Objc.io期刊文章(共24期)
- 更轻量级的ViewController
- 更轻量级的ViewController
- 并发编程
- 视图
- Core Data
- iOS 7
- 初识 TextKit
- UICollectionView + UIKit 力学
- View Controller 转场
- 从 NSURLConnection 到 NSURLSession
- iOS 7 的多任务
- iOS 7 : 隐藏技巧和变通之道
- 为 iOS 7 重新设计 App
- Build 工具
- Foundation
- 四轴无人机项目
- 字符串
- 同步数据
- Android
- iOS 开发者的 Android 第一课
- Android Intents
- 响应式 Android 应用
- Android 通知中心
- Android 中的 SQLite 数据库支持
- 依赖注入和注解,为什么 Java 比你想象的要好
- 动画
- 架构
- 回到 Mac
- 测试
- Swift
- 安全
- 游戏
- 调试
- 访谈
- 相机与照片
- iOS 项目管理
- 视频
- 音频
Core Data 可能是 OS X 和 iOS 里面最容易被误解的框架之一,为了帮助大家理解,我们将快速的研究 Core Data,让大家对它有一个初步的了解,对于想要正确使用 Core Data 的同学来说,理解它的概念是非常必要的。几乎所有对 Core Data 感到失望的原因都是因为对它工作机制的错误理解。让我们开始吧:
Core Data 是什么?
大概八年前,2005年的四月份,Apple 发布了 OS X 10.4,正是在这个版本中 Core Data 框架发布了。那个时候 YouTube 也刚发布。
Core Data 是一个模型层的技术。Core Data 帮助你建立代表程序状态的模型层。Core Data 也是一种持久化技术,它能将模型对象的状态持久化到磁盘,但它最重要的特点是:Core Data 不仅是一个加载、保存数据的框架,它还能和内存中的数据很好的共事。
如果你之前曾经接触过 Object-relational maping (O/RM):Core Data不是一个 O/RM,但它比 O/RM 能做的更多。如果你之前曾经接触过 SQL wrappers:Core Data 不是一个 SQL wrapper。它默认使用 SQL,但是,它是一种更高级的抽象概念。如果你需要的是一个 O/RM 或者 SQL wrapper,那么 Core Data 并不适合你。
对象图管理(object graph management)是 Core Data 最强大的功能之一。为了更好利用 Core Data,这是你需要理解的一块内容。
还有一点要注意:Core Data 是完全独立于任何 UI 层级的框架。它是作为模型层框架被设计出来的。在 OS X 中,甚至在一些后台驻留程序中,Core Data 都起着非常重要的意义。
堆栈
Core Data 有相当多可用的组件。这是一个非常灵活的技术。在大多数的使用情况下,设置都相当简单。
当所有的组件都捆绑到一起的时候,我们把它称作 Core Data 堆栈,这个堆栈有两个主要部分。一部分是关于对象图管理,这正是你需要很好掌握的那一部分,并且知道怎么使用。第二部分是关于持久化,比如,保存你模型对象的状态,然后再恢复模型对象的状态。
在两个部分之间,即堆栈中间,是持久化存储协调器(persistent store coordinator),也被称为中间审查者。它将对象图管理部分和持久化部分捆绑在一起,当它们两者中的任何一部分需要和另一部分交流时,这便需要持久化存储协调器来调节了。
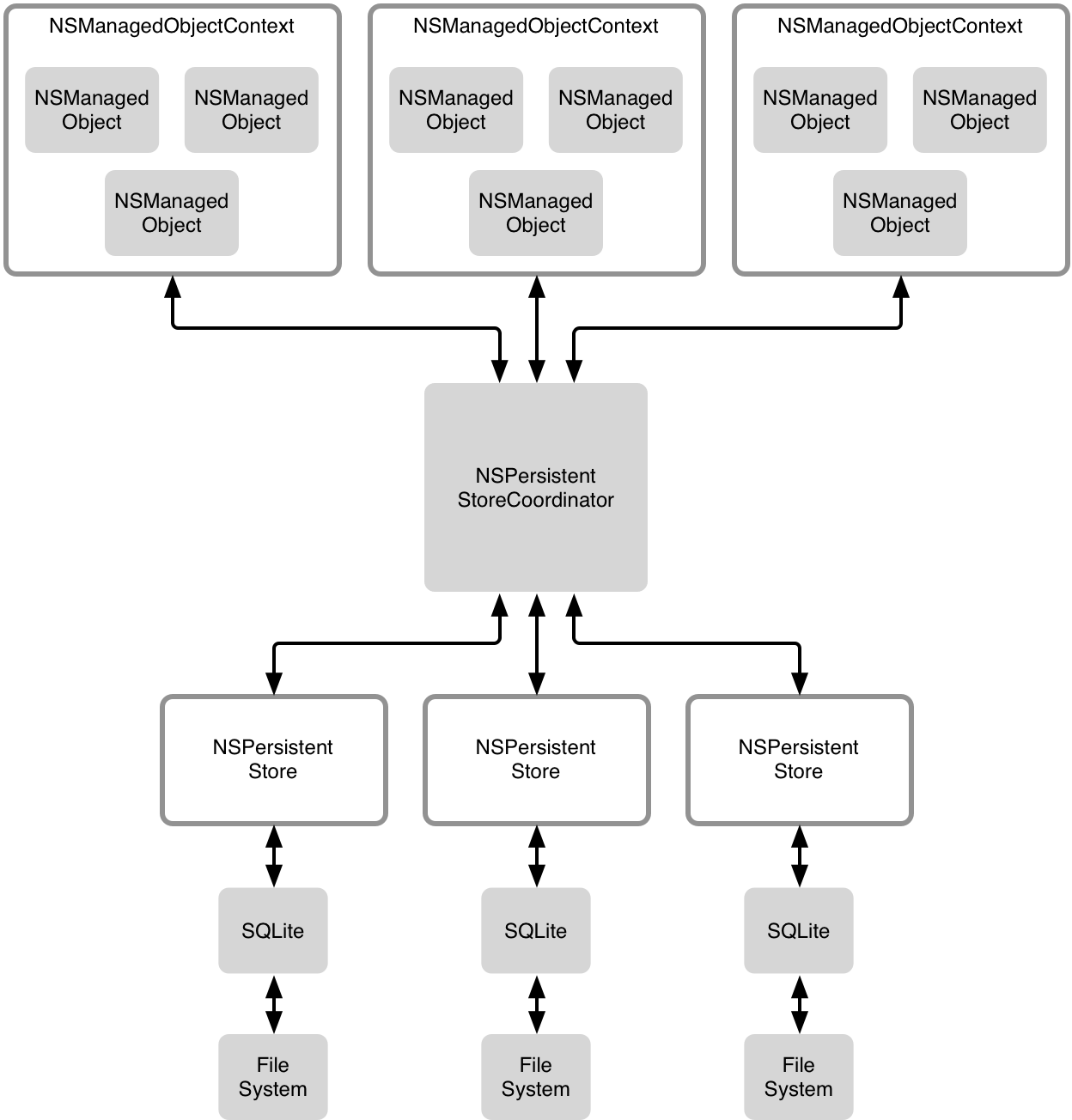
对象图管理是你程序模型层的逻辑存在的地方。模型层的对象存在于一个 context 内。在大多数的设置中,存在一个 context ,并且所有的对象存在于那个 context 中。Core Data 支持多个 contexts,不过对于更高级的使用情况才用。注意每个 context 和其他 context 都是完全独立的,一会儿我们将会谈到。需要记住的是,对象和它们的 context 是相关联的。每个被管理的对象都知道自己属于哪个 context,并且每个 context 都知道自己管理着哪些对象。
堆栈的另一部分就是持久了,即 Core Data 从文件系统中读或写数据。每个持久化存储协调器(persistent store coordinator)都有一个属于自己的持久化存储(persistent store),并且这个 store 在文件系统中与 SQLite 数据库交互。为了支持更高级的设置,Core Data 可以将多个 stores 附属于同一个持久化存储协调器,并且除了存储 SQL 格式外,还有很多存储类型可供选择。
最常见的解决方案如下图所示:

组件如何一起工作
让我们快速的看一个例子,看看组件是如何协同工作的。在我们的文章《一个完成的 Core Data 应用》中,正好有一个实体,即一种对象:我们有一个 Item 实体对应一个 title。每一个 item 可以拥有子 items,因此,我们有一个父子关系。
这是我们的数据模型。正如我们在《数据模型和模型对象》一文中提到的一样,在 Core Data 中有一种特别的对象——实体。在这种情况下,我们只有一个实体:Item 实体。同样的,我们有一个 NSManagedObject 的子类,叫做 Item。这个 Item 实体映射到 Item 类上。在数据模型的文章中会详细的谈到这个。
我们的程序仅有一个根 Item。这并没有什么奇妙的地方。它是一个我们用来显示底层 item 等级的 item。它是一个我们永远不会为其设置父类的 Item。
当程序运行时,我们像上面图片描绘的一样设置我们的堆栈,一个存储,一个 managed object context,以及一个持久化存储协调器来将它们关联起来。
在第一次运行时,我们并没有任何 items。我们需要做的第一件事就是创建根 item。你通过将它们插入 context 来增加管理对象。
创建对象
插入对象的方法似乎很笨重,我们通过 NSEntityDescription 的方法来插入:
+ (id)insertNewObjectForEntityForName:(NSString *)entityName
inManagedObjectContext:(NSManagedObjectContext *)context我们建议你增加两个方便的方法到你的模型类中:
+ (NSString *)entityName
{
return @“Item”;
}
+ (instancetype)insertNewObjectInManagedObjectContext:(NSManagedObjectContext *)moc;
{
return [NSEntityDescription insertNewObjectForEntityForName:[self entityName]
inManagedObjectContext:moc];
}现在,我们可以像这样插入我们的根对象了:
Item *rootItem = [Item insertNewObjectInManagedObjectContext:managedObjectContext];现在,在我们的 managed object context 中有一个唯一的 item。Context 知道这是一个新插入进来需要被管理的对象,并且被管理的对象 rootItem 知道这个 Context(它有一个 -managedObjectContext 方法)。
保存改变
虽然我们已经谈到这了,可是我们还是没有接触到持久化存储协调器或持久化存储。新的模型对象—rootItem,仅仅在内存中。如果我们想要保存模型对象的状态(在这种情况下只是一个对象),我们需要保存 context:
NSError *error = nil;
if (! [managedObjectContext save:&error]) {
// 啊,哦. 有错误发生了 :(
}这个时候,很多事情将要发生。首先是 managed object context 计算出改变的内容。这是 context 的职责,追踪出任何你在 context 管理对象中做出的改变。在我们的例子中,我们到现在做出的唯一改变就是插入一个对象,即我们的 rootItem。
Managed object context 将这些改变传给持久化存储协调器,让它将这些改变传给 store。持久化存储协调器会协调 store(在我们的例子中,store 是一个 SQL 数据库)来将我们插入的对象写入到磁盘上的 SQL 数据库。NSPersistentStore 类管理着和 SQLite 的实际交互,并且产生需要被执行的 SQL 代码。持久化存储协调器的角色就是简化调整 store 和 context 之间的交互过程。在我们的例子中,这个角色相当简单,但是,复杂的设置可以有多个 stores 和多个 contexts。
更新关系
Core Data 的优势在于管理关系。让我们着眼于简单的情况:增加我们第二个 item,并且使它成为 rootItem 的子 item:
Item *item = [Item insertNewObjectInManagedObjectContext:managedObjectContext];
item.parent = rootItem;
item.title = @"foo";好了。同样的,这些改变仅仅存在于 managed object context 中。一旦我们保存了 context,managed object context 将会通知持久化存储协调器,像增加第一个对象一样增加新创建的对象到数据库文件中。但这也将会更新第二个 item 与第一个 item 之间的关系。记住 Item 实体是如何有一个父子关系的。它们之间有相反的关系。因为我们设置第一个 item 为第二个 item 的父亲(parent)时,第二个 item 将会变成第一个 item 的儿子(child)。Managed object context 追踪这些关系,持久化存储协调器和 store 保存这些关系到磁盘。
获取对象
我们已经使用我们的程序一会儿了,并且已经为 rootItem 增加了一些子 items,甚至增加子 items 到子 items。然而,我们再次启动我们的程序。Core Data 已经将这些 items 之间的关系保存到了数据库文件。对象图是持久化的。我们现在需要取出根 item,所以我们可以显示底层 items 的列表。有两种方法可以达到这个效果。我们先看简单点的方法。
当 rootItem 对象创建并保存之后我们可以向它请求它的 NSManagedObjectID。这是一个不透明的对象,可以唯一代表 rootItem。我们可以保存这个对象到 NSUSerDefaults,像这样:
NSUserDefaults *defaults = [NSUserDefaults standardUserDefaults];
[defaults setURL:rootItem.objectID.URIRepresentation forKey:@"rootItem"];现在,当程序重新运行时,我们可以像这样返回得到这个对象:
NSUserDefaults *defaults = [NSUserDefaults standardUserDefaults];
NSURL *uri = [defaults URLForKey:@"rootItem"];
NSManagedObjectID *moid = [managedObjectContext.persistentStoreCoordinator managedObjectIDForURIRepresentation:uri];
NSError *error = nil;
Item *rootItem = (id) [managedObjectContext existingObjectWithID:moid error:&error];很明显,在一个真正的程序中,我们需要检查 NSUserDefaults 是否真正返回一个有效值。
刚才的操作是 managed object context 要求持久化存储协调器从数据库取得指定的对象。根对象现在被恢复到 context 中。然而,其他所有的 items 仍然不在内存中。
rootItem 有一个子关系叫做 children。但现在那儿还没有什么。我们想要显示 rootItem 的子 item,因此我们需要调用:
NSOrderedSet *children = rootItem.children;现在发生的是,context 标注这个 rootItem 的子 item 为所谓的故障。Core Data 已经标注这个关系为仍需要被解决。既然我们已经在这个时候访问了它,context 将会自动配合持久化存储协调器来将这些子 items 载入到 context 中。
这听起来可能非常不重要,但是在这个时候真正发生了很多事情。如果任何子对象偶然发生在内存中,Core Data 保证会复用那些对象。这是Core Data 独一无二的功能。在 context 内,从不会存在第二个相同的单一对象来代表一个给定的 item。
其次,持久化存储协调器有它自己内部对象值的缓存。如果 context 需要一个指定的对象(比如一个子 item),并且持久化存储协调器在缓存中已经有需要的值,那么,对象(即这个 item)可以不通过 store 而被直接加到 context。这很重要,因为访问 store 就意味着执行 SQL 代码,这比使用内存中存在的值要慢很多。
随着我们遍历 item 的子 item,以及子 item 的子 item,我们慢慢地把整个对象图引用到了 managed object context。而这些对象都在内存中之后,操作对象以及传递关系就会变得非常快,因为我们只是在 managed object context 里操作。我们跟本不需要访问持久化存储协调器。在我们的 Item 对象上访问 title,parent 和 children 是非常快而且高效的。
由于它会影响性能,所以了解数据在这些情况下怎么取出来是非常重要的。在我们特定的情况下,由于我们并没接触到太多的数据,所以这并不算什么,但是一旦你需要处理的数据量较大,你将需要了解在背后发生了什么。
当你遍历一个关系时(比如在我们例子中的 parent 或 children 关系)下面三种情况将有一种会发生:(1)对象已经在 context 中,这种操作基本上是没有任何代价的。(2)对象不在 context 中,但是因为你最近从 store 中取出过对象,所以持久化存储协调器缓存了对象的值。这个操作还算廉价(但是,一些操作会被锁住)。操作耗费最昂贵的情况是(3),当 context 和持久化存储协调器都是第一次访问这个对象,这种情况必须通过 store 从 SQLite 数据库取回。最后一种情况比(1)和(2)需要付出更多代价。
如果你知道你必须从 store 取回对象(比如你已经知道没有这些对象),当你限制一次取回多少个对象时,将会产生很大的不同。在我们的例子中,我们希望一次性取出所有子 items,而不是一个接一个。我们可以通过一个特别的技巧 NSFetchRequest。但是我们要注意,当我们需要做这个操作时,我们只需要执行一次取出请求,因为一次取出请求将会造成(3)发生;这将总是独占 SQLite 数据库的访问。因此,当需要显著提升性能时,检查对象是否已经存在将变得非常有意义。你可以使用-[NSManagedObjectContext objectRegisteredForID:]来检测一个对象是否已经存在。
改变对象的值
现在,我们可以说,我们已经改变我们一个 Item 对象的 title:
item.title = @"New title";当我们这样做时,item 的 title 改变了。此外,managed object context 会标注这个对象(item)已经被改变,这样当我们在 context 中调用 -save: 时,这个对象将会通过持久化存储协调器和附属的 store 保存起来。context最关键的职责之一就是跟踪改变。
从最后一次保存开始,context 知道哪些对象被插入,改变以及删除。你可以通过 -insertedObjects, -updatedObjects, 以及 –deletedObjects 方法来达到这样的效果。同样的,你可以通过 -changedValues 方法来询问一个被管理的对象哪些值被改变了。这个方法正是 Core Data 能够将你做出的改变推入到数据库的原因。
当我们插入一个新的 Item 对象时,Core Data 知道需要将这些改变存入 store。那么,当你改变对象的 title 时,也会发生同样的事情。
保存 values 需要协调持久化存储协调器和持久化 store 依次访问 SQLite 数据库。和在内存中操作对象比起来,取出对象和值,访问 store 和数据库是非常耗费资源的。不管你保存了多少更改,一次保存的代价是固定的。并且每个变化都有成本。这是 SQLite 的工作方式。当你做很多更改的时候,需要将更改打包,并批量更改。如果你保存每一次更改,将要付出很高的代价,因为你需要经常做保存操作。如果你很少做保存,那么你将会有一大批更改交给 SQLite 处理。
同样需要注意的是保存操作是原子性的,要么所有的更改会被提交给 store/SQLite 数据库,要么任何更改都不被保存。当实现自定义 NSIncrementalStore 基类时,这一点一定要牢记在心。要么确保保存永远不会失败(比如说不会发生冲突),要么当保存失败时,你 store 的基类需要恢复所有的改变。否则,在内存中的对象图最终和保存在 store 中的对象不一致。
如果你使用一个简单的设置,保存操作通常不会失败。但是 Core Data 允许每个持久化存储协调器有多个 context,所以你可能陷入持久化存储协调器层级的冲突之中。改变是对于每个 context 的,另一个 context 的更改可能导致冲突。Core Data 甚至允许完全不同的堆栈访问磁盘上相同的 SQLite 数据库。这明显也会导致冲突(比如,一个 context 想要更新一个对象的值,而另一个 context 想要删除这个对象)。另一个导致保存失败的原因可能是验证。Core Data 支持复杂的对象验证策略。这是一个高级话题。一个简单的验证规则可能是: Item 的 title 不能超过300个字符。但是 Core Data 也支持通过属性进行复杂的验证策略。
结束语
如果 Core Data 看起来让人害怕,这最有可能是因为它的灵活性允许你可以通过非常复杂的方法使用它。始终记住:尽可能保持简单。它会让开发变得更容易,并且把你和你的用户从麻烦中拯救出来。除非你确信它会带来帮助,才去使用更复杂的东西,比如说是 background contexts。
当你开始使用一个简单的 Core Data 堆栈,并且使用我们在这篇文章中讲到的知识吧,你将很快会真正体会到 Core Data 能为你做什么,并且学到它是怎么缩短你开发周期的。
译文 Core Data概述
精细校对 @shjborage