Objc.io期刊文章(共24期)
- 更轻量级的ViewController
- 更轻量级的ViewController
- 并发编程
- 视图
- Core Data
- iOS 7
- 初识 TextKit
- UICollectionView + UIKit 力学
- View Controller 转场
- 从 NSURLConnection 到 NSURLSession
- iOS 7 的多任务
- iOS 7 : 隐藏技巧和变通之道
- 为 iOS 7 重新设计 App
- Build 工具
- Foundation
- 四轴无人机项目
- 字符串
- 同步数据
- Android
- iOS 开发者的 Android 第一课
- Android Intents
- 响应式 Android 应用
- Android 通知中心
- Android 中的 SQLite 数据库支持
- 依赖注入和注解,为什么 Java 比你想象的要好
- 动画
- 架构
- 回到 Mac
- 测试
- Swift
- 安全
- 游戏
- 调试
- 访谈
- 相机与照片
- iOS 项目管理
- 视频
- 音频
一点背景知识
OpenCV 是一个开源的计算机视觉和机器学习库。它包含成千上万优化过的算法,为各种计算机视觉应用提供了一个通用工具包。根据这个项目的关于页面,OpenCV 已被广泛运用在各种项目上,从谷歌街景的图片拼接,到交互艺术展览的技术实现中,都有 OpenCV 的身影。
OpenCV 起始于 1999 年 Intel 的一个内部研究项目。从那时起,它的开发就一直很活跃。进化到现在,它已支持如 OpenCL 和 OpenGL 等现代技术,也支持如 iOS 和 Android 等平台。
1999 年,半条命发布后大红大热。Intel 奔腾 3 处理器是当时最高级的 CPU,400-500 MHZ 的时钟频率已被认为是相当快。2006 年 OpenCV 1.0 版本发布的时候,当时主流 CPU 的性能也只和 iPhone 5 的 A6 处理器相当。尽管计算机视觉从传统上被认为是计算密集型应用,但我们的移动设备性能已明显地超出能够执行有用的计算机视觉任务的阈值,带着摄像头的移动设备可以在计算机视觉平台上大有所为。
在本文中,我会从一个 iOS 开发者的视角概述一下 OpenCV,并介绍一点基础的类和概念。随后,会讲到如何集成 OpenCV 到你的 iOS 项目中以及一些 Objective-C++ 基础知识。最后,我们会看一个 demo 项目,看看如何在 iOS 设备上使用 OpenCV 实现人脸检测与人脸识别。
OpenCV 概述
概念
OpenCV 的 API 是 C++ 的。它由不同的模块组成,这些模块中包含范围极为广泛的各种方法,从底层的图像颜色空间转换到高层的机器学习工具。
使用 C++ API 并不是绝大多数 iOS 开发者每天都做的事,你需要使用 Objective-C++ 文件来调用 OpenCV 的函数。 也就是说,你不能在 Swift 或者 Objective-C 语言内调用 OpenCV 的函数。 这篇 OpenCV 的 iOS 教程告诉你只要把所有用到 OpenCV 的类的文件后缀名改为 .mm 就行了,包括视图控制器类也是如此。这么干或许能行得通,却不是什么好主意。正确的方式是给所有你要在 app 中使用到的 OpenCV 功能写一层 Objective-C++ 封装。这些 Objective-C++ 封装把 OpenCV 的 C++ API 转化为安全的 Objective-C API,以方便地在所有 Objective-C 类中使用。走封装的路子,你的工程中就可以只在这些封装中调用 C++ 代码,从而避免掉很多让人头痛的问题,比如直接改文件后缀名会因为在错误的文件中引用了一个 C++ 头文件而产生难以追踪的编译错误。
OpenCV 声明了命名空间 cv,因此 OpenCV 的类的前面会有个 cv:: 前缀,就像 cv::Mat、 cv::Algorithm 等等。你也可以在 .mm 文件中使用 using namespace cv 来避免在一堆类名前使用 cv:: 前缀。但是,在某些类名前你必须使用命名空间前缀,比如 cv::Rect 和 cv::Point,因为它们会跟定义在 MacTypes.h 中的 Rect 和 Point 相冲突。尽管这只是个人偏好问题,我还是偏向在任何地方都使用 cv:: 以保持一致性。
模块
下面是在官方文档中列出的最重要的模块。
- core:简洁的核心模块,定义了基本的数据结构,包括稠密多维数组
Mat和其他模块需要的基本函数。 - imgproc:图像处理模块,包括线性和非线性图像滤波、几何图像转换 (缩放、仿射与透视变换、一般性基于表的重映射)、颜色空间转换、直方图等等。
- video:视频分析模块,包括运动估计、背景消除、物体跟踪算法。
- calib3d:包括基本的多视角几何算法、单体和立体相机的标定、对象姿态估计、双目立体匹配算法和元素的三维重建。
- features2d:包含了显著特征检测算法、描述算子和算子匹配算法。
- objdetect:物体检测和一些预定义的物体的检测 (如人脸、眼睛、杯子、人、汽车等)。
- ml:多种机器学习算法,如 K 均值、支持向量机和神经网络。
- highgui:一个简单易用的接口,提供视频捕捉、图像和视频编码等功能,还有简单的 UI 接口 (iOS 上可用的仅是其一个子集)。
- gpu:OpenCV 中不同模块的 GPU 加速算法 (iOS 上不可用)。
- ocl:使用 OpenCL 实现的通用算法 (iOS 上不可用)。
- 一些其它辅助模块,如 Python 绑定和用户贡献的算法。
基础类和操作
OpenCV 包含几百个类。为简便起见,我们只看几个基础的类和操作,进一步阅读请参考全部文档。过一遍这几个核心类应该足以对这个库的机理产生一些感觉认识。
cv::Mat
cv::Mat 是 OpenCV 的核心数据结构,用来表示任意 N 维矩阵。因为图像只是 2 维矩阵的一个特殊场景,所以也是使用 cv::Mat 来表示的。也就是说,cv::Mat 将是你在 OpenCV 中用到最多的类。
一个 cv::Mat 实例的作用就像是图像数据的头,其中包含着描述图像格式的信息。图像数据只是被引用,并能为多个 cv::Mat 实例共享。OpenCV 使用类似于 ARC 的引用计数方法,以保证当最后一个来自 cv::Mat 的引用也消失的时候,图像数据会被释放。图像数据本身是图像连续的行的数组 (对 N 维矩阵来说,这个数据是由连续的 N-1 维数据组成的数组)。使用 step[] 数组中包含的值,图像的任一像素地址都可通过下面的指针运算得到:
uchar *pixelPtr = cvMat.data + rowIndex * cvMat.step[0] + colIndex * cvMat.step[1]每个像素的数据格式可以通过 type() 方法获得。除了常用的每通道 8 位无符号整数的灰度图 (1 通道,CV_8UC1) 和彩色图 (3 通道,CV_8UC3),OpenCV 还支持很多不常用的格式,例如 CV_16SC3 (每像素 3 通道,每通道使用 16 位有符号整数),甚至 CV_64FC4 (每像素 4 通道,每通道使用 64 位浮点数)。
cv::Algorithm
Algorithm 是 OpenCV 中实现的很多算法的抽象基类,包括将在我们的 demo 工程中用到的 FaceRecognizer。它提供的 API 与苹果的 Core Image 框架中的 CIFilter 有些相似之处。创建一个 Algorithm 的时候使用算法的名字来调用 Algorithm::create(),并且可以通过 get() 和 set()方法来获取和设置各个参数,这有点像是键值编码。另外,Algorithm 从底层就支持从/向 XML 或 YAML 文件加载/保存参数的功能。
在 iOS 上使用 OpenCV
添加 OpenCV 到你的工程中
集成 OpenCV 到你的工程中有三种方法:
Objective-C++
如前面所说,OpenCV 是一个 C++ 的 API,因此不能直接在 Swift 和 Objective-C 代码中使用,但能在 Objective-C++ 文件中使用。
Objective-C++ 是 Objective-C 和 C++ 的混合物,让你可以在 Objective-C 类中使用 C++ 对象。clang 编译器会把所有后缀名为 .mm 的文件都当做是 Objective-C++。一般来说,它会如你所期望的那样运行,但还是有一些使用 Objective-C++ 的注意事项。内存管理是你最应该格外注意的点,因为 ARC 只对 Objective-C 对象有效。当你使用一个 C++ 对象作为类属性的时候,其唯一有效的属性就是 assign。因此,你的 dealloc 函数应确保 C++ 对象被正确地释放了。
第二重要的点就是,如果你在 Objective-C++ 头文件中引入了 C++ 头文件,当你在工程中使用该 Objective-C++ 文件的时候就泄露了 C++ 的依赖。任何引入你的 Objective-C++ 类的 Objective-C 类也会引入该 C++ 类,因此该 Objective-C 文件也要被声明为 Objective-C++ 的文件。这会像森林大火一样在工程中迅速蔓延。所以,应该把你引入 C++ 文件的地方都用 #ifdef __cplusplus 包起来,并且只要可能,就尽量只在 .mm 实现文件中引入 C++ 头文件。
要获得更多如何混用 C++ 和 Objective-C 的细节,请查看 Matt Galloway 写的这篇教程。
Demo:人脸检测与识别
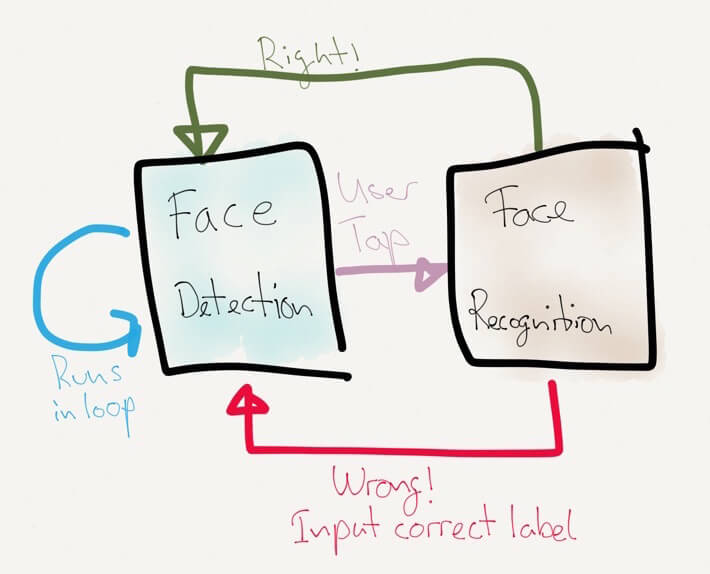
现在,我们对 OpenCV 及如何把它集成到我们的应用中有了大概认识,那让我们来做一个小 demo 应用:从 iPhone 的摄像头获取视频流,对它持续进行人脸检测,并在屏幕上标出来。当用户点击一个脸孔时,应用会尝试识别这个人。如果识别结果正确,用户必须点击 “Correct”。如果识别错误,用户必须选择正确的人名来纠正错误。我们的人脸识别器就会从错误中学习,变得越来越好。
本 demo 应用的源码可从 GitHub 获得。
视频拍摄
OpenCV 的 highgui 模块中有个类,CvVideoCamera,它把 iPhone 的摄像机抽象出来,让我们的 app 通过一个代理函数 - (void)processImage:(cv::Mat&)image 来获得视频流。CvVideoCamera 实例可像下面这样进行设置:
CvVideoCamera *videoCamera = [[CvVideoCamera alloc] initWithParentView:view];
videoCamera.defaultAVCaptureDevicePosition = AVCaptureDevicePositionFront;
videoCamera.defaultAVCaptureSessionPreset = AVCaptureSessionPreset640x480;
videoCamera.defaultAVCaptureVideoOrientation = AVCaptureVideoOrientationPortrait;
videoCamera.defaultFPS = 30;
videoCamera.grayscaleMode = NO;
videoCamera.delegate = self;摄像头的帧率被设置为 30 帧每秒, 我们实现的 processImage 函数将每秒被调用 30 次。因为我们的 app 要持续不断地检测人脸,所以我们应该在这个函数里实现人脸的检测。要注意的是,如果对某一帧进行人脸检测的时间超过 1/30 秒,就会产生掉帧现象。
人脸检测
其实你并不需要使用 OpenCV 来做人脸检测,因为 Core Image 已经提供了 CIDetector 类。用它来做人脸检测已经相当好了,并且它已经被优化过,使用起来也很容易:
CIDetector *faceDetector = [CIDetector detectorOfType:CIDetectorTypeFace context:context options:@{CIDetectorAccuracy: CIDetectorAccuracyHigh}];
NSArray *faces = [faceDetector featuresInImage:image];从该图片中检测到的每一张面孔都在数组 faces 中保存着一个 CIFaceFeature 实例。这个实例中保存着这张面孔的所处的位置和宽高,除此之外,眼睛和嘴的位置也是可选的。
另一方面,OpenCV 也提供了一套物体检测功能,经过训练后能够检测出任何你需要的物体。该库为多个场景自带了可以直接拿来用的检测参数,如人脸、眼睛、嘴、身体、上半身、下半身和笑脸。检测引擎由一些非常简单的检测器的级联组成。这些检测器被称为 Haar 特征检测器,它们各自具有不同的尺度和权重。在训练阶段,决策树会通过已知的正确和错误的图片进行优化。关于训练与检测过程的详情可参考此原始论文。当正确的特征级联及其尺度与权重通过训练确立以后,这些参数就可被加载并初始化级联分类器了:
// 正面人脸检测器训练参数的文件路径
NSString *faceCascadePath = [[NSBundle mainBundle] pathForResource:@"haarcascade_frontalface_alt2"
ofType:@"xml"];
const CFIndex CASCADE_NAME_LEN = 2048;
char *CASCADE_NAME = (char *) malloc(CASCADE_NAME_LEN);
CFStringGetFileSystemRepresentation( (CFStringRef)faceCascadePath, CASCADE_NAME, CASCADE_NAME_LEN);
CascadeClassifier faceDetector;
faceDetector.load(CASCADE_NAME);这些参数文件可在 OpenCV 发行包里的 data/haarcascades 文件夹中找到。
在使用所需要的参数对人脸检测器进行初始化后,就可以用它进行人脸检测了:
cv::Mat img;
vector<cv::Rect> faceRects;
double scalingFactor = 1.1;
int minNeighbors = 2;
int flags = 0;
cv::Size minimumSize(30,30);
faceDetector.detectMultiScale(img, faceRects,
scalingFactor, minNeighbors, flags
cv::Size(30, 30) );检测过程中,已训练好的分类器会用不同的尺度遍历输入图像的每一个像素,以检测不同大小的人脸。参数 scalingFactor 决定每次遍历分类器后尺度会变大多少倍。参数 minNeighbors 指定一个符合条件的人脸区域应该有多少个符合条件的邻居像素才被认为是一个可能的人脸区域;如果一个符合条件的人脸区域只移动了一个像素就不再触发分类器,那么这个区域非常可能并不是我们想要的结果。拥有少于 minNeighbors 个符合条件的邻居像素的人脸区域会被拒绝掉。如果 minNeighbors 被设置为 0,所有可能的人脸区域都会被返回回来。参数 flags 是 OpenCV 1.x 版本 API 的遗留物,应该始终把它设置为 0。最后,参数 minimumSize 指定我们所寻找的人脸区域大小的最小值。faceRects 向量中将会包含对 img 进行人脸识别获得的所有人脸区域。识别的人脸图像可以通过 cv::Mat 的 () 运算符提取出来,调用方式很简单:cv::Mat faceImg = img(aFaceRect)。
不管是使用 CIDetector 还是 OpenCV 的 CascadeClassifier,只要我们获得了至少一个人脸区域,我们就可以对图像中的人进行识别了。
人脸识别
OpenCV 自带了三个人脸识别算法:Eigenfaces,Fisherfaces 和局部二值模式直方图 (LBPH)。如果你想知道它们的工作原理及相互之间的区别,请阅读 OpenCV 的详细文档。
针对于我们的 demo app,我们将采用 LBPH 算法。因为它会根据用户的输入自动更新,而不需要在每添加一个人或纠正一次出错的判断的时候都要重新进行一次彻底的训练。
要使用 LBPH 识别器,我们也用 Objective-C++ 把它封装起来。这个封装中暴露以下函数:
+ (FJFaceRecognizer *)faceRecognizerWithFile:(NSString *)path;
- (NSString *)predict:(UIImage*)img confidence:(double *)confidence;
- (void)updateWithFace:(UIImage *)img name:(NSString *)name;像下面这样用工厂方法来创建一个 LBPH 实例:
+ (FJFaceRecognizer *)faceRecognizerWithFile:(NSString *)path {
FJFaceRecognizer *fr = [FJFaceRecognizer new];
fr->_faceClassifier = createLBPHFaceRecognizer();
fr->_faceClassifier->load(path.UTF8String);
return fr;
}预测函数可以像下面这样实现:
- (NSString *)predict:(UIImage*)img confidence:(double *)confidence {
cv::Mat src = [img cvMatRepresentationGray];
int label;
self->_faceClassifier->predict(src, label, *confidence);
return _labelsArray[label];
}请注意,我们要使用一个类别方法把 UIImage 转化为 cv::Mat。此转换本身倒是相当简单直接:使用 CGBitmapContextCreate 创建一个指向 cv::Image 中的 data 指针所指向的数据的 CGContextRef。当我们在此图形上下文中绘制此 UIImage 的时候,cv::Image 的 data 指针所指就是所需要的数据。更有趣的是,我们能对一个 Objective-C 类创建一个 Objective-C++ 的类别,并且确实管用。
另外,OpenCV 的人脸识别器仅支持整数标签,但是我们想使用人的名字作标签,所以我们得通过一个 NSArray 属性来对二者实现简单的转换。
一旦识别器给了我们一个识别出来的标签,我们把此标签给用户看,这时候就需要用户给识别器一个反馈。用户可以选择,“是的,识别正确”,也可以选择,“不,这是 Y,不是 X”。在这两种情况下,我们都可以通过人脸图像和正确的标签来更新 LBPH 模型,以提高未来识别的性能。使用用户的反馈来更新人脸识别器的方式如下:
- (void)updateWithFace:(UIImage *)img name:(NSString *)name {
cv::Mat src = [img cvMatRepresentationGray];
NSInteger label = [_labelsArray indexOfObject:name];
if (label == NSNotFound) {
[_labelsArray addObject:name];
label = [_labelsArray indexOfObject:name];
}
vector<cv::Mat> images = vector<cv::Mat>();
images.push_back(src);
vector<int> labels = vector<int>();
labels.push_back((int)label);
self->_faceClassifier->update(images, labels);
}这里,我们又做了一次了从 UIImage 到 cv::Mat、int 到 NSString 标签的转换。我们还得如 OpenCV 的 FaceRecognizer::update API所期望的那样,把我们的参数放到 std::vector 实例中去。
如此“预测,获得反馈,更新循环”,就是文献上所说的监督式学习。
结论
OpenCV 是一个强大而用途广泛的库,覆盖了很多现如今仍在活跃的研究领域。想在一篇文章中给出详细的使用说明只会是让人徒劳的事情。因此,本文仅意在从较高层次对 OpenCV 库做一个概述。同时,还试图就如何集成 OpenCV 库到你的 iOS 工程中给出一些实用建议,并通过一个人脸识别的例子来向你展示如何在一个真正的项目中使用 OpenCV。如果你觉得 OpenCV 对你的项目有用, OpenCV 的官方文档写得非常好非常详细,请继续前行,创造出下一个伟大的 app!