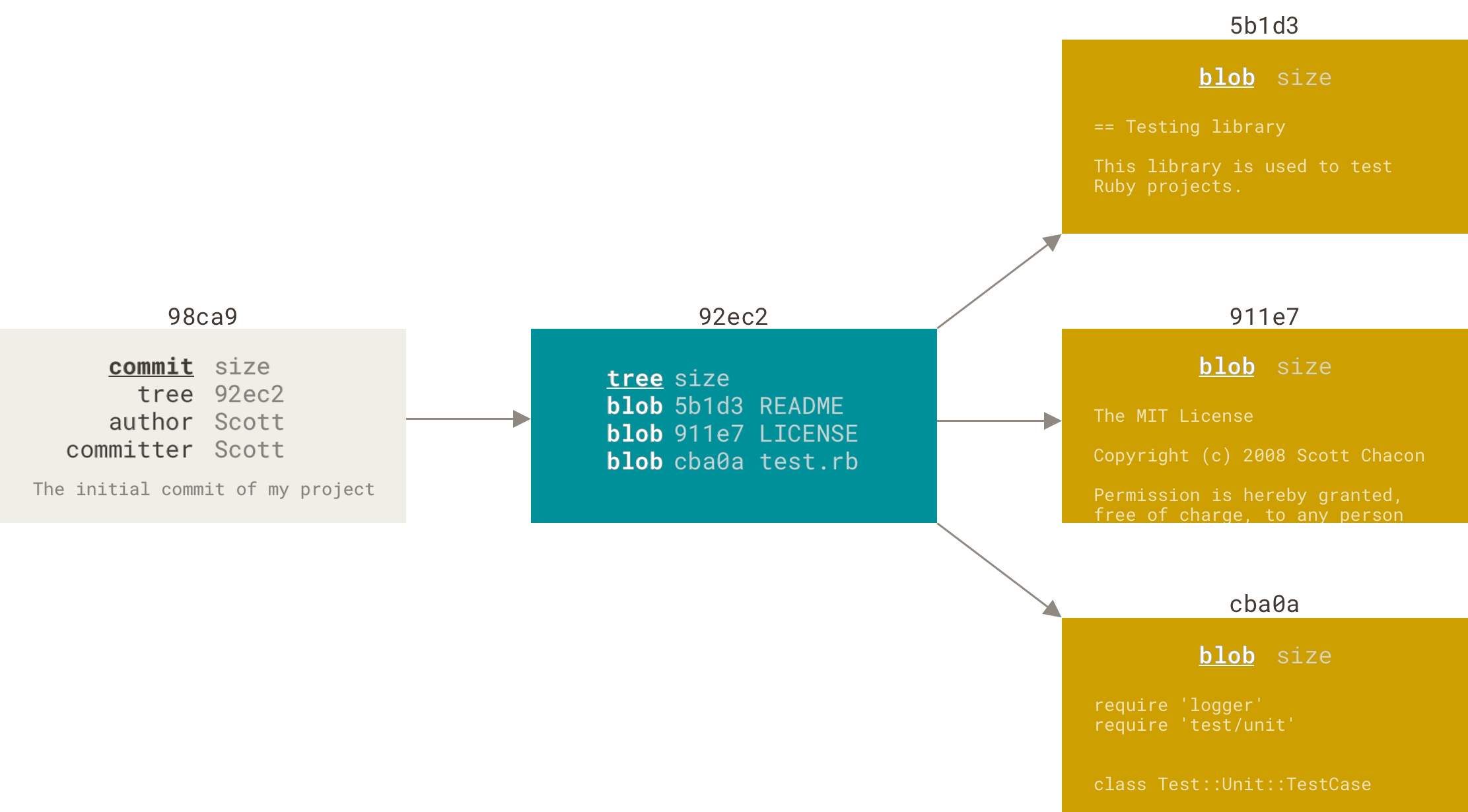
做些修改后再次提交,那么这次产生的提交对象会包含一个指向上次提交对象(父对象)的指针。
.提交对象及其父对象
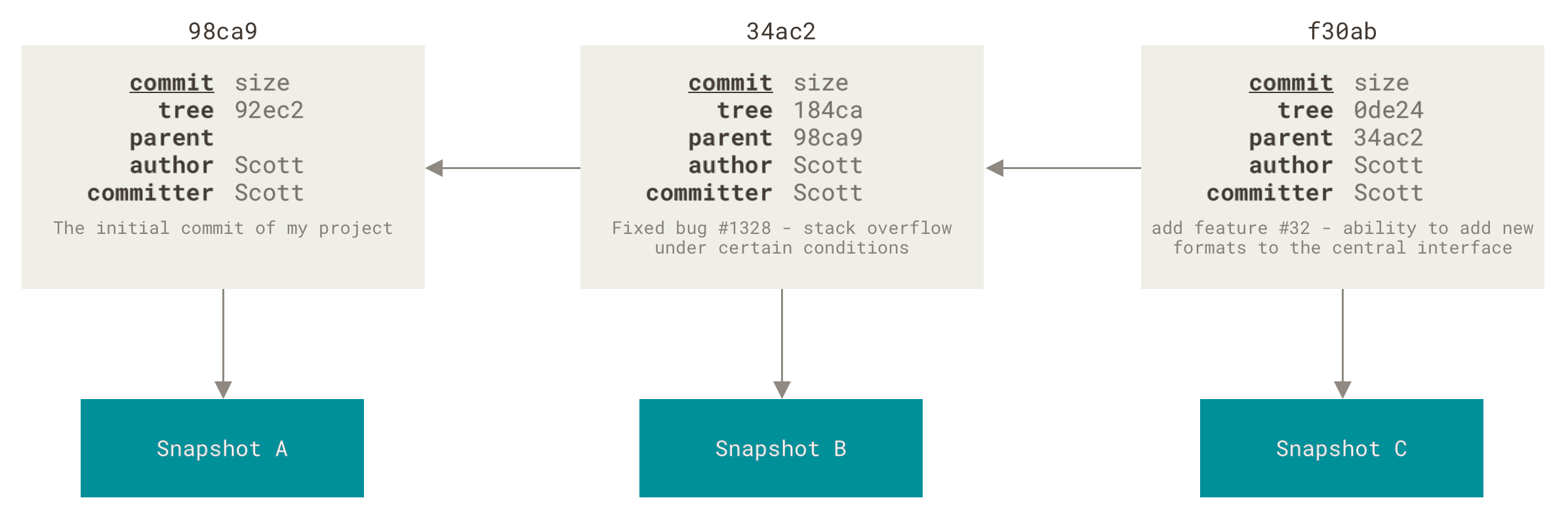
Git 的分支,其实本质上仅仅是指向提交对象的可变指针。
Git 的默认分支名字是 master。
在多次提交操作之后,你其实已经有一个指向最后那个提交对象的 master 分支。
master 分支会在每次提交时自动向前移动。
Git 的
master分支并不是一个特殊分支。 它就跟其它分支完全没有区别。 之所以几乎每一个仓库都有 master 分支,是因为git init命令默认创建它,并且大多数人都懒得去改动它。
.分支及其提交历史
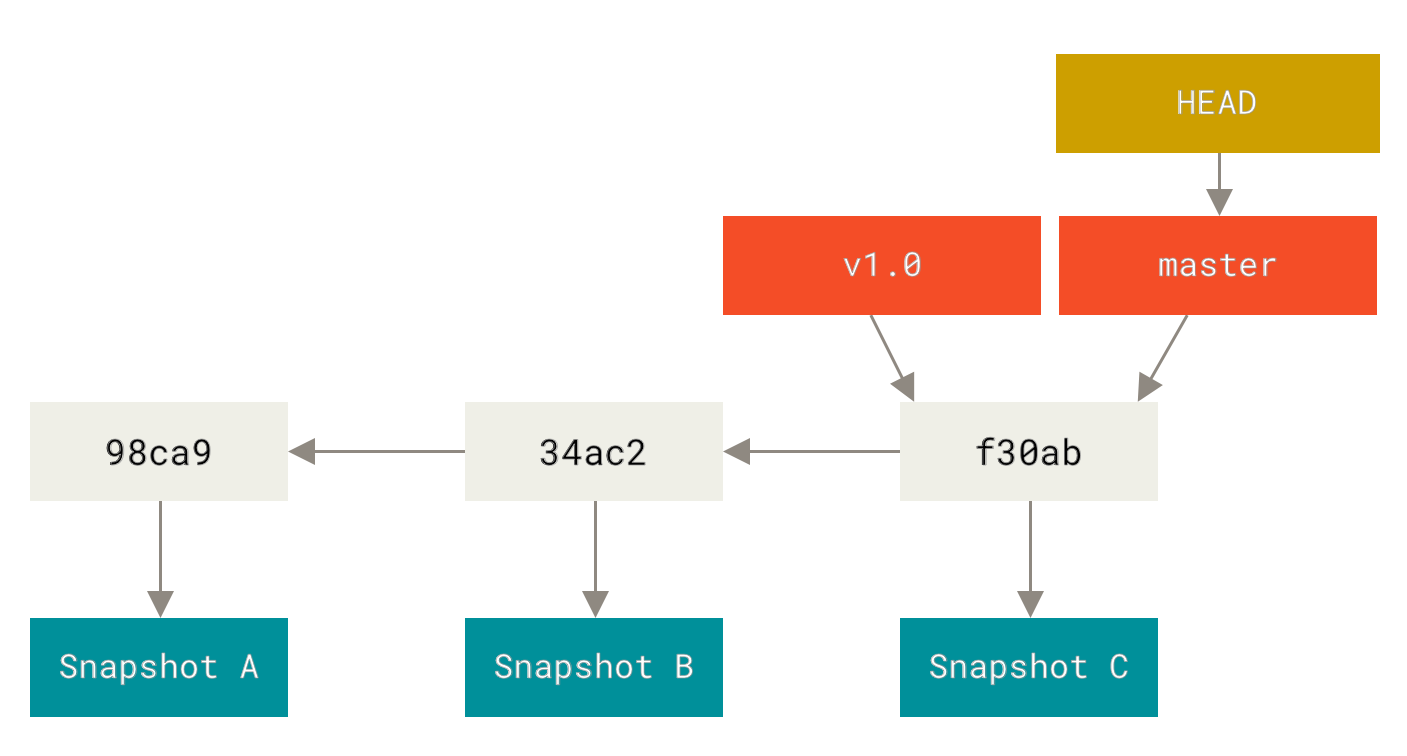
分支创建
Git 是怎么创建新分支的呢?
很简单,它只是为你创建了一个可以移动的新的指针。
比如,创建一个 testing 分支,
你需要使用 git branch 命令:
$ git branch testing这会在当前所在的提交对象上创建一个指针。
.两个指向相同提交历史的分支
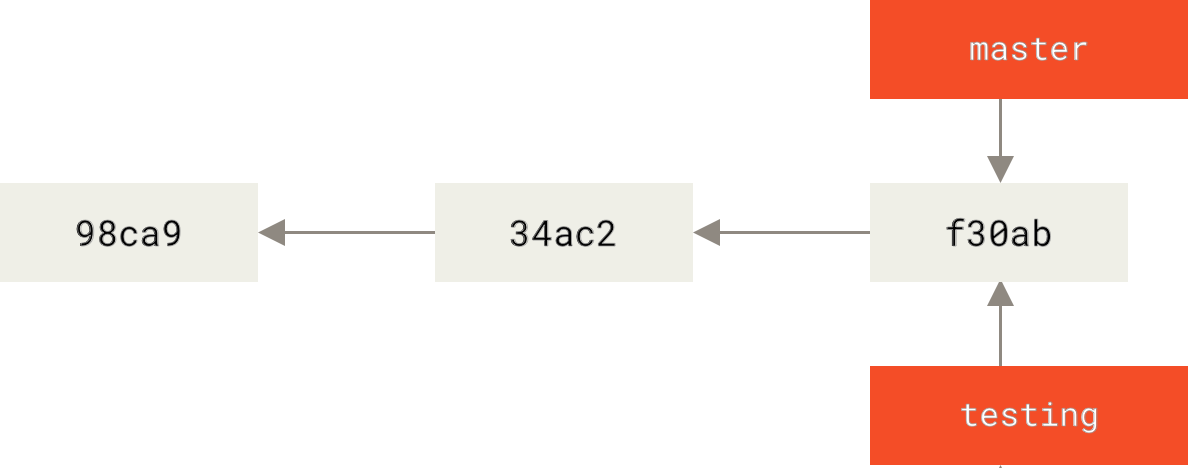
那么,Git 又是怎么知道当前在哪一个分支上呢?
也很简单,它有一个名为 HEAD 的特殊指针。
请注意它和许多其它版本控制系统(如 Subversion 或 CVS)里的 HEAD 概念完全不同。
在 Git 中,它是一个指针,指向当前所在的本地分支(译注:将 HEAD 想象为当前分支的别名)。
在本例中,你仍然在 master 分支上。
因为 git branch 命令仅仅 创建 一个新分支,并不会自动切换到新分支中去。
.HEAD 指向当前所在的分支
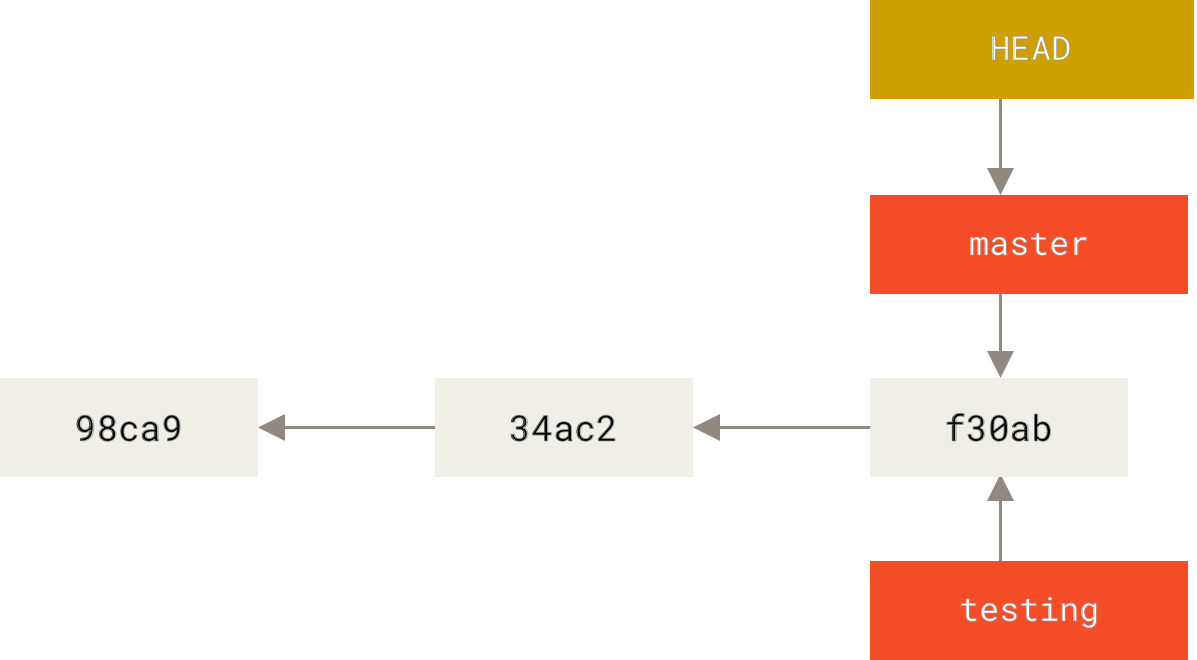
你可以简单地使用 git log 命令查看各个分支当前所指的对象。
提供这一功能的参数是 --decorate。
$ git log --oneline --decorate
f30ab (HEAD -> master, testing) add feature #32 - ability to add new formats to the central interface
34ac2 Fixed bug #1328 - stack overflow under certain conditions
98ca9 The initial commit of my project正如你所见,当前 master 和 testing 分支均指向校验和以 f30ab 开头的提交对象。
分支切换
要切换到一个已存在的分支,你需要使用 git checkout 命令。
我们现在切换到新创建的 testing 分支去:
$ git checkout testing这样 HEAD 就指向 testing 分支了。
.HEAD 指向当前所在的分支
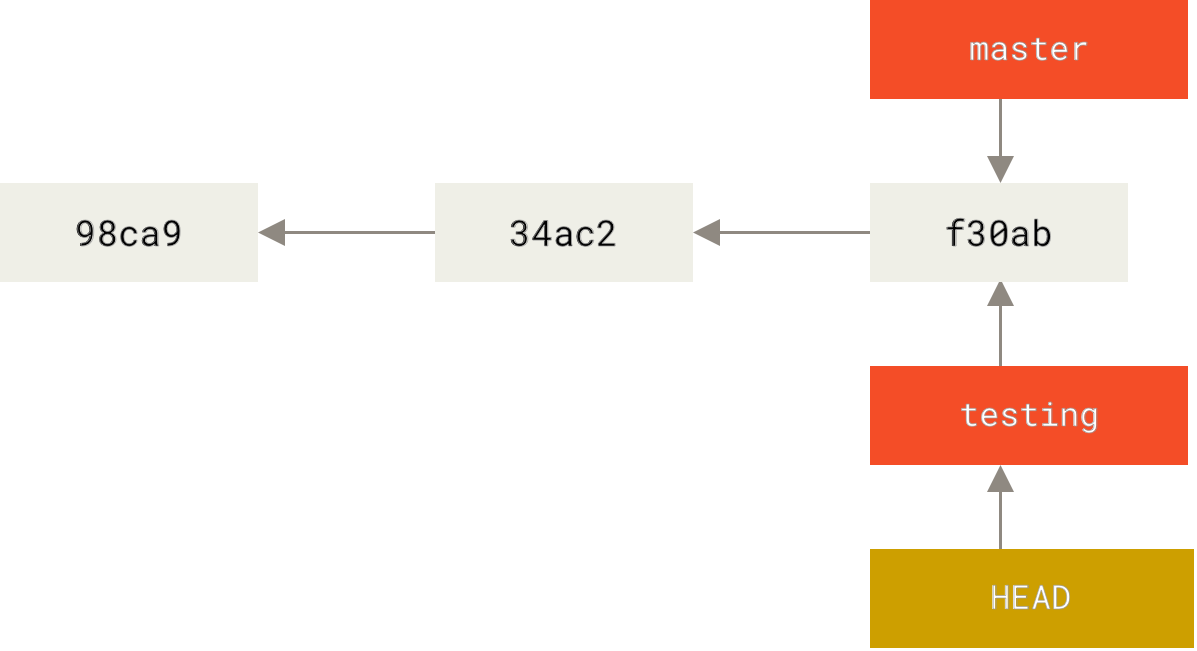
那么,这样的实现方式会给我们带来什么好处呢? 现在不妨再提交一次:
$ vim test.rb
$ git commit -a -m 'made a change'.HEAD 分支随着提交操作自动向前移动

如图所示,你的 testing 分支向前移动了,但是 master 分支却没有,它仍然指向运行 git checkout 时所指的对象。
这就有意思了,现在我们切换回 master 分支看看:
$ git checkout master.检出时 HEAD 随之移动
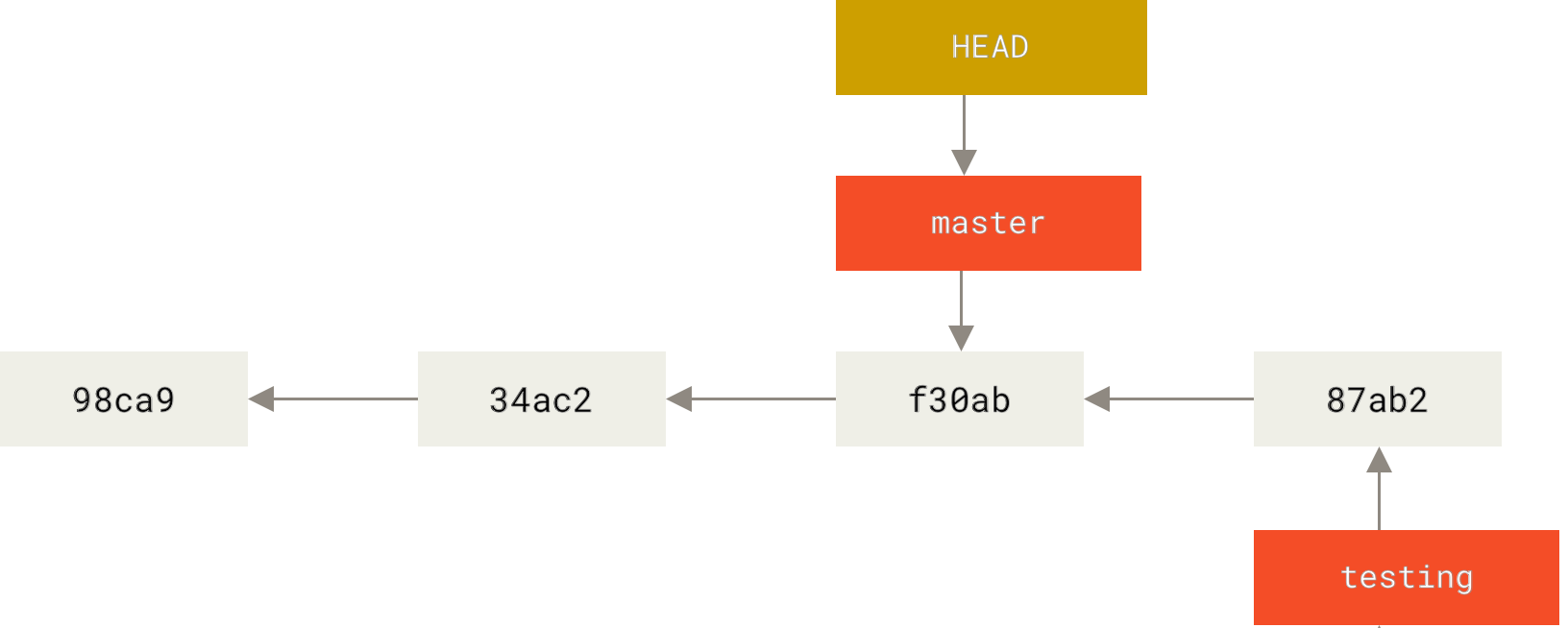
这条命令做了两件事。
一是使 HEAD 指回 master 分支,二是将工作目录恢复成 master 分支所指向的快照内容。
也就是说,你现在做修改的话,项目将始于一个较旧的版本。
本质上来讲,这就是忽略 testing 分支所做的修改,以便于向另一个方向进行开发。
.分支切换会改变你工作目录中的文件 在切换分支时,一定要注意你工作目录里的文件会被改变。 如果是切换到一个较旧的分支,你的工作目录会恢复到该分支最后一次提交时的样子。 如果 Git 不能干净利落地完成这个任务,它将禁止切换分支。
我们不妨再稍微做些修改并提交:
$ vim test.rb
$ git commit -a -m 'made other changes'现在,这个项目的提交历史已经产生了分叉(参见 <branch、checkout 和 commit。
.项目分叉历史
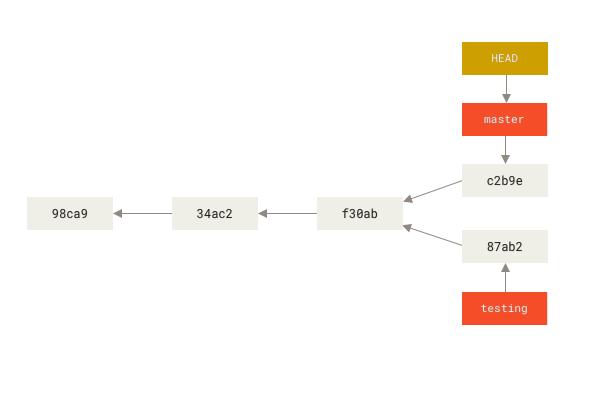
你可以简单地使用 git log 命令查看分叉历史。
运行 git log --oneline --decorate --graph --all ,它会输出你的提交历史、各个分支的指向以及项目的分支分叉情况。
$ git log --oneline --decorate --graph --all
* c2b9e (HEAD, master) made other changes
| * 87ab2 (testing) made a change
|/
* f30ab add feature #32 - ability to add new formats to the
* 34ac2 fixed bug #1328 - stack overflow under certain conditions
* 98ca9 initial commit of my project由于 Git 的分支实质上仅是包含所指对象校验和(长度为 40 的 SHA-1 值字符串)的文件,所以它的创建和销毁都异常高效。 创建一个新分支就相当于往一个文件中写入 41 个字节(40 个字符和 1 个换行符),如此的简单能不快吗?
这与过去大多数版本控制系统形成了鲜明的对比,它们在创建分支时,将所有的项目文件都复制一遍,并保存到一个特定的目录。 完成这样繁琐的过程通常需要好几秒钟,有时甚至需要好几分钟。所需时间的长短,完全取决于项目的规模。 而在 Git 中,任何规模的项目都能在瞬间创建新分支。 同时,由于每次提交都会记录父对象,所以寻找恰当的合并基础(译注:即共同祖先)也是同样的简单和高效。 这些高效的特性使得 Git 鼓励开发人员频繁地创建和使用分支。
接下来,让我们看看你为什么应该这样做。
.创建新分支的同时切换过去 通常我们会在创建一个新分支后立即切换过去,这可以用
git checkout -b <newbranchname>一条命令搞定。