Python并行编程
- 本书说明
- 1 认识并行计算和Python
- 1.1 介绍
- 1.2 并行计算的内存架构
- 1.3 内存管理
- 1.4 并行编程模型
- 1.5 如何设计一个并行程序
- 1.6 如何评估并行程序的性能
- 1.7 介绍Python
- 1.8 并行世界的Python
- 1.9 介绍线程和进程
- 1.10 开始在Python中使用进程
- 1.11 开始在Python中使用线程
- 2 基于线程的并行
- 2.1 介绍
- 2.2 使用Python的线程模块
- 2.3 如何定义一个线程
- 2.4 如何确定当前的线程
- 2.5 如何实现一个线程
- 2.6 使用Lock进行线程同步
- 2.7 使用RLock进行线程同步
- 2.8 使用信号量进行线程同步
- 2.9 使用条件进行线程同步
- 2.10 使用事件进行线程同步
- 2.11 使用with语法
- 2.12 使用 queue 进行线程通信
- 2.13 评估多线程应用的性能
- 3 基于进程的并行
- 3.1 介绍
- 3.2 如何产生一个进程
- 3.3 如何为一个进程命名
- 3.4 如何在后台运行一个进程
- 3.5 如何杀掉一个进程
- 3.6 如何在子类中使用进程
- 3.7 如何在进程之间交换对象
- 3.8 进程如何同步
- 3.9 如何在进程之间管理状态
- 3.10 如何使用进程池
- 3.11 使用Python的mpi4py模块
- 3.12 点对点通讯
- 3.13 避免死锁问题
- 3.14 集体通讯:使用broadcast通讯
- 3.15 集体通讯:使用scatter通讯
- 3.16 集体通讯:使用gather通讯
- 3.17 使用Alltoall通讯
- 3.18 简化操作
- 3.19 如何优化通讯
- 4 异步编程
- 4.1 介绍
- 4.2 使用Python的 concurrent.futures 模块
- 4.3 使用Asyncio管理事件循环
- 4.4 使用Asyncio管理协程
- 4.5 使用Asyncio控制任务
- 4.6 使用Asyncio和Futures
- 5 分布式Python编程
- 5.1 介绍
- 5.2 使用Celery实现分布式任务
- 5.3 如何使用Celery创建任务
- 5.4 使用SCOOP进行科学计算
- 5.5 通过 SCOOP 使用 map 函数
- 5.6 使用Pyro4进行远程方法调用
- 5.7 使用 Pyro4 链接对象
- 5.8 使用Pyro4部署客户端-服务器应用
- 5.9 PyCSP和通信顺序进程
- 5.10 使用Disco进行MapReduce
- 5.11 使用RPyC远程调用
- 6 Python GPU编程
评估多线程应用的性能
在本节中,我们将验证GIL的影响,评估多线程应用的性能。前文已经介绍过,GIL是CPython解释器引入的锁,GIL在解释器层面阻止了真正的并行运行。解释器在执行任何线程之前,必须等待当前正在运行的线程释放GIL。事实上,解释器会强迫想要运行的线程必须拿到GIL才能访问解释器的任何资源,例如栈或Python对象等。这也正是GIL的目的------阻止不同的线程并发访问Python对象。这样GIL可以保护解释器的内存,让垃圾回收工作正常。但事实上,这却造成了程序员无法通过并行执行多线程来提高程序的性能。如果我们去掉CPython的GIL,就可以让多线程真正并行执行。GIL并没有影响多处理器并行的线程,只是限制了一个解释器只能有一个线程在运行。
如何做
下面的代码是用来评估多线程应用性能的简单工具。下面的每一个测试都循环调用函数100次,重复执行多次,取速度最快的一次。在
for 循环中,我们调用 non_threaded 和 threaded
函数。同时,我们会不断增加调用次数和线程数来重复执行这个测试。我们会尝试使用1,2,3,4和8线程数来调用线程。在非线程的测试中,我们顺序调用函数与对应线程数一样多的次数。为了保持简单,度量的指标使用Python的内建模块timer。
代码如下: :
from threading import Thread
class threads_object(Thread):
def run(self):
function_to_run()
class nothreads_object(object):
def run(self):
function_to_run()
def non_threaded(num_iter):
funcs = []
for i in range(int(num_iter)):
funcs.append(nothreads_object())
for i in funcs:
i.run()
def threaded(num_threads):
funcs = []
for i in range(int(num_threads)):
funcs.append(threads_object())
for i in funcs:
i.start()
for i in funcs:
i.join()
def function_to_run():
pass
def show_results(func_name, results):
print("%-23s %4.6f seconds" % (func_name, results))
if __name__ == "__main__":
import sys
from timeit import Timer
repeat = 100
number = 1
num_threads = [1, 2, 4, 8]
print('Starting tests')
for i in num_threads:
t = Timer("non_threaded(%s)" % i, "from __main__ import non_threaded")
best_result = min(t.repeat(repeat=repeat, number=number))
show_results("non_threaded (%s iters)" % i, best_result)
t = Timer("threaded(%s)" % i, "from __main__ import threaded")
best_result = min(t.repeat(repeat=repeat, number=number))
show_results("threaded (%s threads)" % i, best_result)
print('Iterations complete')讨论
我们一共进行了四次测试(译者注:原文是three,我怀疑原作者不识数,原文的3个线程数也没有写在代码里),每一次都会使用不同的function进行测试,只要改变
function_to_run() 就可以了。
测试用的机器是 Core 2 Duo CPU -- 2.33Ghz。
第一次测试
在第一次测试中,我们使用了一个简单的空函数: :
def function_to_run():
pass下图展示了我们测试的每个机制的运行速度:
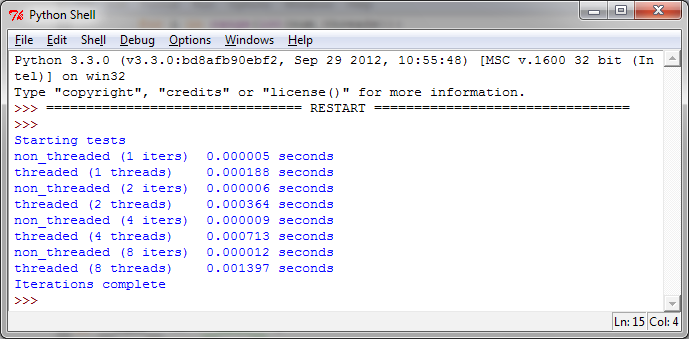
通过结果可以发现,使用线程的开销要比不使用线程的开销大的多。特别的,我们发现随着线程的数量增加,带来的开销是成比例的。4个线程的运行时间是0.0007143秒,8个线程的运行时间是0.001397秒。
第二次测试
| 多线程比较常用的一个用途是处理数字,下面的测试计算斐波那契数列,注意这个例子中没有共享的资源,只是测试生成数字数列: |
|---|
def function_to_run():
a, b = 0, 1
for i in range(10000):
a, b = b, a + b输出如下:
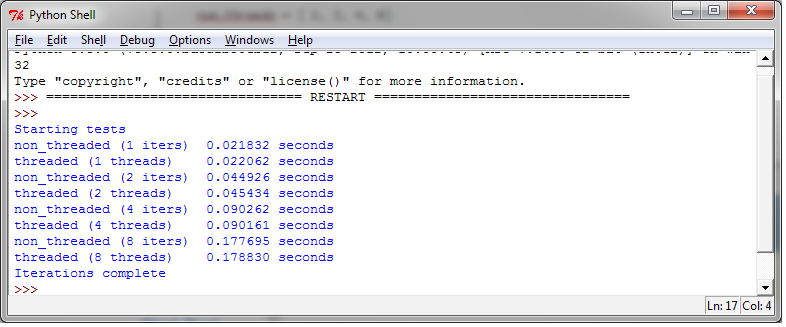
在输出中可以看到,提高线程的数量并没有带来收益。因为GIL和线程管理代码的开销,多线程运行永远不可能比函数顺序执行更快。再次提醒一下:GIL只允许解释器一次执行一个线程。
第三次测试
下面的测试是读1kb的数据1000次,测试用的函数如下: :
def function_to_run():
fh=open("C:\\CookBookFileExamples\\test.dat","rb")
size = 1024
for i in range(1000):
fh.read(size)测试的结果如下:
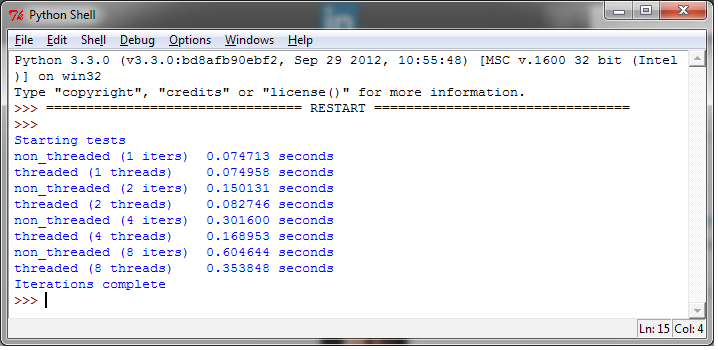
我们终于看到多线程比非多线程跑的好的情况了,而且多线程只用了一半的时间。这给我们的启示是,多线程并不是一个标准。一般,我们将会将多线程放入一个队列中,将它们放到一边,执行其他任务。使用多线程执行同一个相同的任务有时候很有用,但用到的时候很少,除非需要大量处理数据输入。
第四次测试
在最后的测试中,我们使用 urllib.request
测试,这是一个Python模块,可以发送URL请求。此模块基于 socket
,使用C语言编写并且是线程安全的。
下面的代码尝试读取 https://www.packpub.com 的主页并且读取前1k的数据: |
|---|
def function_to_run():
import urllib.request
for i in range(10):
with urllib.request.urlopen("https://www.packtpub.com/")as f:
f.read(1024)运行结果如下:
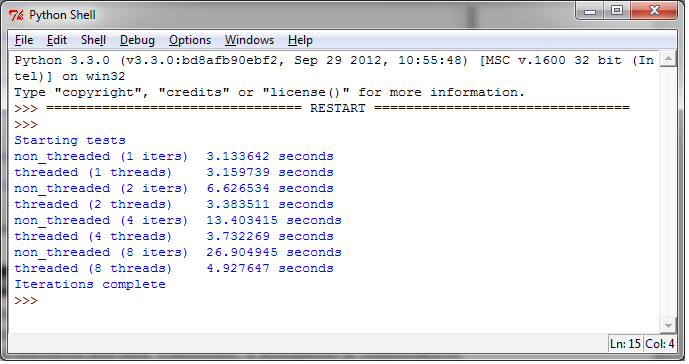
可以看到,在 I/O 期间,GIL释放了。多线程执行比单线程快的多。鉴于大多数应用需要很多I/O操作,GIL并没有限制程序员在这方面使用多线程对程序进行性能优化。
了解更多
你应该记住,增加线程并不会提高应用启动的时间,但是可以支持并发。例如,一次性创建一个线程池,并重用worker会很有用。这可以让我们切分一个大的数据集,用同样的函数处理不同的部分(生产者消费者模型)。上面这些测试并不是并发应用的模型,只是尽量简单的测试。那么GIL会成为试图发挥多线程应用潜能的纯Python开发的瓶颈吗?是的。线程是编程语言的架构,CPython解释器是线程和操作系统的桥梁。这就是为什么Jython,IronPython没有GIL的原因(译者注:Pypy也没有),因为它不是必要的。