Go语言高级编程
6.1 分布式id生成器
有时我们需要能够生成类似MySQL自增ID这样不断增大,同时又不会重复的id。以支持业务中的高并发场景。比较典型的,电商促销时,短时间内会有大量的订单涌入到系统,比如每秒10w+。明星出轨时,会有大量热情的粉丝发微博以表心意,同样会在短时间内产生大量的消息。
在插入数据库之前,我们需要给这些消息、订单先打上一个ID,然后再插入到我们的数据库。对这个id的要求是希望其中能带有一些时间信息,这样即使我们后端的系统对消息进行了分库分表,也能够以时间顺序对这些消息进行排序。
Twitter的snowflake算法是这种场景下的一个典型解法。先来看看snowflake是怎么一回事,见图 6-1:
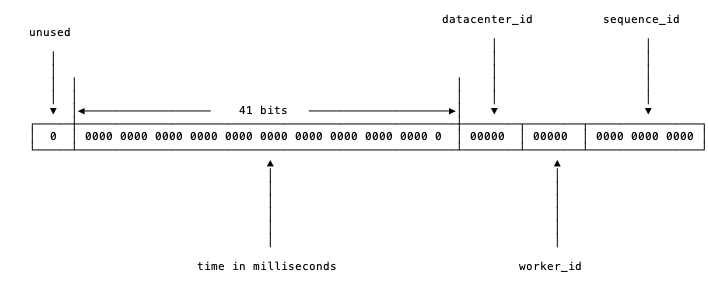
图 6-1 snowflake中的比特位分布
首先确定我们的数值是64位,int64类型,被划分为四部分,不含开头的第一个bit,因为这个bit是符号位。用41位来表示收到请求时的时间戳,单位为毫秒,然后五位来表示数据中心的id,然后再五位来表示机器的实例id,最后是12位的循环自增id(到达1111,1111,1111后会归0)。
这样的机制可以支持我们在同一台机器上,同一毫秒内产生2 ^ 12 = 4096条消息。一秒共409.6万条消息。从值域上来讲完全够用了。
数据中心加上实例id共有10位,可以支持我们每数据中心部署32台机器,所有数据中心共1024台实例。
表示timestamp的41位,可以支持我们使用69年。当然,我们的时间毫秒计数不会真的从1970年开始记,那样我们的系统跑到2039/9/7 23:47:35就不能用了,所以这里的timestamp只是相对于某个时间的增量,比如我们的系统上线是2018-08-01,那么我们可以把这个timestamp当作是从2018-08-01 00:00:00.000的偏移量。
6.1.1 worker_id分配
timestamp,datacenter_id,worker_id和sequence_id这四个字段中,timestamp和sequence_id是由程序在运行期生成的。但datacenter_id和worker_id需要我们在部署阶段就能够获取得到,并且一旦程序启动之后,就是不可更改的了(想想,如果可以随意更改,可能被不慎修改,造成最终生成的id有冲突)。
一般不同数据中心的机器,会提供对应的获取数据中心id的API,所以datacenter_id我们可以在部署阶段轻松地获取到。而worker_id是我们逻辑上给机器分配的一个id,这个要怎么办呢?比较简单的想法是由能够提供这种自增id功能的工具来支持,比如MySQL:
mysql> insert into a (ip) values("10.1.2.101");
Query OK, 1 row affected (0.00 sec)
mysql> select last_insert_id();
+------------------+
| last_insert_id() |
+------------------+
| 2 |
+------------------+
1 row in set (0.00 sec)从MySQL中获取到worker_id之后,就把这个worker_id直接持久化到本地,以避免每次上线时都需要获取新的worker_id。让单实例的worker_id可以始终保持不变。
当然,使用MySQL相当于给我们简单的id生成服务增加了一个外部依赖。依赖越多,我们的服务的可运维性就越差。
考虑到集群中即使有单个id生成服务的实例挂了,也就是损失一段时间的一部分id,所以我们也可以更简单暴力一些,把worker_id直接写在worker的配置中,上线时,由部署脚本完成worker_id字段替换。
6.1.2 开源实例
6.1.2.1 标准snowflake实现
github.com/bwmarrin/snowflake 是一个相当轻量化的snowflake的Go实现。其文档对各位使用的定义见图 6-2所示。

图 6-2 snowflake库
和标准的snowflake完全一致。使用上比较简单:
package main
import (
"fmt"
"os"
"github.com/bwmarrin/snowflake"
)
func main() {
n, err := snowflake.NewNode(1)
if err != nil {
println(err)
os.Exit(1)
}
for i := 0; i < 3; i++ {
id := n.Generate()
fmt.Println("id", id)
fmt.Println(
"node: ", id.Node(),
"step: ", id.Step(),
"time: ", id.Time(),
"\n",
)
}
}当然,这个库也给我们留好了定制的后路,其中预留了一些可定制字段:
// Epoch is set to the twitter snowflake epoch of Nov 04 2010 01:42:54 UTC
// You may customize this to set a different epoch for your application.
Epoch int64 = 1288834974657
// Number of bits to use for Node
// Remember, you have a total 22 bits to share between Node/Step
NodeBits uint8 = 10
// Number of bits to use for Step
// Remember, you have a total 22 bits to share between Node/Step
StepBits uint8 = 12Epoch就是本节开头讲的起始时间,NodeBits指的是机器编号的位长,StepBits指的是自增序列的位长。
6.1.2.2 sonyflake
sonyflake是Sony公司的一个开源项目,基本思路和snowflake差不多,不过位分配上稍有不同,见图 6-3:

图 6-3 sonyflake
这里的时间只用了39个bit,但时间的单位变成了10ms,所以理论上比41位表示的时间还要久(174年)。
Sequence ID和之前的定义一致,Machine ID其实就是节点id。sonyflake与众不同的地方在于其在启动阶段的配置参数:
func NewSonyflake(st Settings) *SonyflakeSettings数据结构如下:
type Settings struct {
StartTime time.Time
MachineID func() (uint16, error)
CheckMachineID func(uint16) bool
}StartTime选项和我们之前的Epoch差不多,如果不设置的话,默认是从2014-09-01 00:00:00 +0000 UTC开始。
MachineID可以由用户自定义的函数,如果用户不定义的话,会默认将本机IP的低16位作为machine id。
CheckMachineID是由用户提供的检查MachineID是否冲突的函数。这里的设计还是比较巧妙的,如果有另外的中心化存储并支持检查重复的存储,那我们就可以按照自己的想法随意定制这个检查MachineID是否冲突的逻辑。如果公司有现成的Redis集群,那么我们可以很轻松地用Redis的集合类型来检查冲突。
redis 127.0.0.1:6379> SADD base64_encoding_of_last16bits MzI0Mgo=
(integer) 1
redis 127.0.0.1:6379> SADD base64_encoding_of_last16bits MzI0Mgo=
(integer) 0使用起来也比较简单,有一些逻辑简单的函数就略去实现了:
package main
import (
"fmt"
"os"
"time"
"github.com/sony/sonyflake"
)
func getMachineID() (uint16, error) {
var machineID uint16
var err error
machineID = readMachineIDFromLocalFile()
if machineID == 0 {
machineID, err = generateMachineID()
if err != nil {
return 0, err
}
}
return machineID, nil
}
func checkMachineID(machineID uint16) bool {
saddResult, err := saddMachineIDToRedisSet()
if err != nil || saddResult == 0 {
return true
}
err := saveMachineIDToLocalFile(machineID)
if err != nil {
return true
}
return false
}
func main() {
t, _ := time.Parse("2006-01-02", "2018-01-01")
settings := sonyflake.Settings{
StartTime: t,
MachineID: getMachineID,
CheckMachineID: checkMachineID,
}
sf := sonyflake.NewSonyflake(settings)
id, err := sf.NextID()
if err != nil {
fmt.Println(err)
os.Exit(1)
}
fmt.Println(id)
}